How to Choose a Threshold for an Evaluation Metric for Large Language Models
作者: Bhaskarjit Sarmah, Mingshu Li, Jingrao Lyu, Sebastian Frank, Nathalia Castellanos, Stefano Pasquali, Dhagash Mehta
分类: stat.ML, cs.CL, cs.LG, q-fin.ST, stat.AP
发布日期: 2024-12-10
备注: 16 pages, 8 figures, 4 tables. 2-columns
💡 一句话要点
提出一种基于风险管理的LLM评估指标阈值选择方法,保障模型可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 评估指标 阈值选择 模型风险管理 风险评估
📋 核心要点
- 现有LLM评估指标缺乏系统性的阈值选择方法,导致模型部署时存在风险。
- 该论文提出一种基于模型风险管理的阈值选择流程,考虑应用风险和利益相关者风险承受能力。
- 通过在HaluBench数据集上对Faithfulness指标的实验,验证了该方法的可行性。
📝 摘要(中文)
为了确保大型语言模型(LLM)的可靠性,文献中提出了各种评估指标。然而,关于如何确定这些指标的稳健阈值的研究很少,尽管在LLM部署期间,阈值的错误选择会产生许多严重的后果。借鉴金融等受监管行业中传统的模型风险管理(MRM)指南,我们提出了一种逐步方法,用于为给定的LLM评估指标选择阈值。我们强调,这种方法应首先识别所考虑的LLM应用程序的风险以及利益相关者的风险承受能力。然后,我们提出了具体且统计上严谨的程序,以使用可用的ground-truth数据确定给定LLM评估指标的阈值。作为一个具体的例子,为了演示所提出的方法,我们将其应用于Faithfulness指标,该指标在各种公开可用的库中实现,并使用公开可用的HaluBench数据集。我们还为创建系统方法来选择阈值奠定了基础,不仅适用于LLM,也适用于任何GenAI应用程序。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)评估指标阈值选择的问题。现有方法缺乏系统性和理论依据,容易导致在LLM部署过程中出现误判,进而引发安全、合规等风险。尤其是在金融等对模型风险管理要求严格的行业,缺乏合理的阈值选择方法会带来严重的业务影响。
核心思路:论文的核心思路是将传统模型风险管理(MRM)的原则应用于LLM评估指标的阈值选择。这意味着阈值的确定不应仅仅基于指标本身,而应充分考虑LLM应用场景的风险特性以及利益相关者的风险承受能力。通过将风险评估纳入阈值选择过程,可以确保所选阈值能够有效地识别和控制潜在风险。
技术框架:该方法提供了一个逐步的流程,主要包括以下几个阶段: 1. 风险识别:识别LLM应用场景中可能存在的风险,例如生成错误信息、泄露隐私数据等。 2. 风险评估:评估各种风险发生的概率和潜在影响,确定风险等级。 3. 风险承受能力评估:了解利益相关者对不同风险等级的承受能力。 4. 阈值确定:基于风险评估和风险承受能力,选择合适的评估指标阈值。 5. 阈值验证:使用ground-truth数据验证所选阈值的有效性,并进行必要的调整。
关键创新:该论文的关键创新在于将模型风险管理的理念引入到LLM评估指标的阈值选择中。与以往主要关注指标本身的方法不同,该方法强调从风险的角度出发,综合考虑应用场景、风险等级和利益相关者的风险承受能力,从而选择更具鲁棒性和实用性的阈值。
关键设计:论文中没有明确提及具体的参数设置或网络结构,而是侧重于方法论的构建。关键设计在于将风险评估和风险承受能力评估纳入阈值选择流程,并提供了一套可操作的步骤,指导用户根据实际情况选择合适的阈值。在实验部分,论文使用了Faithfulness指标和HaluBench数据集来演示该方法的应用,但具体的技术细节取决于所选的评估指标和数据集。
