EMS: Adaptive Evict-then-Merge Strategy for Head-wise KV Cache Compression Based on Global-Local Importance
作者: Yingxin Li, Ye Li, Yuan Meng, Xinzhu Ma, Zihan Geng, Shutao Xia, Zhi Wang
分类: cs.CL
发布日期: 2024-12-11 (更新: 2025-02-27)
💡 一句话要点
提出EMS:基于全局-局部重要性的自适应Evict-then-Merge KV缓存压缩策略
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存压缩 大型语言模型 注意力机制 全局-局部重要性 Evict-then-Merge 长上下文处理 模型推理加速
📋 核心要点
- 现有KV缓存压缩方法易受累积注意力或位置编码影响,导致重要token分布偏差。
- EMS提出全局-局部重要性评分,并设计自适应Evict-then-Merge框架,兼顾head间的稀疏性和冗余性。
- 实验表明,EMS在极高压缩率下仍能取得SOTA性能,显著降低困惑度并保持检索准确率。
📝 摘要(中文)
随着大型语言模型(LLMs)的不断发展,各种应用对更高质量和更快处理长上下文的需求日益增长。KV缓存被广泛采用,因为它存储先前生成的键和值token,从而有效减少推理期间的冗余计算。然而,由于内存开销成为一个重要问题,高效的KV缓存压缩越来越受到关注。现有方法主要从两个角度进行压缩:识别重要token和设计压缩策略。然而,这些方法通常由于累积的注意力分数或位置编码的影响而产生有偏差的重要token分布。此外,它们忽略了不同head之间的稀疏性和冗余性,导致难以在head级别保留最有效的信息。为此,我们提出了EMS来克服这些限制,同时在极高的压缩率下实现更好的KV缓存压缩。具体来说,我们引入了一个全局-局部分数,它结合了来自全局和局部KV token的累积注意力分数,以更好地识别token的重要性。对于压缩策略,我们设计了一个自适应和统一的Evict-then-Merge框架,该框架考虑了不同head之间KV token的稀疏性和冗余性。此外,我们通过零类机制实现head-wise并行压缩,以提高效率。大量实验表明,即使在极高的压缩率下,我们的方法也能实现SOTA性能。在256缓存预算下,EMS在LongBench上始终如一地实现了最低的困惑度,并在四个LLM上将分数提高了1.28分以上,并且在Needle-in-a-Haystack任务中,在缓存预算小于上下文长度的2%的情况下,保留了95%的检索准确率。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中KV缓存压缩的问题。现有方法在识别重要token时,容易受到累积注意力分数或位置编码的影响,导致重要token的分布存在偏差。此外,现有方法忽略了不同head之间的KV token的稀疏性和冗余性,难以在head级别保留最有效的信息。这些问题限制了KV缓存压缩的效率和性能。
核心思路:论文的核心思路是结合全局和局部信息来更准确地评估token的重要性,并设计一个自适应的压缩框架来充分利用不同head之间的稀疏性和冗余性。通过引入全局-局部重要性评分,可以更全面地评估token的重要性,减少偏差。通过自适应的Evict-then-Merge框架,可以根据不同head的特性进行定制化的压缩,从而更好地保留有效信息。
技术框架:EMS框架主要包含两个核心模块:全局-局部重要性评分模块和自适应Evict-then-Merge压缩模块。首先,全局-局部重要性评分模块计算每个token的全局和局部注意力分数,并将它们结合起来得到最终的重要性评分。然后,自适应Evict-then-Merge压缩模块根据每个head的重要性评分,先进行Evict操作,移除不重要的token,然后进行Merge操作,将相似的token合并,从而实现KV缓存的压缩。此外,该框架还采用了head-wise并行压缩,以提高压缩效率。
关键创新:论文的关键创新在于提出了全局-局部重要性评分和自适应Evict-then-Merge压缩框架。全局-局部重要性评分结合了全局和局部信息,可以更准确地评估token的重要性,减少了现有方法中存在的偏差。自适应Evict-then-Merge压缩框架可以根据不同head的特性进行定制化的压缩,从而更好地保留有效信息。与现有方法相比,EMS能够更好地处理不同head之间的稀疏性和冗余性,从而在极高的压缩率下实现更好的性能。
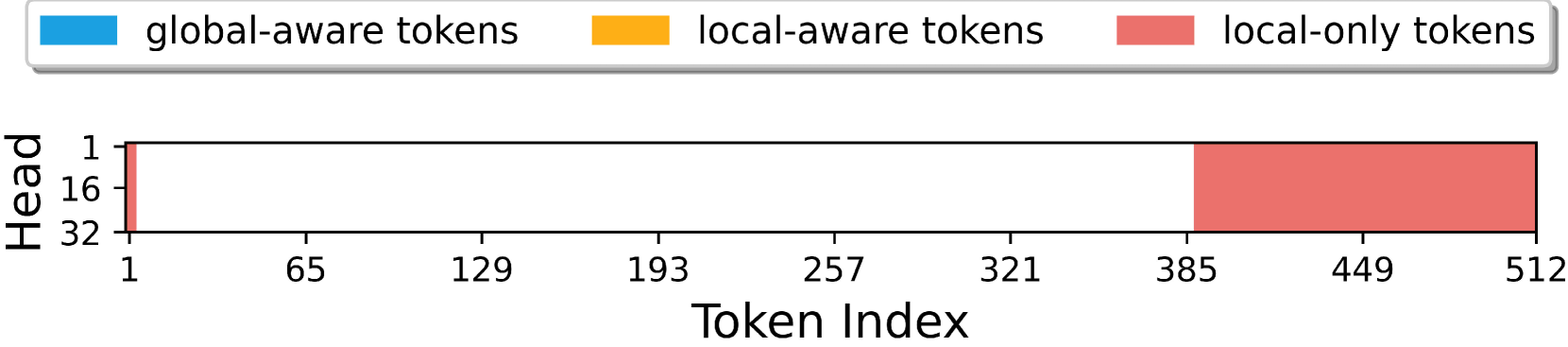
关键设计:全局-局部重要性评分中,全局注意力分数通过累积所有token的注意力权重得到,局部注意力分数通过滑动窗口内的注意力权重得到。自适应Evict-then-Merge压缩框架中,Evict操作根据重要性评分移除一定比例的token,Merge操作使用聚类算法将相似的token合并。Head-wise并行压缩通过引入零类机制,允许不同head并行进行压缩操作。
