RuleArena: A Benchmark for Rule-Guided Reasoning with LLMs in Real-World Scenarios
作者: Ruiwen Zhou, Wenyue Hua, Liangming Pan, Sitao Cheng, Xiaobao Wu, En Yu, William Yang Wang
分类: cs.CL, cs.AI
发布日期: 2024-12-12 (更新: 2025-05-30)
备注: ACL 2025 Main Conference
🔗 代码/项目: GITHUB
💡 一句话要点
RuleArena:一个评估LLM在真实场景中规则引导推理能力的新基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 规则推理 大型语言模型 基准测试 真实场景 逻辑推理 数学计算 自然语言理解
📋 核心要点
- 现有规则推理基准难以模拟真实世界的复杂规则和场景,限制了LLM在实际应用中的评估。
- RuleArena通过构建包含复杂规则和真实场景的数据集,评估LLM在长文本理解、逻辑推理和数学计算方面的能力。
- 实验表明,LLM在识别和应用规则、执行精确计算方面存在不足,但借助外部工具可显著提升性能。
📝 摘要(中文)
本文提出了RuleArena,一个新颖且具有挑战性的基准,旨在评估大型语言模型(LLM)在推理中遵循复杂、真实世界规则的能力。RuleArena涵盖了三个实际领域——航空公司行李费用、NBA交易和税收法规,评估LLM在处理需要长上下文理解、逻辑推理和精确数学计算的复杂自然语言指令方面的能力。RuleArena与传统的基于规则的推理基准的区别在于:(1)它超越了标准的一阶逻辑表示,(2)它基于真实的实际场景,提供了LLM在实际应用中的适用性和可靠性的见解。研究结果揭示了LLM的几个显著局限性:(1)它们难以识别和应用适当的规则,经常被相似但不同的规则混淆,(2)即使它们正确识别了相关规则,也无法始终如一地执行准确的数学计算,(3)总的来说,它们在该基准测试中表现不佳。我们还观察到,当为LLM提供用于oracle数学和逻辑运算的外部工具时,性能会显著提高。这些结果突出了在推进LLM在实际应用中基于规则的推理能力方面存在的重大挑战和有希望的研究方向。我们的代码和数据可在https://github.com/skyriver-2000/RuleArena上公开获取。
🔬 方法详解
问题定义:现有基于规则的推理基准通常使用简化的一阶逻辑表示,无法充分模拟真实世界规则的复杂性和模糊性。此外,这些基准缺乏实际应用场景,难以评估LLM在真实环境中的适用性。因此,需要一个更具挑战性和现实性的基准来评估LLM在规则引导推理方面的能力。
核心思路:RuleArena的核心思路是构建一个基于真实世界场景的数据集,其中包含复杂的自然语言规则,这些规则需要长上下文理解、逻辑推理和精确的数学计算才能正确应用。通过评估LLM在这些场景中的表现,可以更全面地了解其在实际应用中的能力和局限性。