🖼️ 关键图片
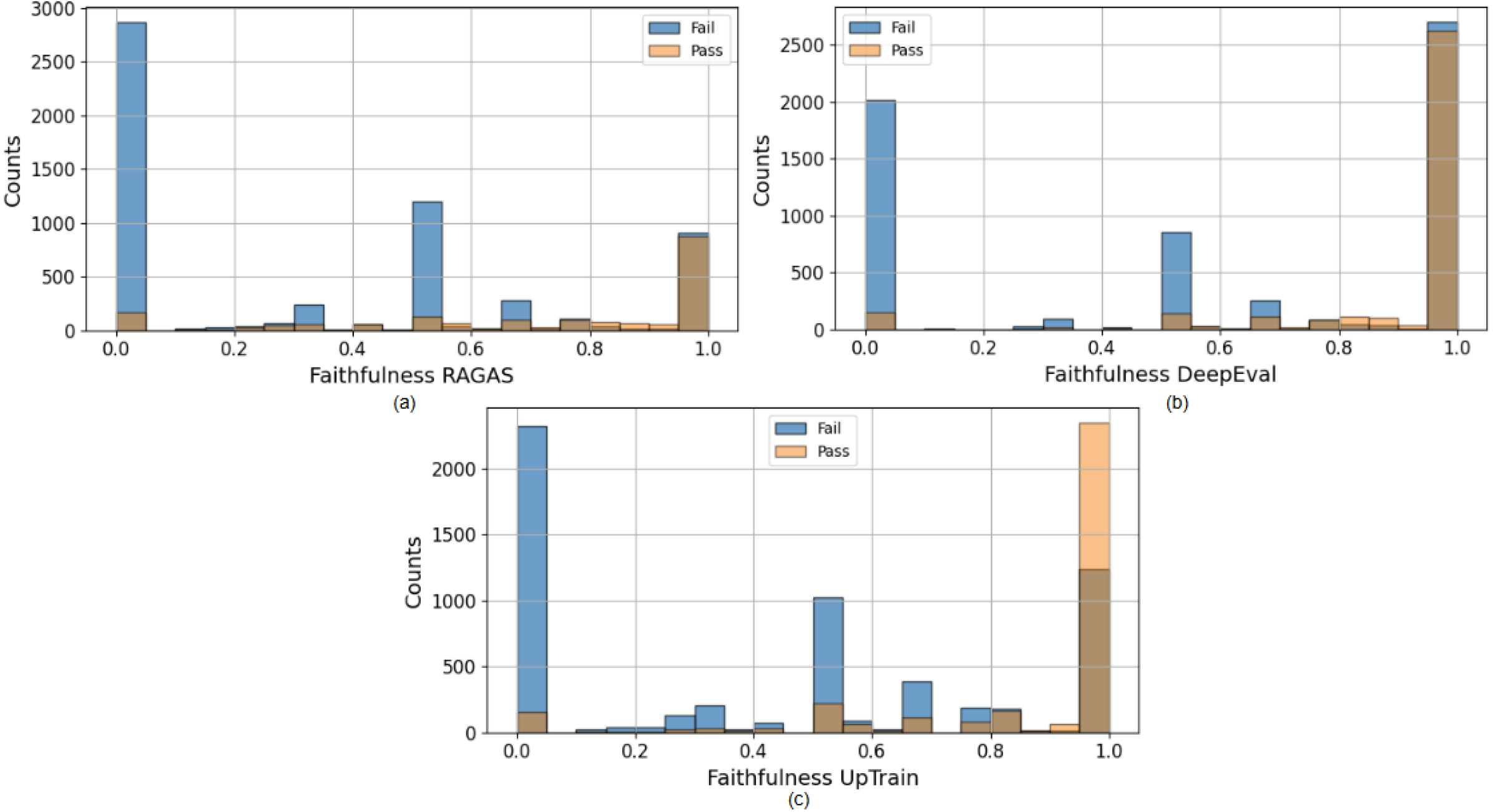


📊 实验亮点
论文通过在HaluBench数据集上对Faithfulness指标进行实验,验证了所提出的阈值选择方法的可行性。虽然论文没有给出具体的性能提升数据,但实验结果表明,该方法能够根据不同的风险承受能力选择合适的阈值,从而更好地平衡模型的准确性和风险控制。该实验为该方法的实际应用提供了初步的证据。
🎯 应用场景
该研究成果可广泛应用于各种需要使用LLM的场景,尤其是在金融、医疗等对模型风险管理要求严格的行业。通过采用该方法,可以更有效地控制LLM带来的风险,提高模型的可靠性和安全性,从而促进LLM在实际业务中的应用。未来,该方法可以扩展到其他生成式AI应用,为GenAI应用的风险管理提供更全面的解决方案。
📄 摘要(原文)
To ensure and monitor large language models (LLMs) reliably, various evaluation metrics have been proposed in the literature. However, there is little research on prescribing a methodology to identify a robust threshold on these metrics even though there are many serious implications of an incorrect choice of the thresholds during deployment of the LLMs. Translating the traditional model risk management (MRM) guidelines within regulated industries such as the financial industry, we propose a step-by-step recipe for picking a threshold for a given LLM evaluation metric. We emphasize that such a methodology should start with identifying the risks of the LLM application under consideration and risk tolerance of the stakeholders. We then propose concrete and statistically rigorous procedures to determine a threshold for the given LLM evaluation metric using available ground-truth data. As a concrete example to demonstrate the proposed methodology at work, we employ it on the Faithfulness metric, as implemented in various publicly available libraries, using the publicly available HaluBench dataset. We also lay a foundation for creating systematic approaches to select thresholds, not only for LLMs but for any GenAI applications.