🖼️ 关键图片


📊 实验亮点
实验结果表明,EMS在极高的压缩率下仍能取得SOTA性能。在LongBench数据集上,EMS在256缓存预算下始终如一地实现了最低的困惑度,并在四个LLM上将分数提高了1.28分以上。在Needle-in-a-Haystack任务中,EMS在缓存预算小于上下文长度的2%的情况下,保留了95%的检索准确率。这些结果表明,EMS能够有效地压缩KV缓存,同时保持较高的性能。
🎯 应用场景
该研究成果可广泛应用于各种需要处理长上下文的大型语言模型应用中,例如长文本生成、对话系统、信息检索等。通过高效的KV缓存压缩,可以显著降低内存开销,提高推理速度,从而支持更大规模的模型和更复杂的应用场景。未来,该技术有望进一步推广到其他类型的模型和任务中,为人工智能的发展做出贡献。
📄 摘要(原文)
As large language models (LLMs) continue to advance, the demand for higher quality and faster processing of long contexts across various applications is growing. KV cache is widely adopted as it stores previously generated key and value tokens, effectively reducing redundant computations during inference. However, as memory overhead becomes a significant concern, efficient compression of KV cache has gained increasing attention. Most existing methods perform compression from two perspectives: identifying important tokens and designing compression strategies. However, these approaches often produce biased distributions of important tokens due to the influence of accumulated attention scores or positional encoding. Furthermore, they overlook the sparsity and redundancy across different heads, which leads to difficulties in preserving the most effective information at the head level. To this end, we propose EMS to overcome these limitations, while achieving better KV cache compression under extreme compression ratios. Specifically, we introduce a Global-Local score that combines accumulated attention scores from both global and local KV tokens to better identify the token importance. For the compression strategy, we design an adaptive and unified Evict-then-Merge framework that accounts for the sparsity and redundancy of KV tokens across different heads. Additionally, we implement the head-wise parallel compression through a zero-class mechanism to enhance efficiency. Extensive experiments demonstrate our SOTA performance even under extreme compression ratios. EMS consistently achieves the lowest perplexity, improves scores by over 1.28 points across four LLMs on LongBench under a 256 cache budget, and preserves 95% retrieval accuracy with a cache budget less than 2% of the context length in the Needle-in-a-Haystack task.