Asking Again and Again: Exploring LLM Robustness to Repeated Questions
作者: Sagi Shaier, Mario Sanz-Guerrero, Katharina von der Wense
分类: cs.CL
发布日期: 2024-12-10 (更新: 2025-03-12)
💡 一句话要点
研究重复提问对LLM阅读理解能力的影响,发现重复提问对性能提升不显著
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 阅读理解 提示词工程 重复提问 统计显著性
📋 核心要点
- 现有研究缺乏对重复提问在LLM阅读理解任务中影响的系统性分析。
- 该研究通过在提示词中重复问题,探索LLM对关键信息的关注度是否增强。
- 实验结果表明,重复提问虽能提升准确率,但提升效果不具有统计显著性。
📝 摘要(中文)
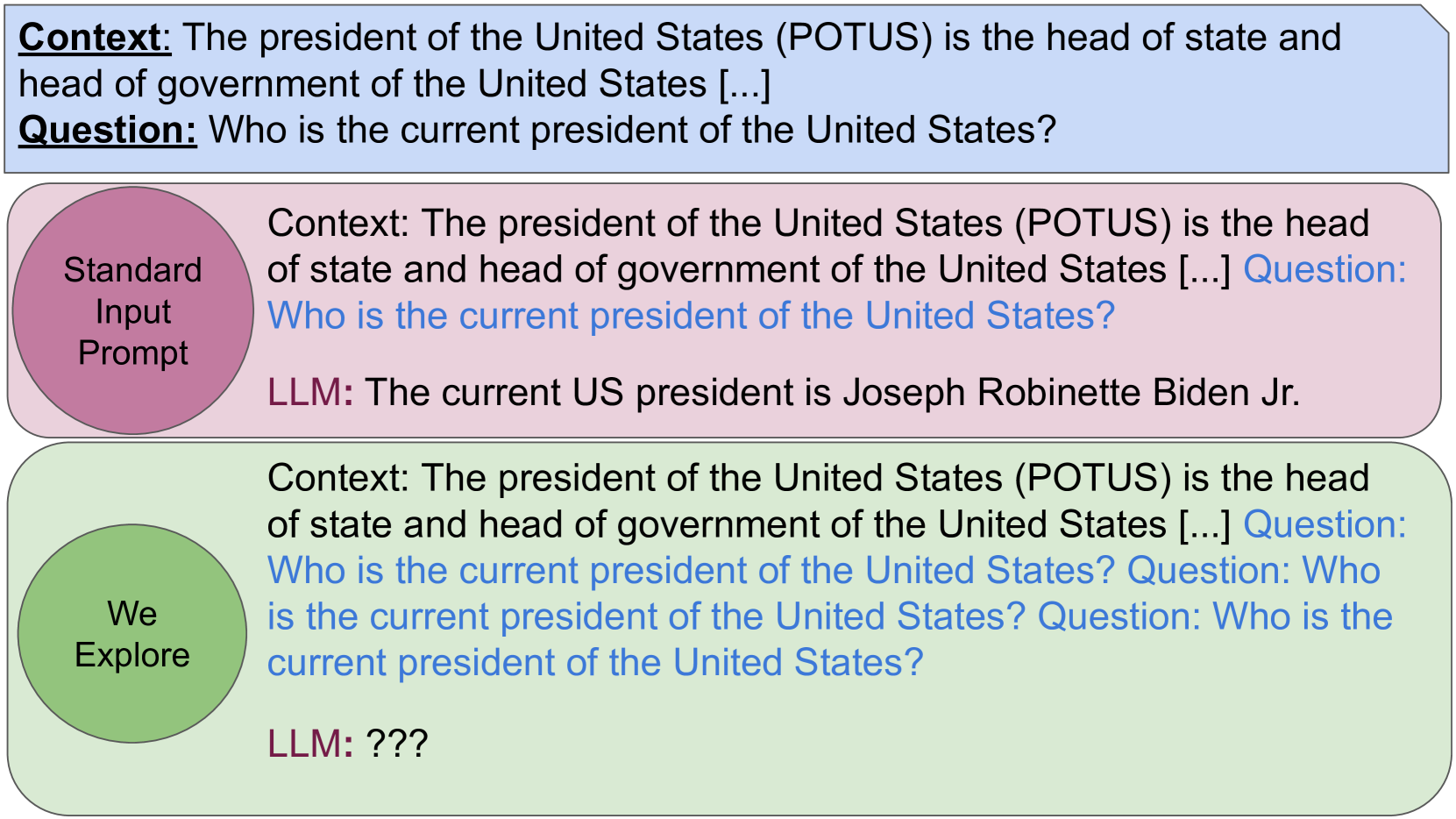
本研究探讨了在提示词中重复提问是否会影响大型语言模型(LLM)的性能。我们假设在单个提示词中重复问题可能会增强模型对查询关键要素的关注。我们评估了五个最新的LLM——包括GPT-4o-mini、DeepSeek-V3和较小的开源模型——在三种阅读理解数据集上,采用不同的提示设置,改变问题重复的次数(每个提示词1次、3次或5次)。我们的结果表明,问题重复可以提高模型高达6%的准确率。然而,在所有模型、设置和数据集上,我们没有发现结果具有统计显著性。这些发现为提示词设计和LLM行为提供了见解,表明仅靠重复并不能显著影响输出质量。
🔬 方法详解
问题定义:论文旨在研究在阅读理解任务中,重复提问是否能提升大型语言模型的性能。现有方法在提示词设计上缺乏对提问方式的深入研究,可能导致模型无法充分理解问题的关键信息,从而影响阅读理解效果。
核心思路:论文的核心思路是通过在提示词中多次重复问题,来增强模型对问题关键信息的关注度。作者假设重复提问可以引导模型更集中地处理与问题相关的文本内容,从而提高回答的准确性。
技术框架:该研究的技术框架主要包括以下几个步骤:1)选择阅读理解数据集;2)构建不同重复次数(1次、3次、5次)的提示词;3)使用选定的LLM对提示词进行推理,得到答案;4)评估模型在不同重复次数下的准确率;5)进行统计显著性检验,判断重复提问对性能的影响是否显著。
关键创新:该研究的创新点在于,它系统性地研究了重复提问这一简单的提示词设计策略对LLM阅读理解性能的影响。虽然最终结果显示提升不显著,但该研究为提示词工程提供了一个新的视角,即通过重复提问来引导模型关注关键信息。
