Detecting Conversational Mental Manipulation with Intent-Aware Prompting
作者: Jiayuan Ma, Hongbin Na, Zimu Wang, Yining Hua, Yue Liu, Wei Wang, Ling Chen
分类: cs.CL
发布日期: 2024-12-11
期刊: COLING2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出Intent-Aware Prompting方法,利用LLM检测对话中的精神操控行为
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 精神操控检测 意图感知 大型语言模型 Prompt工程 对话理解
📋 核心要点
- 现有方法难以检测对话中微妙隐蔽的精神操控策略,阻碍了相关研究进展。
- 提出Intent-Aware Prompting方法,通过捕捉对话参与者的潜在意图,提升检测精度。
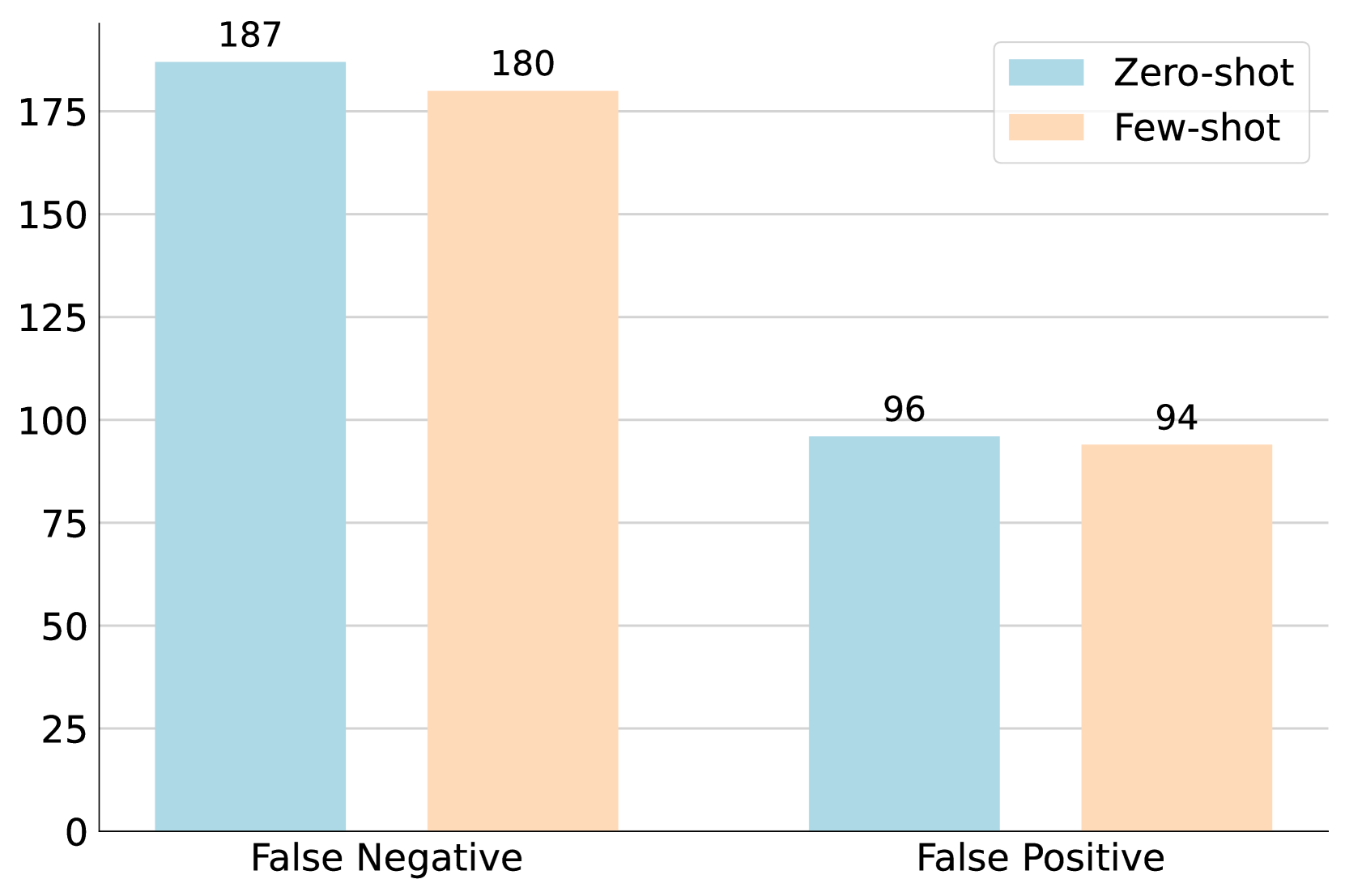
- 实验结果表明,IAP方法能有效减少假阴性,在精神操控检测任务上优于其他prompting策略。
📝 摘要(中文)
精神操控通过隐蔽且负面的方式扭曲决策,严重损害心理健康。尽管自然语言处理领域对心理健康护理的兴趣日益浓厚,但由于检测对话中微妙、隐蔽的策略的复杂性,在解决操控问题方面的进展仍然有限。本文提出了一种新颖的Intent-Aware Prompting (IAP) 方法,利用大型语言模型 (LLM) 检测精神操控,通过捕捉参与者的潜在意图,更深入地理解操控策略。在MentalManip数据集上的实验结果表明,IAP相对于其他先进的prompting策略具有卓越的有效性。值得注意的是,我们的方法大大减少了假阴性,有助于检测更多的精神操控实例,同时最大限度地减少对阳性案例的误判。
🔬 方法详解
