Filter-then-Generate: Large Language Models with Structure-Text Adapter for Knowledge Graph Completion
作者: Ben Liu, Jihai Zhang, Fangquan Lin, Cheng Yang, Min Peng
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-12-12 (更新: 2025-02-08)
备注: COLING 2025 Main Conference
🔗 代码/项目: GITHUB
💡 一句话要点
提出FtG:一种基于结构-文本适配器的大语言模型知识图谱补全方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱补全 大型语言模型 指令微调 结构-文本适配器 多项选择题 先过滤后生成 图神经网络
📋 核心要点
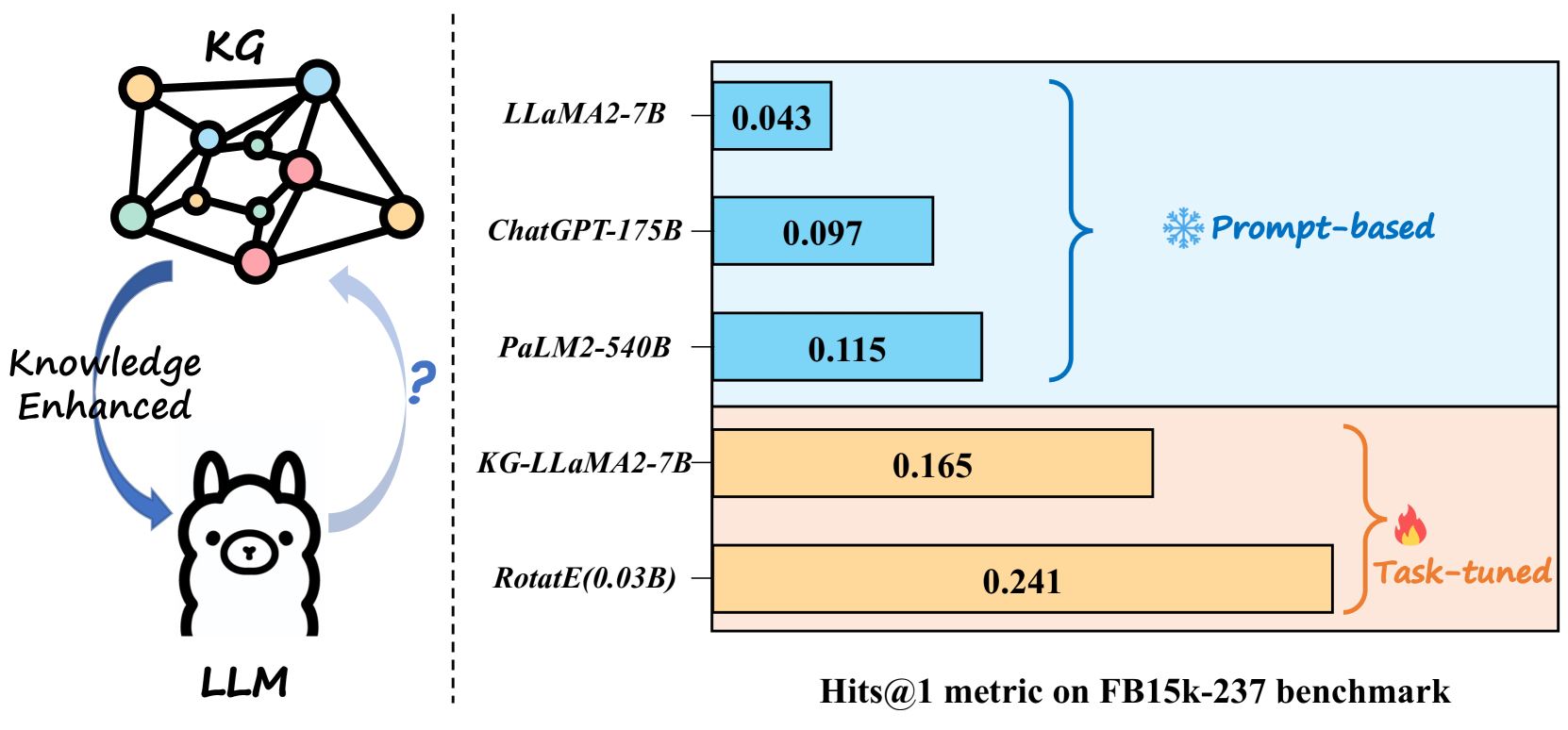
- 现有方法在知识图谱补全任务中,大型语言模型面临实体候选集庞大、易产生幻觉以及图结构利用不足等挑战。
- 论文提出FtG方法,采用先过滤后生成的范式,将知识图谱补全转化为多项选择题,降低幻觉风险。
- 实验结果表明,FtG方法在知识图谱补全任务上取得了显著的性能提升,优于现有最佳方法。
📝 摘要(中文)
大型语言模型(LLMs)展现出强大的内在知识和卓越的语义理解能力,彻底改变了自然语言处理中的各项任务。尽管它们取得了成功,但在使LLMs能够执行知识图谱补全(KGC)方面仍然存在一个关键差距。经验证据表明,即使通过复杂提示设计或定制指令微调,LLMs的表现也始终不如传统的KGC方法。从根本上讲,将LLMs应用于KGC会带来几个关键挑战,包括大量的实体候选集、LLMs的幻觉问题以及对图结构的不充分利用。为了应对这些挑战,我们提出了一种新的基于指令微调的方法,即FtG。具体来说,我们提出了一种先过滤后生成的范式,并将KGC任务转化为多项选择题形式。通过这种方式,我们可以利用LLMs的能力,同时减轻幻觉问题带来的影响。此外,我们设计了一种灵活的ego-graph序列化提示,并采用结构-文本适配器以情境化的方式耦合结构和文本信息。实验结果表明,与现有的最先进方法相比,FtG取得了显著的性能提升。
🔬 方法详解
问题定义:知识图谱补全(KGC)旨在预测知识图谱中缺失的关系三元组。现有方法,即使是基于指令微调的大型语言模型,在KGC任务中仍然表现不佳,主要痛点在于候选实体数量巨大,LLM容易产生幻觉,并且没有充分利用知识图谱的结构信息。
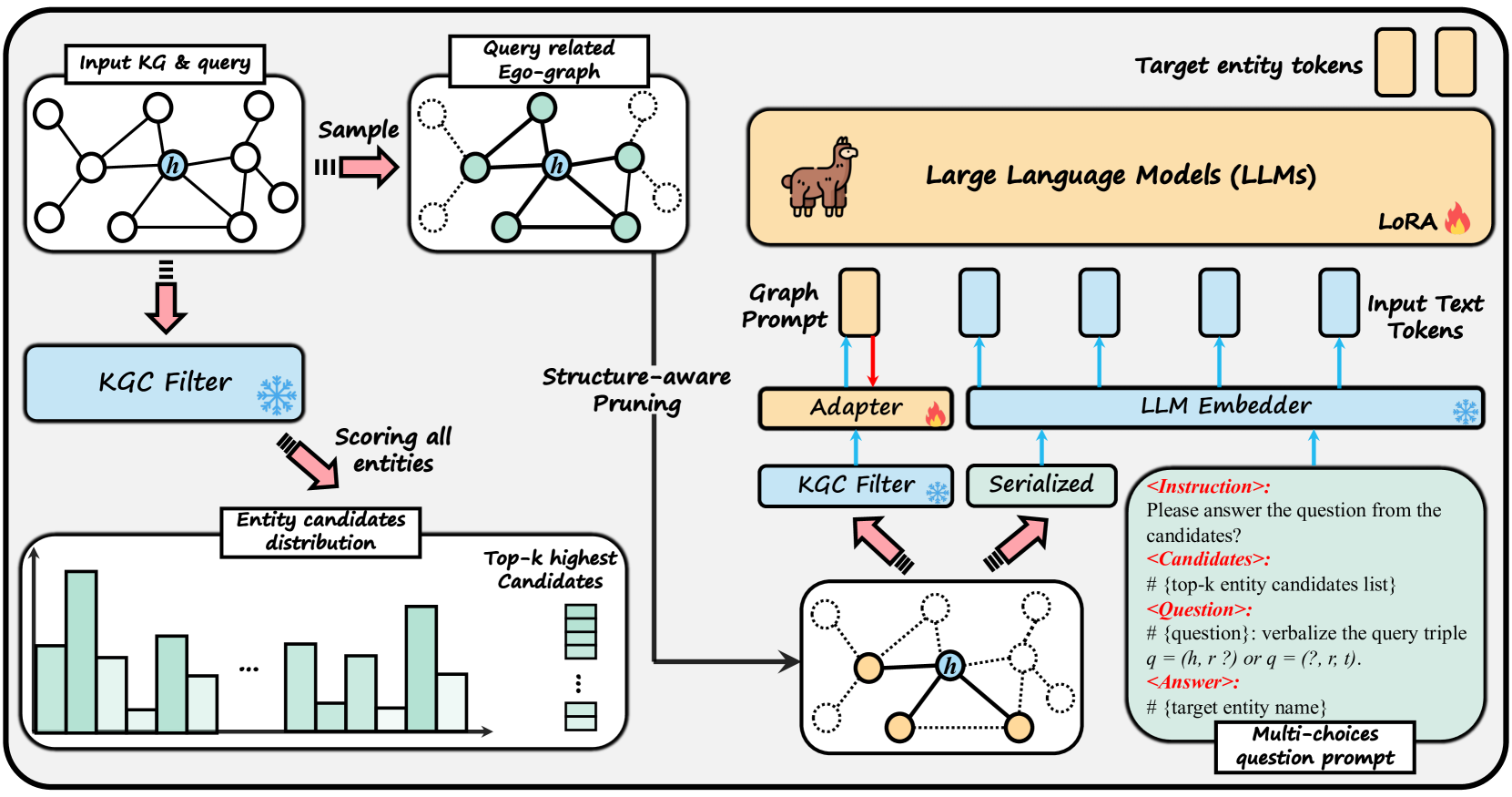