关键设计:该研究的关键设计包括:1)选择了多个具有代表性的LLM,包括闭源模型和开源模型;2)使用了多个阅读理解数据集,以保证结果的泛化性;3)采用了不同的重复次数,以探索最佳的重复策略;4)进行了统计显著性检验,以保证结果的可靠性。没有涉及特定的损失函数或网络结构设计,主要关注提示词工程。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在某些情况下,重复提问可以提高LLM的准确率,最高可达6%。然而,在所有模型、设置和数据集上,这种提升并不具有统计显著性。GPT-4o-mini和DeepSeek-V3等模型在重复提问的情况下表现出一定的性能提升,但提升幅度有限。该研究强调了提示词工程的重要性,并指出简单的重复策略可能不足以显著提升LLM的阅读理解能力。
🎯 应用场景
该研究的潜在应用领域包括智能问答系统、教育辅助工具和信息检索等。通过优化提问方式,可以提高LLM在这些应用中的性能,从而提供更准确、更有效的服务。未来的研究可以进一步探索更复杂的提问策略,例如结合不同的提问方式和上下文信息,以进一步提升LLM的阅读理解能力。
📄 摘要(原文)
This study investigates whether repeating questions within prompts influences the performance of large language models (LLMs). We hypothesize that reiterating a question within a single prompt might enhance the model's focus on key elements of the query. We evaluate five recent LLMs -- including GPT-4o-mini, DeepSeek-V3, and smaller open-source models -- on three reading comprehension datasets under different prompt settings, varying question repetition levels (1, 3, or 5 times per prompt). Our results demonstrate that question repetition can increase models' accuracy by up to $6\%$. However, across all models, settings, and datasets, we do not find the result statistically significant. These findings provide insights into prompt design and LLM behavior, suggesting that repetition alone does not significantly impact output quality.