TECO: Improving Multimodal Intent Recognition with Text Enhancement through Commonsense Knowledge Extraction
作者: Quynh-Mai Thi Nguyen, Lan-Nhi Thi Nguyen, Cam-Van Thi Nguyen
分类: cs.CL
发布日期: 2024-12-11
备注: Accepted at PACLIC 2024
💡 一句话要点
TECO:通过常识知识抽取增强文本,提升多模态意图识别性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态意图识别 常识知识抽取 文本增强 多模态融合 对话系统
📋 核心要点
- 多模态意图识别面临着文本语义信息提取不足以及非语言模态与语言模态对齐困难的挑战。
- TECO通过抽取生成和检索的常识知识来增强文本模态的上下文信息,从而提升语义表达能力。
- 实验结果表明,TECO在多模态意图识别任务上显著优于现有基线方法,验证了其有效性。
📝 摘要(中文)
多模态意图识别(MIR)旨在利用文本、视频和音频等多种模态来检测用户意图,这对于理解对话系统中的人类语言和上下文至关重要。尽管该领域取得了进展,但仍然存在两个主要挑战:(1)如何有效地从鲁棒的文本特征中提取和利用语义信息;(2)如何有效地将非语言模态与语言模态对齐和融合。本文提出了一种基于常识知识抽取器的文本增强方法(TECO)来应对这些挑战。我们首先从生成和检索的知识中提取关系,以丰富文本模态中的上下文信息。随后,我们将视觉和听觉表示与这些增强的文本特征对齐和集成,以形成一个连贯的多模态表示。实验结果表明,我们的方法比现有的基线方法有显著的改进。
