Learning to Reason via Self-Iterative Process Feedback for Small Language Models
作者: Kaiyuan Chen, Jin Wang, Xuejie Zhang
分类: cs.CL
发布日期: 2024-12-11
备注: Accepted by COLING 2025
💡 一句话要点
提出基于自迭代过程反馈的小语言模型推理学习方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小语言模型 推理学习 自迭代反馈 过程监督 偏好优化
📋 核心要点
- 现有小语言模型推理能力不足,且依赖外部监督信号,导致模型过度自信,泛化能力受限。
- 论文提出一种基于自迭代反馈的推理学习方法,利用模型自身生成的正负信号进行微调和对齐。
- 实验结果表明,该方法在GSM8K和MBPP等数据集上显著提升了小语言模型的推理性能,并具有良好的域外泛化能力。
📝 摘要(中文)
小语言模型(SLMs)相比大语言模型(LLMs)更高效、经济且可定制,但在推理等特定领域表现不佳。以往提升SLMs推理能力的方法,如监督微调和知识蒸馏,通常依赖昂贵的外部信号,导致SLMs在有限的监督信号下过度自信,从而限制了其能力。因此,本研究使SLMs能够从自迭代反馈中学习推理。通过结合优势比偏好优化(ORPO),我们使用SLMs自身生成的正负信号来微调和对齐SLMs。此外,我们通过基于采样的推理模拟和过程奖励模型,为偏好对齐中的奖励引入过程监督。与监督微调(SFT)相比,我们的方法在GSM8K上将Gemma-2B的性能提高了12.43(Acc),在MBPP上提高了3.95(Pass@1)。此外,所提出的方法还在MMLU_Math和HumanEval上表现出卓越的域外泛化能力。
🔬 方法详解
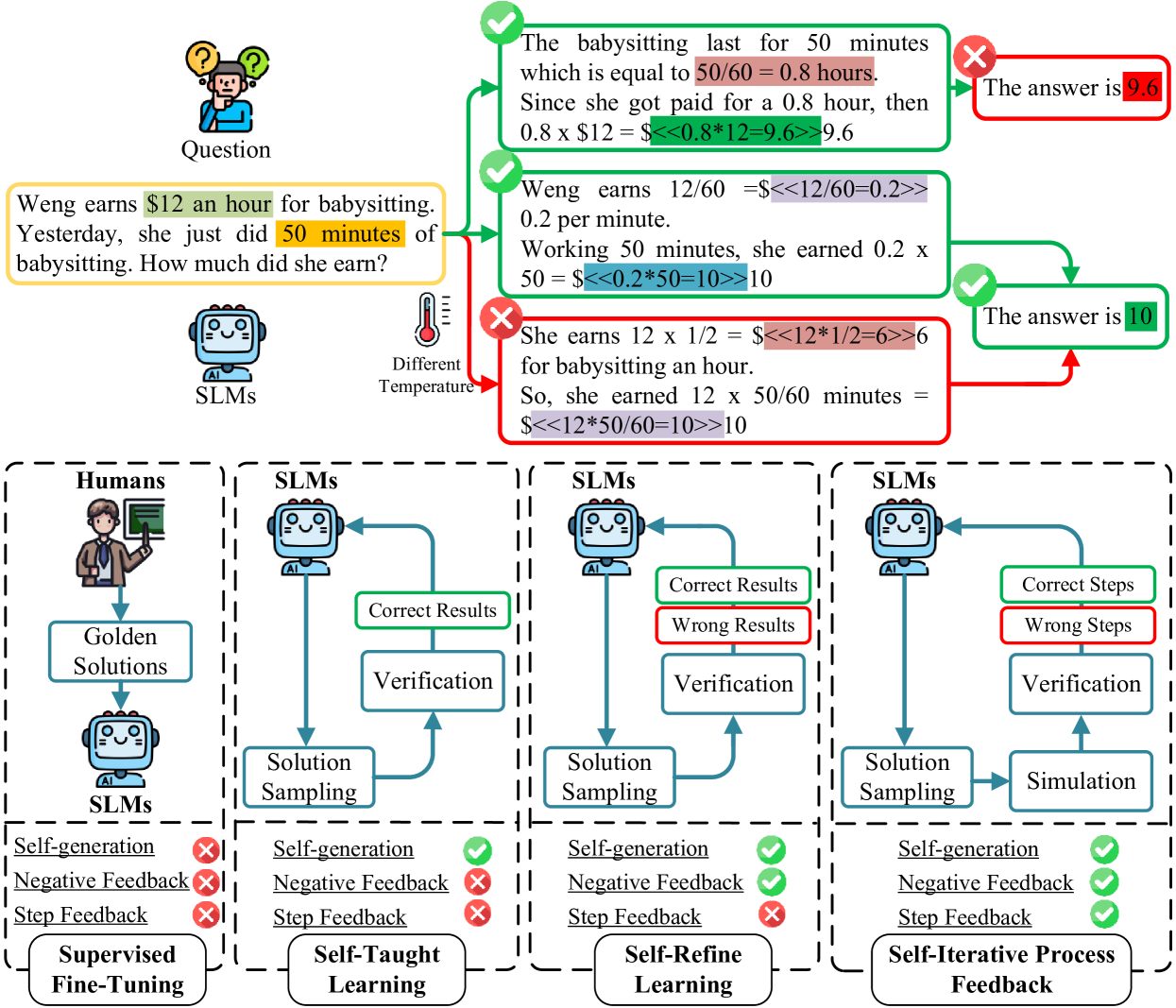
问题定义:现有的小语言模型在推理任务上表现不佳,主要原因是它们依赖于昂贵的外部监督信号进行训练,例如人工标注的数据或大型语言模型的输出。这种依赖性导致模型在训练数据分布之外的泛化能力较差,并且容易过度自信。因此,需要一种更有效的方法来提升小语言模型的推理能力,使其能够更好地适应不同的任务和领域。