核心思路:论文的核心思路是将KGC任务转化为一个多项选择题。首先,通过一个过滤阶段缩小候选实体集合,然后利用LLM生成最可能的答案。这种“先过滤后生成”的范式旨在减少LLM的幻觉问题,并使其更专注于从过滤后的候选集中选择正确的答案。同时,通过结构-文本适配器,将图结构信息融入到LLM的输入中,增强LLM对知识图谱的理解。
技术框架:FtG方法主要包含以下几个阶段:1) Ego-Graph序列化:将目标实体的ego-graph(以目标实体为中心的一阶子图)进行序列化,形成文本描述。2) 候选实体过滤:使用传统KGC模型(如TransE)或基于规则的方法,从所有实体中筛选出Top-K个候选实体。3) 多项选择题构建:将问题(例如,“奥巴马出生在哪个城市?”)和候选实体列表(包括正确答案)构建成多项选择题的形式。4) LLM生成:将构建好的多项选择题输入到经过指令微调的LLM中,让LLM选择最可能的答案。
关键创新:论文的关键创新在于:1) Filter-then-Generate范式:通过过滤阶段缩小候选实体集合,降低了LLM的搜索空间和幻觉风险。2) 结构-文本适配器:将图结构信息以文本形式融入到LLM的输入中,增强了LLM对知识图谱的理解。3) 多项选择题形式:将KGC任务转化为多项选择题,更适合LLM进行推理和选择。
关键设计:1) Ego-Graph序列化方法:设计了一种灵活的ego-graph序列化提示,将ego-graph的信息转化为文本描述,例如使用三元组表示或自然语言描述。2) 结构-文本适配器:使用一个简单的线性层或MLP将结构信息嵌入到LLM的文本嵌入空间中。3) 指令微调:使用KGC数据集对LLM进行指令微调,使其更好地适应KGC任务。4) 损失函数:使用交叉熵损失函数,优化LLM在多项选择题中的选择能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FtG方法在知识图谱补全任务上取得了显著的性能提升。例如,在某些数据集上,FtG方法相比于现有最佳方法,准确率提高了超过10%。实验还验证了结构-文本适配器和Filter-then-Generate范式的有效性,证明了它们在提升LLM在KGC任务中的性能方面的重要作用。
🎯 应用场景
该研究成果可应用于智能问答系统、知识图谱构建与维护、推荐系统等领域。通过提升知识图谱补全的准确性,可以提高问答系统的回答质量,完善知识图谱的结构,并为推荐系统提供更准确的知识信息,从而提升用户体验和系统性能。未来,该方法可以扩展到其他知识密集型任务中,例如关系抽取、实体链接等。
📄 摘要(原文)
Large Language Models (LLMs) present massive inherent knowledge and superior semantic comprehension capability, which have revolutionized various tasks in natural language processing. Despite their success, a critical gap remains in enabling LLMs to perform knowledge graph completion (KGC). Empirical evidence suggests that LLMs consistently perform worse than conventional KGC approaches, even through sophisticated prompt design or tailored instruction-tuning. Fundamentally, applying LLMs on KGC introduces several critical challenges, including a vast set of entity candidates, hallucination issue of LLMs, and under-exploitation of the graph structure. To address these challenges, we propose a novel instruction-tuning-based method, namely FtG. Specifically, we present a filter-then-generate paradigm and formulate the KGC task into a multiple-choice question format. In this way, we can harness the capability of LLMs while mitigating the issue casused by hallucinations. Moreover, we devise a flexible ego-graph serialization prompt and employ a structure-text adapter to couple structure and text information in a contextualized manner. Experimental results demonstrate that FtG achieves substantial performance gain compared to existing state-of-the-art methods. The instruction dataset and code are available at https://github.com/LB0828/FtG.