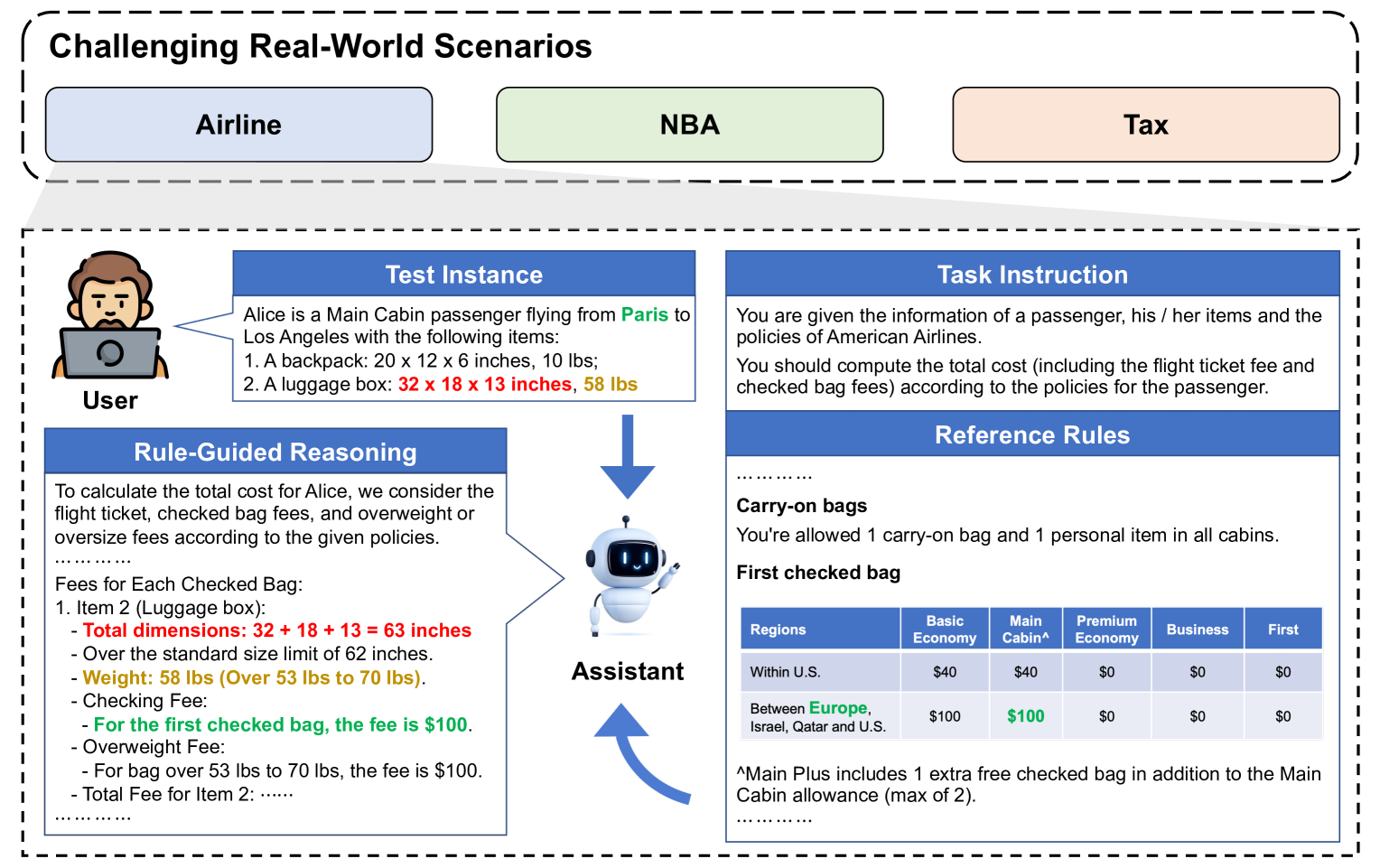
技术框架:RuleArena包含三个主要领域:航空公司行李费用、NBA交易和税收法规。每个领域都包含一组复杂的自然语言规则和相应的推理问题。LLM需要根据给定的规则和问题,进行推理并给出答案。评估指标包括规则识别的准确率、数学计算的准确率以及最终答案的正确率。
关键创新:RuleArena的关键创新在于其真实性和复杂性。与传统的基于规则的推理基准相比,RuleArena的规则更加复杂,更接近真实世界的规则。此外,RuleArena的场景也更加真实,更能够反映LLM在实际应用中的表现。另一个创新是,该基准允许使用外部工具(例如数学计算器)来辅助LLM进行推理,从而可以更清晰地评估LLM的推理能力本身,而不会受到其数学计算能力的限制。
关键设计:RuleArena的数据集包含大量的训练和测试样本,每个样本都包含一段描述规则的自然语言文本和一个需要根据规则进行推理的问题。规则的复杂性各不相同,有些规则需要简单的逻辑推理,而另一些规则则需要复杂的数学计算。为了评估LLM的性能,使用了多种评估指标,包括规则识别的准确率、数学计算的准确率以及最终答案的正确率。此外,还评估了LLM在使用外部工具时的性能提升。
🖼️ 关键图片

📊 实验亮点
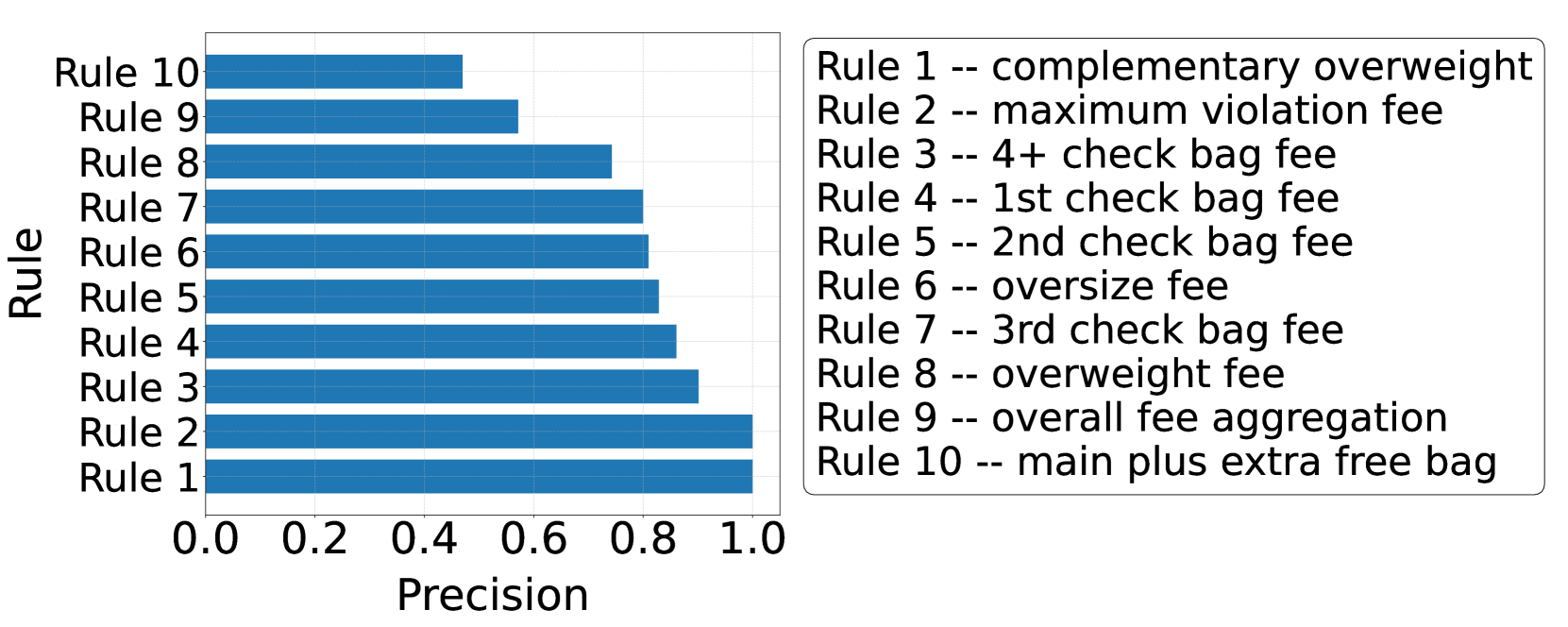
实验结果表明,LLM在RuleArena基准上的表现不佳,尤其是在规则识别和数学计算方面。即使是强大的LLM,也难以正确识别和应用复杂的规则。然而,当LLM被赋予使用外部数学计算工具的能力时,其性能得到了显著提升,这表明LLM的推理能力受到其数学计算能力的限制。例如,使用外部工具后,整体准确率平均提升了15%-20%(具体提升幅度未知)。
🎯 应用场景
RuleArena的研究成果可应用于评估和改进LLM在需要规则引导推理的实际应用中的性能,例如智能客服、法律咨询、金融分析等领域。通过提高LLM在这些领域的推理能力,可以提高自动化决策的准确性和可靠性,从而降低人工成本并提高效率。此外,该基准还可以促进对LLM推理机制的深入研究,推动人工智能技术的发展。
📄 摘要(原文)
This paper introduces RuleArena, a novel and challenging benchmark designed to evaluate the ability of large language models (LLMs) to follow complex, real-world rules in reasoning. Covering three practical domains -- airline baggage fees, NBA transactions, and tax regulations -- RuleArena assesses LLMs' proficiency in handling intricate natural language instructions that demand long-context understanding, logical reasoning, and accurate mathematical computation. Two key attributes distinguish RuleArena from traditional rule-based reasoning benchmarks: (1) it extends beyond standard first-order logic representations, and (2) it is grounded in authentic, practical scenarios, providing insights into the suitability and reliability of LLMs for real-world applications. Our findings reveal several notable limitations in LLMs: (1) they struggle to identify and apply the appropriate rules, frequently becoming confused by similar but distinct regulations, (2) they cannot consistently perform accurate mathematical computations, even when they correctly identify the relevant rules, and (3) in general, they perform poorly in the benchmark. We also observe a significant performance boost when LLMs are provided with external tools for oracle math and logic operations. These results highlight significant challenges and promising research directions in advancing LLMs' rule-guided reasoning capabilities in real-life applications. Our codes and data are publicly available on https://github.com/skyriver-2000/RuleArena.