When Text Embedding Meets Large Language Model: A Comprehensive Survey
作者: Zhijie Nie, Zhangchi Feng, Mingxin Li, Cunwang Zhang, Yanzhao Zhang, Dingkun Long, Richong Zhang
分类: cs.CL, cs.AI, cs.IR
发布日期: 2024-12-12 (更新: 2025-10-21)
备注: Version 4: We added the latest works of LLM-based Embedders
💡 一句话要点
综述:当文本嵌入遇见大语言模型,探索融合与演进
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本嵌入 大语言模型 自然语言处理 语义匹配 信息检索
📋 核心要点
- 现有文本嵌入方法在处理复杂语义和上下文信息方面存在不足,难以满足日益增长的NLP应用需求。
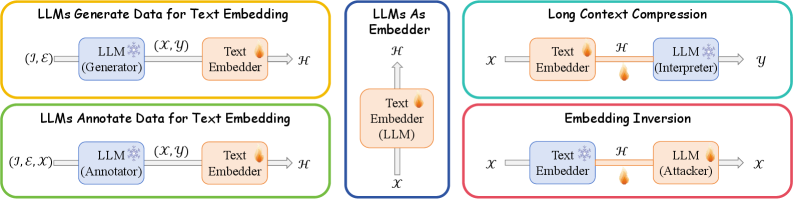
- 该综述系统地梳理了LLM与文本嵌入的融合方式,包括LLM增强嵌入、LLM作为嵌入器以及LLM辅助理解嵌入。
- 通过分析现有研究,该综述指出了LLM时代文本嵌入面临的挑战和机遇,并展望了未来的发展方向。
📝 摘要(中文)
文本嵌入已成为深度学习时代自然语言处理(NLP)的基础技术,推动了各种下游任务的进步。虽然许多自然语言理解挑战现在可以使用生成范式建模,并利用大型语言模型(LLM)强大的生成和理解能力,但许多实际应用(如语义匹配、聚类和信息检索)仍然依赖于文本嵌入的效率和有效性。因此,将LLM与文本嵌入集成已成为近年来的主要研究重点。本综述将LLM与文本嵌入之间的相互作用分为三个主题:(1) LLM增强文本嵌入,利用LLM增强传统嵌入方法;(2) LLM作为文本嵌入器,调整其内在能力以获得高质量的嵌入;(3) 利用LLM理解文本嵌入,分析和解释嵌入。通过基于交互模式而非特定下游应用组织最近的工作,我们对LLM时代各个研究和应用领域的贡献提供了一个新颖而系统的概述。此外,我们强调了预训练语言模型(PLM)时代遗留的未解决的挑战,并探讨了LLM带来的新障碍。在此分析的基础上,我们概述了文本嵌入的发展前景,解决了快速发展的NLP领域中的理论和实践机遇。
🔬 方法详解
问题定义:文本嵌入是NLP中的一项核心技术,广泛应用于语义匹配、聚类和信息检索等任务。然而,传统的文本嵌入方法难以捕捉复杂的语义信息,并且在处理长文本时效率较低。随着大型语言模型(LLM)的兴起,如何有效地将LLM与文本嵌入相结合,以提升嵌入质量和效率,成为了一个重要的研究问题。
核心思路:本综述的核心思路是将LLM与文本嵌入的交互方式分为三个主要类别:LLM增强文本嵌入、LLM作为文本嵌入器以及LLM辅助理解文本嵌入。通过这种分类方式,可以系统地分析现有研究,并揭示LLM在文本嵌入领域中的作用和影响。这种分类方法有助于研究人员更好地理解LLM与文本嵌入之间的关系,并为未来的研究提供指导。
技术框架:该综述没有提出新的技术框架,而是对现有研究进行了系统性的梳理和总结。它将LLM与文本嵌入的交互方式分为三个主要类别,并对每个类别下的代表性工作进行了详细的介绍和分析。此外,该综述还讨论了LLM时代文本嵌入面临的挑战和机遇,并展望了未来的发展方向。
关键创新:该综述的创新之处在于其分类方法,即LLM增强文本嵌入、LLM作为文本嵌入器以及LLM辅助理解文本嵌入。这种分类方法能够清晰地展示LLM在文本嵌入领域中的作用和影响,并为研究人员提供了一个新的视角来思考LLM与文本嵌入之间的关系。
关键设计:该综述没有涉及具体的技术细节,而是侧重于对现有研究进行梳理和总结。它对每个类别下的代表性工作进行了详细的介绍和分析,并讨论了LLM时代文本嵌入面临的挑战和机遇。该综述旨在为研究人员提供一个全面的视角,帮助他们更好地理解LLM与文本嵌入之间的关系,并为未来的研究提供指导。
🖼️ 关键图片
📊 实验亮点
该综述系统地梳理了LLM与文本嵌入的融合方法,并指出了现有方法的局限性以及未来研究方向。它强调了LLM在增强文本嵌入、作为文本嵌入器以及辅助理解文本嵌入方面的潜力,为研究人员提供了宝贵的参考。
🎯 应用场景
该研究对自然语言处理领域具有广泛的应用价值,尤其是在语义搜索、推荐系统、文本聚类、信息检索等领域。通过结合LLM和文本嵌入,可以显著提升这些应用的性能和效率。未来的研究可以进一步探索如何更好地利用LLM来增强文本嵌入,从而推动NLP技术的进步。
📄 摘要(原文)
Text embedding has become a foundational technology in natural language processing (NLP) during the deep learning era, driving advancements across a wide array of downstream tasks. While many natural language understanding challenges can now be modeled using generative paradigms and leverage the robust generative and comprehension capabilities of large language models (LLMs), numerous practical applications - such as semantic matching, clustering, and information retrieval - continue to rely on text embeddings for their efficiency and effectiveness. Therefore, integrating LLMs with text embeddings has become a major research focus in recent years. In this survey, we categorize the interplay between LLMs and text embeddings into three overarching themes: (1) LLM-augmented text embedding, enhancing traditional embedding methods with LLMs; (2) LLMs as text embedders, adapting their innate capabilities for high-quality embedding; and (3) Text embedding understanding with LLMs, leveraging LLMs to analyze and interpret embeddings. By organizing recent works based on interaction patterns rather than specific downstream applications, we offer a novel and systematic overview of contributions from various research and application domains in the era of LLMs. Furthermore, we highlight the unresolved challenges that persisted in the pre-LLM era with pre-trained language models (PLMs) and explore the emerging obstacles brought forth by LLMs. Building on this analysis, we outline prospective directions for the evolution of text embedding, addressing both theoretical and practical opportunities in the rapidly advancing landscape of NLP.