核心思路:论文的核心思路是让小语言模型通过自迭代过程反馈来学习推理。具体来说,模型首先生成推理过程,然后根据自身的判断或外部奖励信号对该过程进行评估,并利用评估结果来改进后续的推理过程。通过这种自迭代的方式,模型可以逐步提高其推理能力,并减少对外部监督信号的依赖。
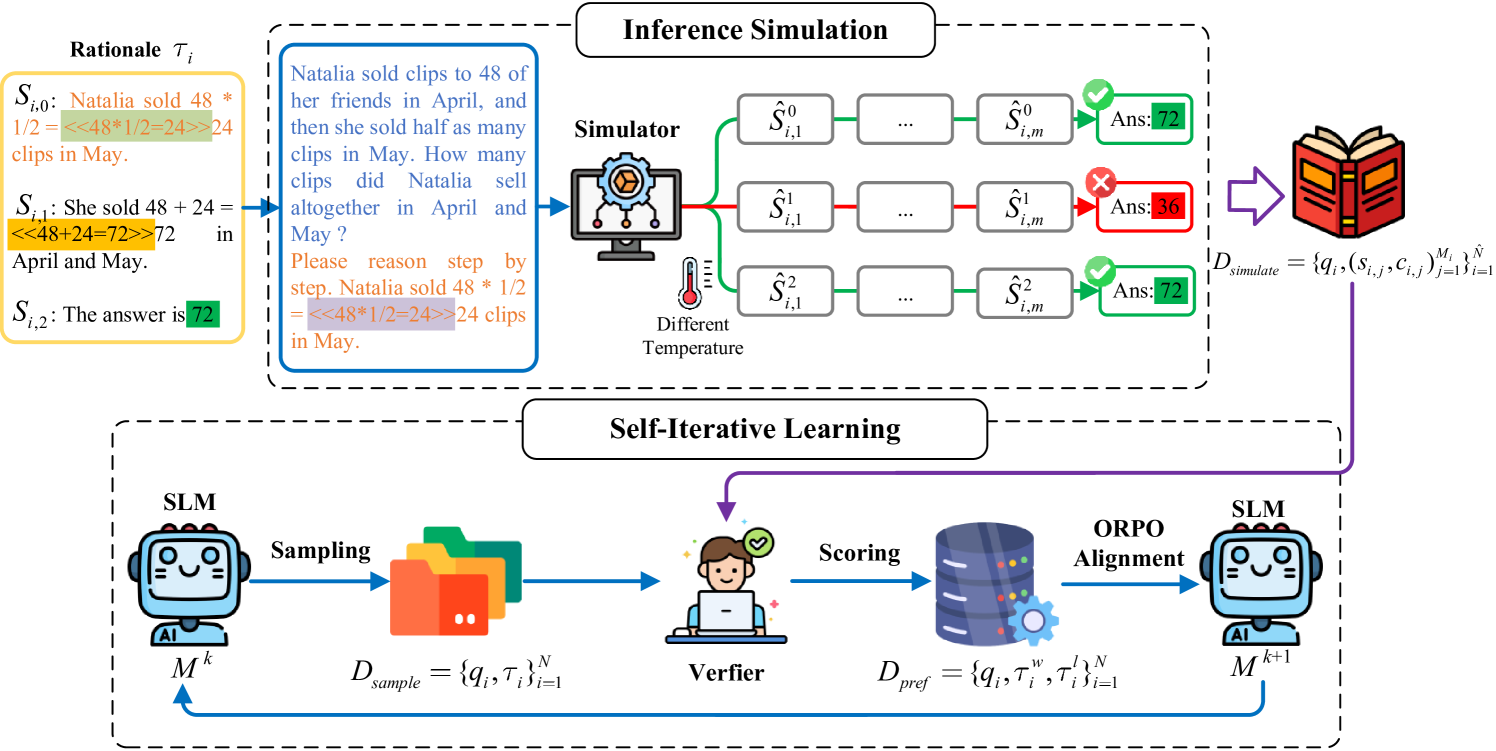
技术框架:整体框架包含以下几个主要模块:1) 推理过程生成:使用小语言模型生成推理过程,例如解决数学问题的步骤。2) 过程奖励模型:使用基于采样的推理模拟和过程奖励模型,对推理过程的每一步进行评估,并给出奖励信号。3) 偏好对齐:使用优势比偏好优化(ORPO)算法,根据奖励信号对模型进行微调,使其更倾向于生成高质量的推理过程。
关键创新:最重要的技术创新点在于引入了自迭代过程反馈机制,使得小语言模型能够从自身的经验中学习推理,而不需要依赖大量的外部监督信号。此外,论文还提出了基于采样的推理模拟和过程奖励模型,用于对推理过程进行评估,并为模型提供反馈信号。
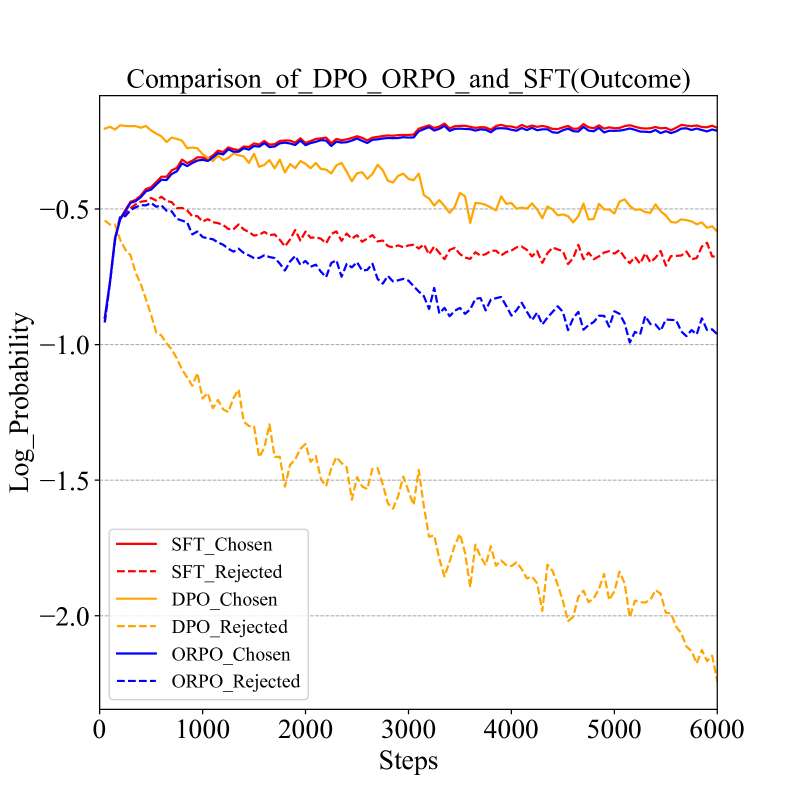
关键设计:论文的关键设计包括:1) 使用优势比偏好优化(ORPO)算法进行偏好对齐,该算法能够有效地利用正负信号来微调模型。2) 设计了基于采样的推理模拟和过程奖励模型,用于对推理过程进行评估,并为模型提供反馈信号。3) 通过实验验证了该方法在多个数据集上的有效性,并分析了不同参数设置对模型性能的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在GSM8K数据集上将Gemma-2B的准确率提高了12.43%,在MBPP数据集上将Pass@1指标提高了3.95%。此外,该方法还在MMLU_Math和HumanEval数据集上表现出卓越的域外泛化能力,证明了其在提升小语言模型推理能力方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要推理能力的场景,例如智能客服、自动问答、数学解题等。通过提升小语言模型的推理能力,可以降低部署成本,提高响应速度,并实现更灵活的定制化。未来,该方法有望进一步扩展到其他领域,例如代码生成、文本摘要等,从而推动人工智能技术的广泛应用。
📄 摘要(原文)
Small language models (SLMs) are more efficient, cost-effective, and customizable than large language models (LLMs), though they often underperform in specific areas like reasoning. Past methods for enhancing SLMs' reasoning, such as supervised fine-tuning and distillation, often depend on costly external signals, resulting in SLMs being overly confident with limited supervision signals, thus limiting their abilities. Therefore, this study enables SLMs to learn to reason from self-iterative feedback. By combining odds ratio preference optimization (ORPO), we fine-tune and align SLMs using positive and negative signals generated by themselves. Additionally, we introduce process supervision for rewards in preference alignment by sampling-based inference simulation and process reward models. Compared to Supervised Fine-Tuning (SFT), our method improves the performance of Gemma-2B by 12.43 (Acc) on GSM8K and 3.95 (Pass@1) on MBPP. Furthermore, the proposed method also demonstrated superior out-of-domain generalization capabilities on MMLU_Math and HumanEval.