Rethinking Comprehensive Benchmark for Chart Understanding: A Perspective from Scientific Literature
作者: Lingdong Shen, Qigqi, Kun Ding, Gaofeng Meng, Shiming Xiang
分类: cs.CL, cs.CV, cs.LG
发布日期: 2024-12-11
💡 一句话要点
提出SCI-CQA基准,用于更全面评估多模态模型在科学文献图表理解方面的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图表理解 科学文献 多模态学习 问答系统 基准测试
📋 核心要点
- 现有图表理解基准在图表类型、问题设计和评估方法上存在局限性,导致模型在真实科学图表上表现不佳。
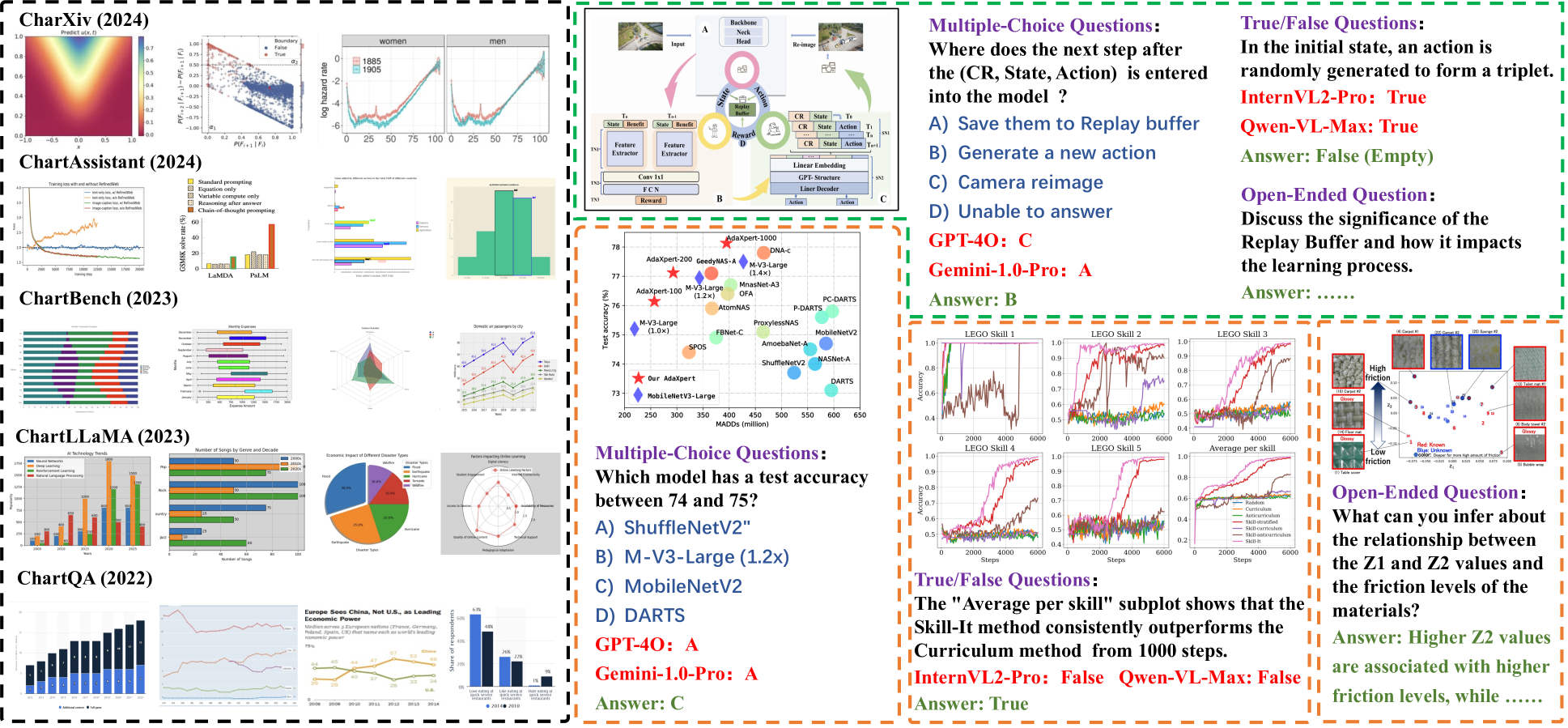
- SCI-CQA基准侧重于科学文献中的复杂图表,特别是流程图,并引入了更贴近人类考试的评估框架。
- 该研究构建了一个包含37,607个高质量图表的数据集,并探索了上下文信息在图表理解中的重要作用。
📝 摘要(中文)
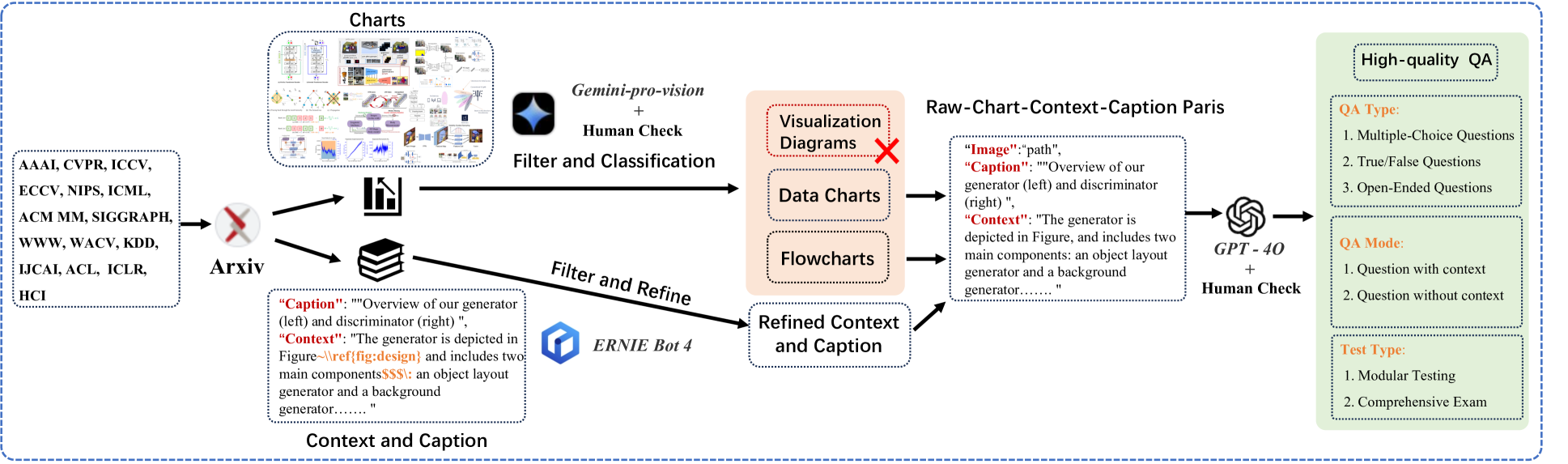
科学文献图表通常包含复杂的可视元素,包括多图、流程图和结构图等。使用这些真实且复杂的图表评估多模态模型,可以更准确地评估其理解能力。然而,现有基准存在局限性:图表类型范围窄、基于模板的问题和视觉元素过于简单、评估方法不足。这些缺点导致模型在遇到真实科学图表时,性能得分虚高。为了解决这些挑战,我们引入了一个新的基准,即科学图表问答(SCI-CQA),它强调流程图这一关键但经常被忽视的类别。为了克服图表种类和简单视觉元素的限制,我们从过去十年中15个顶级计算机科学会议论文中整理了一个包含202,760个图像-文本对的数据集。经过严格的过滤,我们将其提炼为37,607个高质量的带有上下文信息的图表。SCI-CQA还引入了一个受人类考试启发的新的评估框架,包含5,629个精心策划的问题,包括客观题和开放题。此外,我们提出了一种高效的标注流程,可显著降低数据标注成本。最后,我们探索了基于上下文的图表理解,突出了上下文信息在解决以前无法回答的问题中的关键作用。
🔬 方法详解
问题定义:现有图表理解方法和基准测试集,无法有效评估模型在理解复杂科学文献图表方面的能力。现有基准图表类型单一,问题设计过于简单,评估方法不够全面,导致模型在真实场景下的泛化能力不足。特别是,流程图作为科学文献中常见的图表类型,在现有基准中被严重忽略。