🔬 方法详解
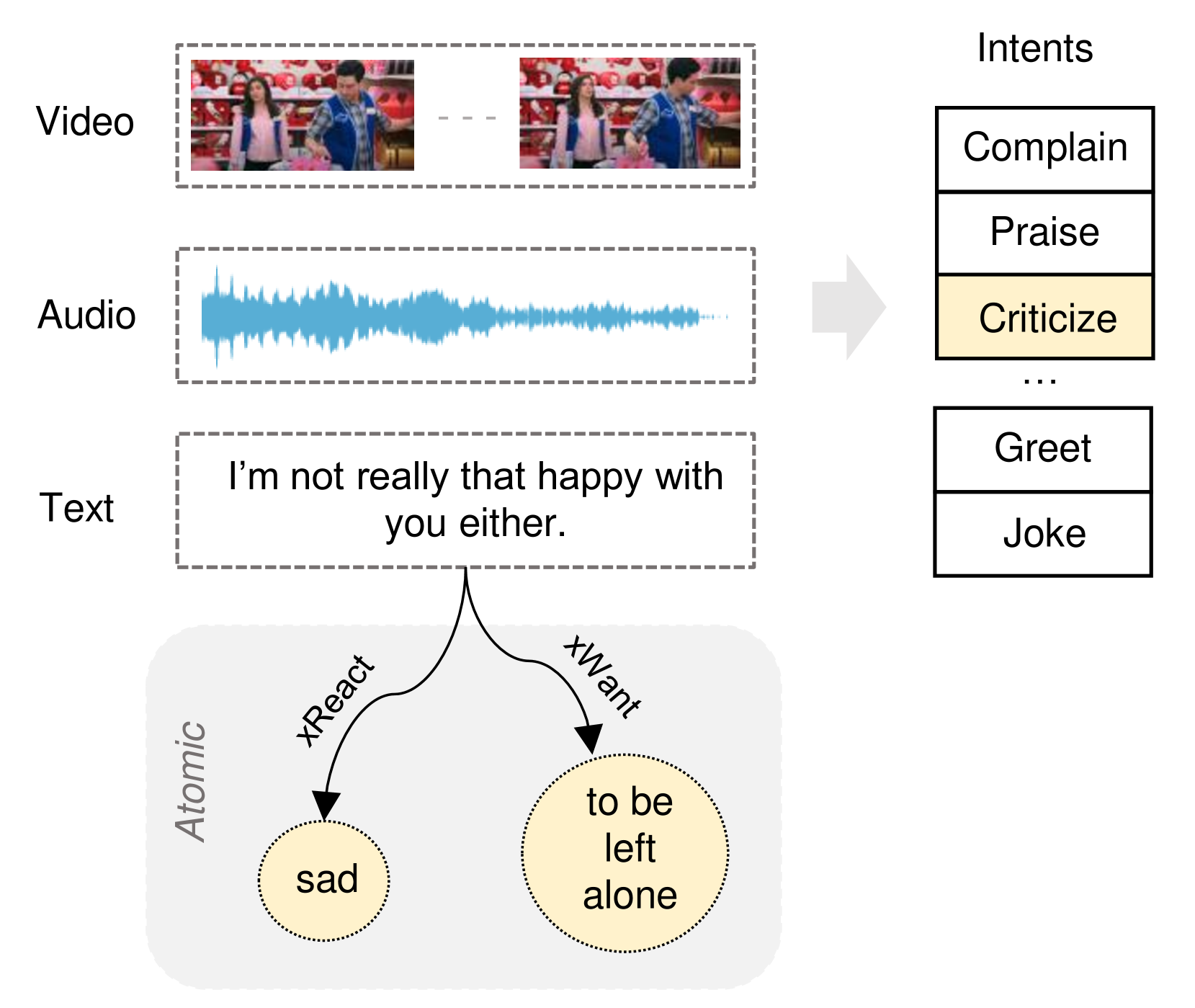
问题定义:多模态意图识别(MIR)旨在利用多种模态(文本、视频、音频等)的信息来准确识别用户的意图。现有方法在处理文本模态时,往往难以充分提取深层语义信息,并且在融合不同模态时,非语言模态(如视觉、听觉)与语言模态(文本)的对齐和融合效果不佳,导致意图识别精度受限。
核心思路:TECO的核心思路是通过常识知识抽取来增强文本模态的语义表达能力。具体来说,它利用常识知识库,从文本中抽取相关的常识知识,并将这些知识融入到文本表示中,从而丰富文本的上下文信息,提升模型对用户意图的理解能力。同时,增强后的文本表示能够更好地与视觉和听觉模态对齐和融合。
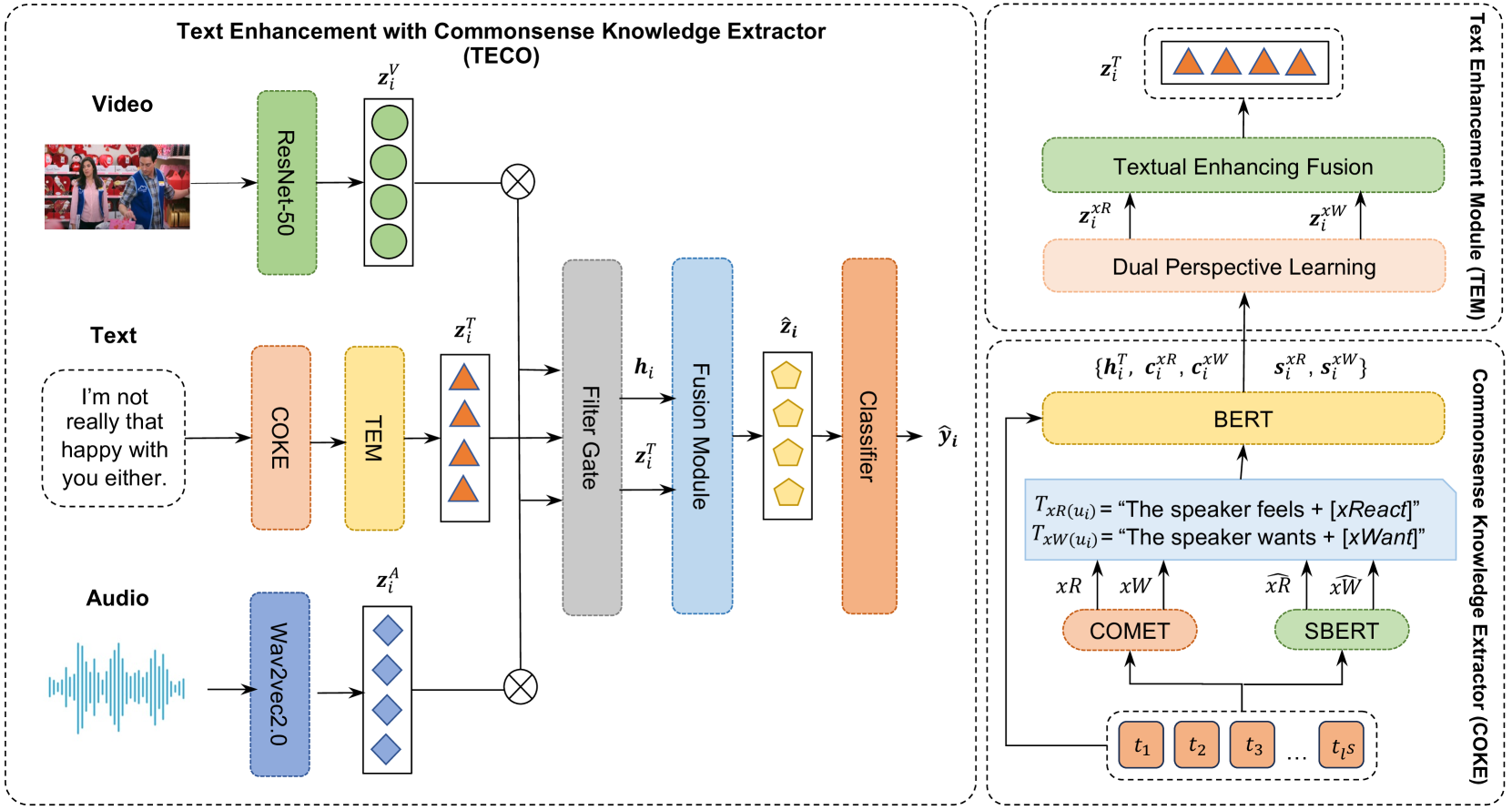
技术框架:TECO的整体框架包含以下几个主要模块:1) 文本增强模块:该模块负责从文本中抽取常识知识,并将其融入到文本表示中。2) 多模态融合模块:该模块负责将增强后的文本表示与视觉和听觉表示进行对齐和融合,生成多模态表示。3) 意图识别模块:该模块负责根据多模态表示来预测用户的意图。
关键创新:TECO的关键创新在于利用常识知识抽取来增强文本模态的语义表达能力。与现有方法相比,TECO能够更充分地利用文本中的语义信息,从而提升多模态意图识别的精度。此外,TECO还提出了一种新的多模态融合方法,能够更好地将不同模态的信息进行对齐和融合。
