Code LLMs: A Taxonomy-based Survey
作者: Nishat Raihan, Christian Newman, Marcos Zampieri
分类: cs.CL
发布日期: 2024-12-11
💡 一句话要点
构建代码大语言模型分类体系,综述其在自然语言-编程语言桥接中的应用与挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码大语言模型 自然语言处理 编程语言 分类体系 代码生成
📋 核心要点
- 现有方法难以有效弥合自然语言与编程语言之间的鸿沟,限制了代码大语言模型在实际应用中的潜力。
- 论文提出一种基于分类体系的框架,对代码大语言模型进行系统性分析,从而更深入地理解其原理与应用。
- 该综述深入探讨了代码大语言模型在编码任务中的应用、局限性以及未来发展方向,为领域研究提供参考。
📝 摘要(中文)
大型语言模型(LLMs)在各种自然语言处理(NLP)任务中展现了卓越的能力,并且最近将其影响扩展到编码任务,弥合了自然语言(NL)和编程语言(PL)之间的差距。本研究基于分类体系,对NL-PL领域中的LLM进行了全面分析,调查了这些模型如何在编码任务中得到应用,并考察了它们的方法、架构和训练过程。我们提出了一个基于分类体系的框架,对相关概念进行分类,提供了一个统一的分类系统,以促进对这个快速发展领域的更深入理解。本综述提供了关于LLM在编码任务中的现状和未来方向的见解,包括它们的应用和局限性。
🔬 方法详解
问题定义:论文旨在解决自然语言和编程语言之间的语义鸿沟问题,现有方法在理解和生成代码方面存在局限性,例如难以处理复杂的代码逻辑、缺乏对代码语义的深入理解等。这阻碍了LLM在代码生成、代码理解和代码修复等任务中的应用。
核心思路:论文的核心思路是构建一个全面的分类体系,对现有的代码LLM进行系统性的梳理和分析。通过对模型的架构、训练方法、应用场景等进行分类,从而更清晰地了解不同模型的优缺点,以及它们在不同任务中的适用性。这种分类体系能够帮助研究人员更好地理解该领域的发展现状和未来趋势。
技术框架:论文构建的分类框架主要包含以下几个方面:1) 模型架构:例如Transformer、RNN等;2) 训练方法:例如预训练、微调、强化学习等;3) 应用场景:例如代码生成、代码理解、代码修复等;4) 评估指标:例如BLEU、CodeBLEU等。通过对这些方面的分类,可以对现有的代码LLM进行全面的分析和比较。
关键创新:该论文的关键创新在于提出了一个针对代码LLM的分类体系,该体系能够对现有的模型进行系统性的梳理和分析,从而帮助研究人员更好地理解该领域的发展现状和未来趋势。与以往的综述文章相比,该论文更加注重对模型的分类和比较,而不是简单地罗列不同的模型。