问题定义:论文旨在解决对话场景下精神操控行为的自动检测问题。现有方法难以捕捉到操控行为的微妙性和隐蔽性,导致检测精度较低,尤其容易漏检(假阴性)。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大理解和推理能力,结合意图感知的prompting策略,使模型能够更好地理解对话参与者的潜在意图,从而更准确地识别出精神操控行为。通过显式地引导模型关注对话中的意图信息,可以有效提高模型对操控行为的敏感度。
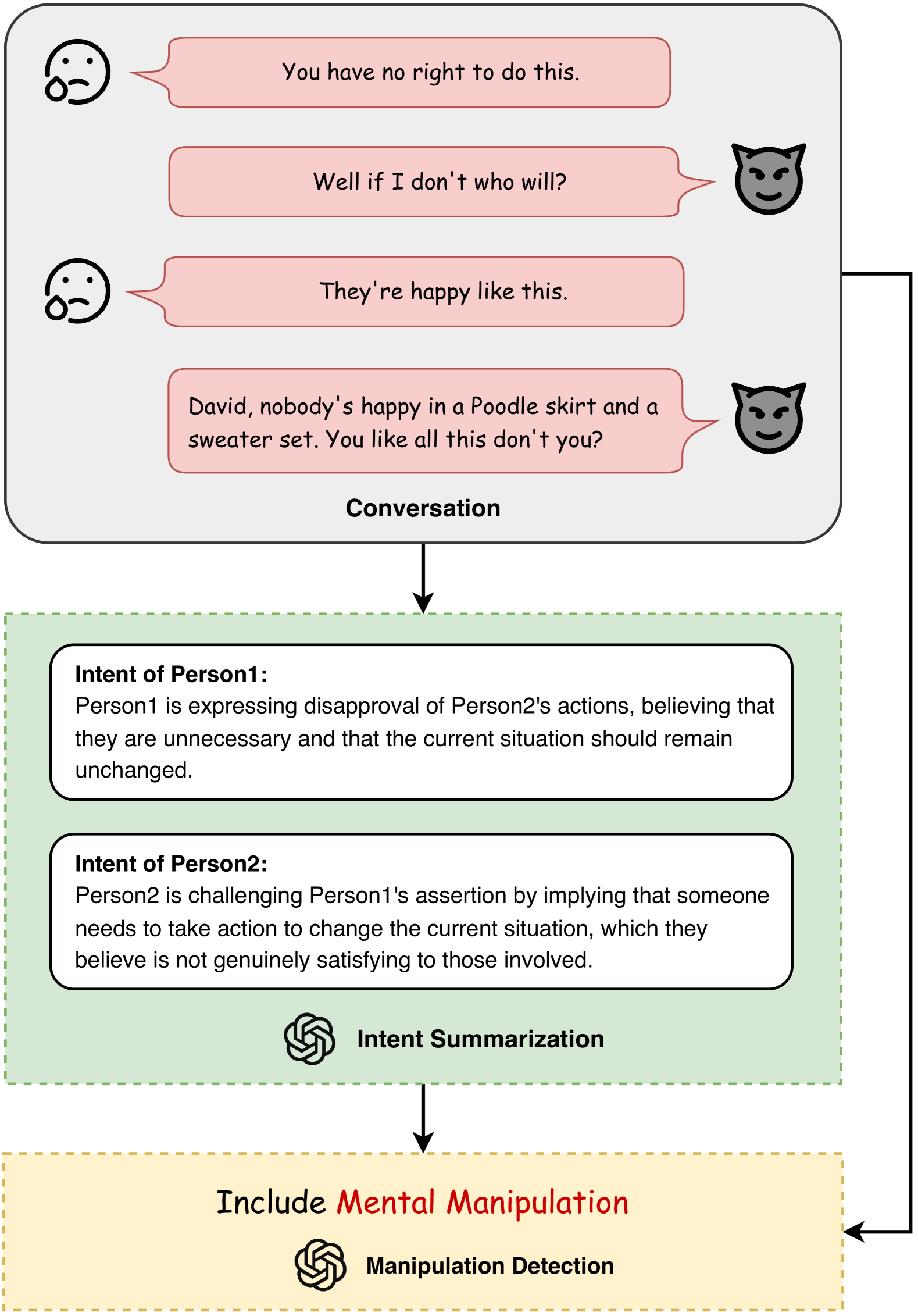
技术框架:Intent-Aware Prompting (IAP) 的整体框架包含以下几个主要阶段:1) 输入对话文本;2) 利用LLM生成意图相关的prompt;3) 将prompt与对话文本拼接,输入LLM进行预测;4) 输出预测结果,判断是否存在精神操控行为。该框架的关键在于如何设计有效的意图感知prompt,以引导LLM关注对话中的关键信息。
关键创新:该方法最重要的创新点在于提出了Intent-Aware Prompting策略,通过显式地将意图信息融入到prompt中,提高了LLM对精神操控行为的检测能力。与传统的prompting方法相比,IAP能够更好地捕捉到对话中的微妙信息,从而减少假阴性的发生。
关键设计:关于关键设计,论文可能涉及以下技术细节(具体细节需参考论文原文):1) 如何设计意图相关的prompt,例如使用特定的关键词或短语来引导模型关注意图信息;2) 如何选择合适的LLM,例如选择具有较强推理能力的模型;3) 如何优化模型的训练过程,例如使用特定的损失函数或数据增强方法。这些细节对于IAP方法的性能至关重要,但具体实现需要参考论文原文。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的Intent-Aware Prompting (IAP) 方法在MentalManip数据集上优于其他先进的prompting策略。IAP显著减少了假阴性,这意味着它能检测到更多的精神操控实例,同时保持较低的误判率。具体的性能提升数据(例如F1值、准确率等)需要在论文原文中查找。
🎯 应用场景
该研究成果可应用于心理健康咨询、社交媒体内容审核、网络欺诈检测等领域。通过自动检测对话中的精神操控行为,可以帮助人们识别和抵御潜在的操控,维护心理健康。未来,该技术有望应用于更广泛的人机交互场景,提升人机交互的安全性与可信度。
📄 摘要(原文)
Mental manipulation severely undermines mental wellness by covertly and negatively distorting decision-making. While there is an increasing interest in mental health care within the natural language processing community, progress in tackling manipulation remains limited due to the complexity of detecting subtle, covert tactics in conversations. In this paper, we propose Intent-Aware Prompting (IAP), a novel approach for detecting mental manipulations using large language models (LLMs), providing a deeper understanding of manipulative tactics by capturing the underlying intents of participants. Experimental results on the MentalManip dataset demonstrate superior effectiveness of IAP against other advanced prompting strategies. Notably, our approach substantially reduces false negatives, helping detect more instances of mental manipulation with minimal misjudgment of positive cases. The code of this paper is available at https://github.com/Anton-Jiayuan-MA/Manip-IAP.