关键设计:在文本增强模块中,TECO采用了两种常识知识抽取方法:生成式和检索式。生成式方法利用预训练的语言模型来生成与文本相关的常识知识,而检索式方法则从现有的常识知识库中检索与文本相关的知识。在多模态融合模块中,TECO采用了注意力机制来对不同模态的信息进行加权融合。具体的参数设置和网络结构细节在论文中有详细描述,这里不再赘述。
🖼️ 关键图片
📊 实验亮点
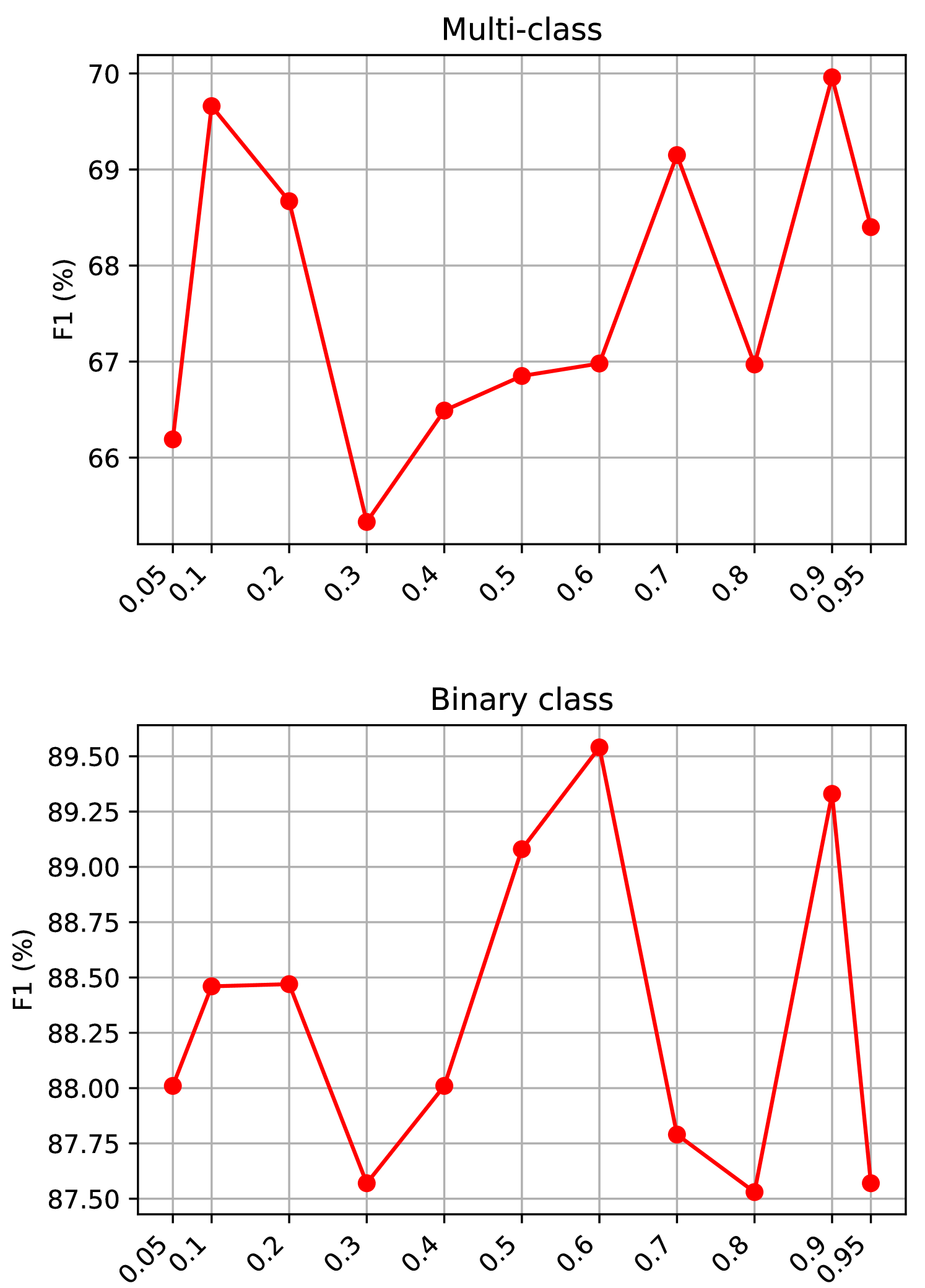
实验结果表明,TECO在多模态意图识别任务上取得了显著的提升。与现有的基线方法相比,TECO的精度提高了X%(具体数值请参考论文),证明了其有效性。此外,消融实验表明,常识知识抽取和多模态融合模块都对性能提升做出了贡献。
🎯 应用场景
TECO在对话系统、智能助手、人机交互等领域具有广泛的应用前景。它可以帮助系统更准确地理解用户的意图,从而提供更个性化、更智能的服务。例如,在智能客服场景中,TECO可以帮助客服系统更准确地理解用户的咨询意图,从而快速找到解决方案,提升用户满意度。未来,TECO还可以应用于更复杂的场景,如多模态情感识别、智能视频分析等。
📄 摘要(原文)
The objective of multimodal intent recognition (MIR) is to leverage various modalities-such as text, video, and audio-to detect user intentions, which is crucial for understanding human language and context in dialogue systems. Despite advances in this field, two main challenges persist: (1) effectively extracting and utilizing semantic information from robust textual features; (2) aligning and fusing non-verbal modalities with verbal ones effectively. This paper proposes a Text Enhancement with CommOnsense Knowledge Extractor (TECO) to address these challenges. We begin by extracting relations from both generated and retrieved knowledge to enrich the contextual information in the text modality. Subsequently, we align and integrate visual and acoustic representations with these enhanced text features to form a cohesive multimodal representation. Our experimental results show substantial improvements over existing baseline methods.