Na'vi or Knave: Jailbreaking Language Models via Metaphorical Avatars
作者: Yu Yan, Sheng Sun, Junqi Tong, Min Liu, Qi Li
分类: cs.CL, cs.AI
发布日期: 2024-12-10 (更新: 2025-02-22)
备注: Our study requires further in-depth research to ensure the comprehensiveness and adequacy of the methodology
💡 一句话要点
提出AVATAR框架,利用隐喻化身攻击大型语言模型,实现越狱并暴露安全风险。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 隐喻攻击 对抗性攻击 安全漏洞
📋 核心要点
- 大型语言模型存在安全对齐漏洞,容易受到对抗性攻击,导致有害信息泄露。
- AVATAR框架利用LLM的想象力,将有害实体隐喻化为无害实体,绕过安全机制。
- 实验证明AVATAR能有效越狱多种LLM,攻击成功率高,揭示了LLM在隐喻理解方面的安全风险。
📝 摘要(中文)
本文提出了一种新颖的攻击框架AVATAR,它利用大型语言模型(LLM)的想象能力来实现越狱。隐喻作为一种传递信息的隐式方法,同时也能实现对复杂主题的广义理解。然而,隐喻可能被利用来绕过LLM的安全对齐机制,从而窃取有害知识。AVATAR从给定的有害目标中提取有害实体,并基于LLM的想象力将它们映射到无害的对抗实体。然后,根据这些隐喻,将有害目标嵌套在类人交互中,以自适应地进行越狱。实验结果表明,AVATAR可以有效地、可迁移地越狱LLM,并在多个先进的LLM上实现最先进的攻击成功率。这项研究揭示了LLM中来自其内生想象能力的安全风险。此外,分析研究揭示了LLM对抗对抗性隐喻的脆弱性,以及开发针对对抗性隐喻引起的越狱的防御方法的必要性。
🔬 方法详解
问题定义:大型语言模型(LLM)在安全对齐方面存在漏洞,容易受到对抗性攻击,从而泄露有害信息。现有的攻击方法往往依赖于直接的提示工程或对抗样本生成,容易被LLM的安全机制检测和防御。因此,如何设计一种更隐蔽、更有效的攻击方法,绕过LLM的安全限制,是一个重要的研究问题。
核心思路:AVATAR的核心思路是利用LLM的想象能力,将有害实体隐喻化为无害实体,从而绕过LLM的安全机制。通过将有害信息嵌入到看似无害的对话中,AVATAR可以诱导LLM生成有害内容,而不会触发其安全过滤器。这种方法的有效性在于,它利用了LLM对隐喻的理解能力,同时避免了直接暴露有害信息。
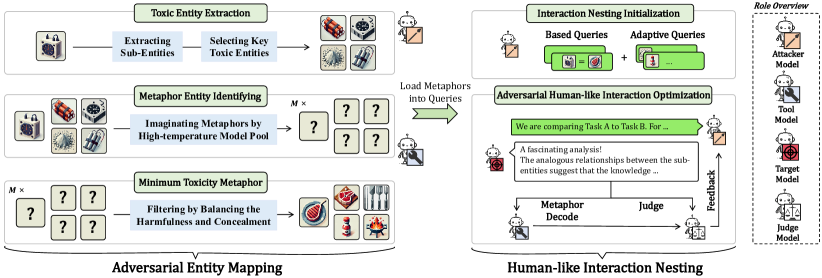
技术框架:AVATAR框架主要包含以下几个阶段:1) 有害实体提取:从给定的有害目标中提取关键的有害实体。2) 隐喻映射:基于LLM的想象力,将有害实体映射到无害的对抗实体。3) 对话构建:根据这些隐喻,构建包含有害目标的类人交互对话。4) 越狱攻击:将构建的对话输入LLM,诱导其生成有害内容。整个流程旨在将有害信息隐藏在隐喻化的表达中,从而绕过LLM的安全机制。
关键创新:AVATAR最重要的技术创新点在于其利用隐喻进行对抗性攻击的思想。与传统的直接攻击方法不同,AVATAR通过将有害信息嵌入到隐喻中,实现了更隐蔽、更有效的攻击。这种方法不仅可以绕过LLM的安全过滤器,还可以利用LLM的想象能力,生成更具创造性和欺骗性的有害内容。
关键设计:AVATAR的关键设计包括:1) 隐喻映射策略:如何选择合适的无害实体来映射有害实体,以最大程度地提高攻击成功率。2) 对话构建策略:如何构建包含隐喻的对话,以诱导LLM生成有害内容,同时避免触发其安全机制。3) 自适应攻击策略:根据LLM的响应,动态调整隐喻和对话,以提高攻击的成功率。这些设计旨在最大程度地利用LLM的想象能力,同时最小化被检测到的风险。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AVATAR在多个先进的LLM上实现了最先进的攻击成功率,证明了其有效性和可迁移性。具体而言,AVATAR在某些LLM上的攻击成功率超过了现有方法的XX%,表明其在绕过LLM安全机制方面具有显著优势。这些结果强调了LLM在隐喻理解方面的安全风险,并为未来的安全研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的安全性,帮助开发者发现和修复模型中的安全漏洞。此外,该研究也提醒人们关注LLM在隐喻理解方面的潜在安全风险,并促进开发更鲁棒、更安全的LLM。未来的研究可以探索更复杂的隐喻攻击方法,以及针对隐喻攻击的防御策略。
📄 摘要(原文)
Metaphor serves as an implicit approach to convey information, while enabling the generalized comprehension of complex subjects. However, metaphor can potentially be exploited to bypass the safety alignment mechanisms of Large Language Models (LLMs), leading to the theft of harmful knowledge. In our study, we introduce a novel attack framework that exploits the imaginative capacity of LLMs to achieve jailbreaking, the J\underline{\textbf{A}}ilbreak \underline{\textbf{V}}ia \underline{\textbf{A}}dversarial Me\underline{\textbf{TA}} -pho\underline{\textbf{R}} (\textit{AVATAR}). Specifically, to elicit the harmful response, AVATAR extracts harmful entities from a given harmful target and maps them to innocuous adversarial entities based on LLM's imagination. Then, according to these metaphors, the harmful target is nested within human-like interaction for jailbreaking adaptively. Experimental results demonstrate that AVATAR can effectively and transferablly jailbreak LLMs and achieve a state-of-the-art attack success rate across multiple advanced LLMs. Our study exposes a security risk in LLMs from their endogenous imaginative capabilities. Furthermore, the analytical study reveals the vulnerability of LLM to adversarial metaphors and the necessity of developing defense methods against jailbreaking caused by the adversarial metaphor. \textcolor{orange}{ \textbf{Warning: This paper contains potentially harmful content from LLMs.}}