关键设计:论文的关键设计在于分类体系的构建,需要仔细考虑哪些因素是影响模型性能的关键因素,并根据这些因素对模型进行分类。例如,在模型架构方面,需要考虑模型是否采用了注意力机制、是否采用了Transformer结构等。在训练方法方面,需要考虑模型是否采用了预训练、是否采用了微调等。此外,论文还对不同的评估指标进行了分析,并提出了选择合适的评估指标的建议。
🖼️ 关键图片
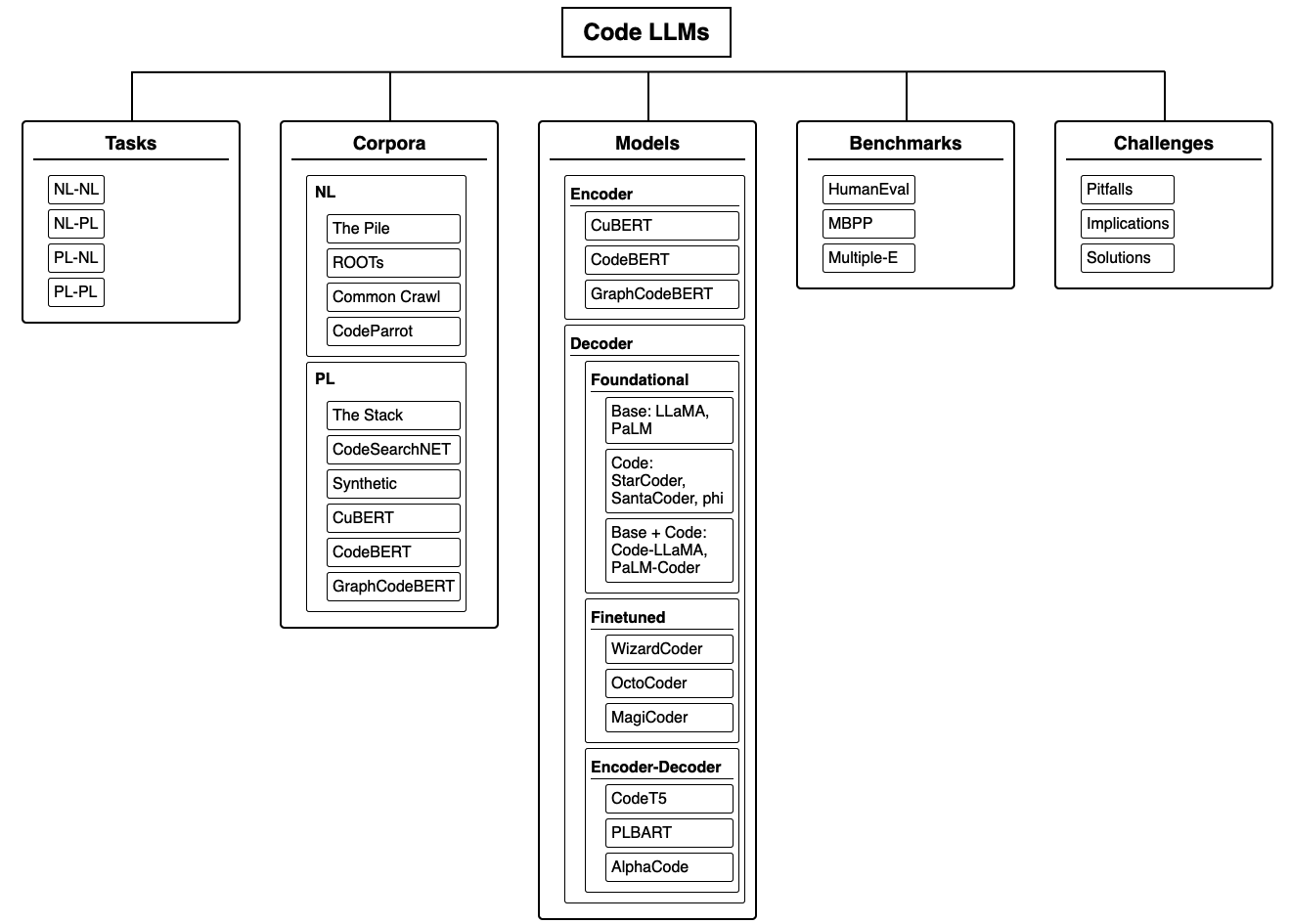
📊 实验亮点
该综述论文的主要亮点在于构建了一个全面的代码LLM分类体系,并基于此对现有模型进行了深入分析。虽然没有提供具体的实验数据,但通过对不同模型的架构、训练方法和应用场景进行比较,揭示了不同模型的优缺点,为研究人员提供了有价值的参考信息。该综述有助于研究人员更好地理解代码LLM领域的发展现状和未来趋势。
🎯 应用场景
该研究成果可应用于软件开发、自动化测试、代码教育等领域。通过对代码LLM的深入理解,可以开发出更智能的代码生成工具、更高效的代码理解系统,以及更个性化的代码学习平台。此外,该研究还可以促进自然语言处理和编程语言处理的交叉融合,推动人工智能技术的发展。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable capabilities across various NLP tasks and have recently expanded their impact to coding tasks, bridging the gap between natural languages (NL) and programming languages (PL). This taxonomy-based survey provides a comprehensive analysis of LLMs in the NL-PL domain, investigating how these models are utilized in coding tasks and examining their methodologies, architectures, and training processes. We propose a taxonomy-based framework that categorizes relevant concepts, providing a unified classification system to facilitate a deeper understanding of this rapidly evolving field. This survey offers insights into the current state and future directions of LLMs in coding tasks, including their applications and limitations.