核心思路:该论文的核心思路是构建一个更全面、更贴近真实场景的科学图表理解基准测试集SCI-CQA。通过收集大量真实的科学文献图表,设计更具挑战性的问题,并引入基于上下文的评估方法,从而更准确地评估多模态模型在理解复杂图表方面的能力。
技术框架:SCI-CQA的构建主要包含以下几个阶段:1) 数据收集:从15个顶级计算机科学会议论文中收集包含图表的图像-文本对。2) 数据过滤:通过严格的过滤规则,筛选出高质量的图表数据。3) 问题生成:设计客观题和开放题,并采用高效的标注流程降低标注成本。4) 评估框架:构建基于人类考试的评估框架,并探索上下文信息在图表理解中的作用。
关键创新:该论文的关键创新点在于:1) 构建了一个包含大量真实科学文献图表的数据集,特别是强调了流程图的重要性。2) 提出了一个更贴近人类考试的评估框架,包含客观题和开放题,能够更全面地评估模型的理解能力。3) 探索了上下文信息在图表理解中的作用,并证明了上下文信息对于解决以前无法回答的问题至关重要。
关键设计:在数据过滤阶段,采用了多种规则来保证图表的质量,例如去除模糊图像、重复图像等。在问题生成阶段,采用了高效的标注流程,例如众包标注、专家审核等,以降低标注成本并保证标注质量。在评估框架中,设计了多种类型的客观题和开放题,以全面评估模型的理解能力。此外,还设计了实验来验证上下文信息对于图表理解的重要性。
🖼️ 关键图片

📊 实验亮点
SCI-CQA数据集包含37,607个高质量图表和5,629个精心策划的问题,涵盖客观题和开放题。实验结果表明,现有模型在SCI-CQA上的表现远低于人类水平,突显了该基准的挑战性。此外,研究还证明了上下文信息对于解决以前无法回答的问题至关重要,表明了上下文感知图表理解的潜力。
🎯 应用场景
该研究成果可应用于智能文档处理、科学文献挖掘、教育辅助等领域。通过提高机器对科学图表的理解能力,可以帮助研究人员更高效地获取和利用科学知识,并为自动化科研流程提供支持。未来,该基准可以促进多模态模型在科学领域的应用,例如自动生成研究报告、辅助科研教学等。
📄 摘要(原文)
Scientific Literature charts often contain complex visual elements, including multi-plot figures, flowcharts, structural diagrams and etc. Evaluating multimodal models using these authentic and intricate charts provides a more accurate assessment of their understanding abilities. However, existing benchmarks face limitations: a narrow range of chart types, overly simplistic template-based questions and visual elements, and inadequate evaluation methods. These shortcomings lead to inflated performance scores that fail to hold up when models encounter real-world scientific charts. To address these challenges, we introduce a new benchmark, Scientific Chart QA (SCI-CQA), which emphasizes flowcharts as a critical yet often overlooked category. To overcome the limitations of chart variety and simplistic visual elements, we curated a dataset of 202,760 image-text pairs from 15 top-tier computer science conferences papers over the past decade. After rigorous filtering, we refined this to 37,607 high-quality charts with contextual information. SCI-CQA also introduces a novel evaluation framework inspired by human exams, encompassing 5,629 carefully curated questions, both objective and open-ended. Additionally, we propose an efficient annotation pipeline that significantly reduces data annotation costs. Finally, we explore context-based chart understanding, highlighting the crucial role of contextual information in solving previously unanswerable questions.