Rethinking Emotion Annotations in the Era of Large Language Models
作者: Minxue Niu, Yara El-Tawil, Amrit Romana, Emily Mower Provost
分类: cs.CL
发布日期: 2024-12-10
💡 一句话要点
利用大型语言模型辅助情感标注,提升标注质量与效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感标注 大型语言模型 GPT-4 情感计算 自然语言处理
📋 核心要点
- 人工情感标注成本高、质量控制难,且情感本身具有主观性,这给情感计算数据集的构建带来了挑战。
- 论文探索利用GPT-4等大型语言模型辅助情感标注,旨在结合LLM的优势与人类的视角,提升标注效率和质量。
- 实验表明,GPT-4在情感标注任务中表现良好,可用于标记低质量标签、减少人工工作量,并提升下游模型性能。
📝 摘要(中文)
现代情感计算系统严重依赖于人工标注的情感标签数据集进行训练和评估。然而,由于情感的主观性,人工标注成本高昂,对研究设计敏感,且难以进行质量控制。与此同时,大型语言模型(LLMs)在许多自然语言理解任务中表现出色,成为一种有前景的文本标注工具。本文分析了LLMs背景下情感标注的复杂性,重点关注GPT-4。实验表明,GPT-4在人工评估中获得了高分,比以往仅以人工标签作为唯一真值的研究展现出更积极的前景。另一方面,我们观察到人类和GPT-4在情感感知上的差异,强调了人工输入在标注研究中的重要性。为了发挥GPT-4的优势,同时保留人类视角,我们探索了将GPT-4集成到情感标注流程中的两种方法,展示了其在标记低质量标签、减少人工标注员工作量以及提高下游模型学习性能和效率方面的潜力。总而言之,我们的发现突出了新的情感标注实践的机会,并建议使用LLMs作为辅助人工标注的有前景的工具。
🔬 方法详解
问题定义:情感计算领域依赖大量人工标注的情感标签数据,但人工标注存在成本高、主观性强、质量难以保证等问题。现有方法主要依赖人工标注,缺乏有效的自动化辅助手段,导致数据集构建效率低下,且标注质量参差不齐。
核心思路:论文的核心思路是利用大型语言模型(LLMs),特别是GPT-4,来辅助人工情感标注。通过将LLM集成到标注流程中,可以利用其强大的自然语言理解能力,自动识别潜在的低质量标签,并减少人工标注的工作量,从而提高标注效率和质量。同时,保留人工的参与,以确保标注结果符合人类的情感认知。
技术框架:论文提出了两种将GPT-4集成到情感标注流程中的方法。第一种方法是利用GPT-4自动评估人工标注的质量,并标记出可能存在错误的低质量标签,供人工审核。第二种方法是利用GPT-4生成候选标签,然后由人工进行确认或修改,从而减少人工标注的初始工作量。整体流程包括数据预处理、GPT-4标注或评估、人工审核与修正、以及最终数据集生成等阶段。
关键创新:论文的关键创新在于探索了利用大型语言模型辅助情感标注的新模式。与以往完全依赖人工标注的方法不同,该方法充分利用了LLM的自然语言理解能力,实现了自动化辅助标注,从而提高了标注效率和质量。此外,论文还强调了在利用LLM进行标注时,保留人工参与的重要性,以确保标注结果符合人类的情感认知。
关键设计:论文中,GPT-4被用作情感分类器和质量评估器。具体而言,GPT-4接收文本输入,并输出对应的情感标签或质量评分。对于质量评估,可以设计prompt,要求GPT-4评估标注的一致性、合理性等。关键设计在于如何设计有效的prompt,引导GPT-4进行准确的情感判断和质量评估。此外,还需要设计合理的阈值,用于判断哪些标签需要人工审核。
🖼️ 关键图片

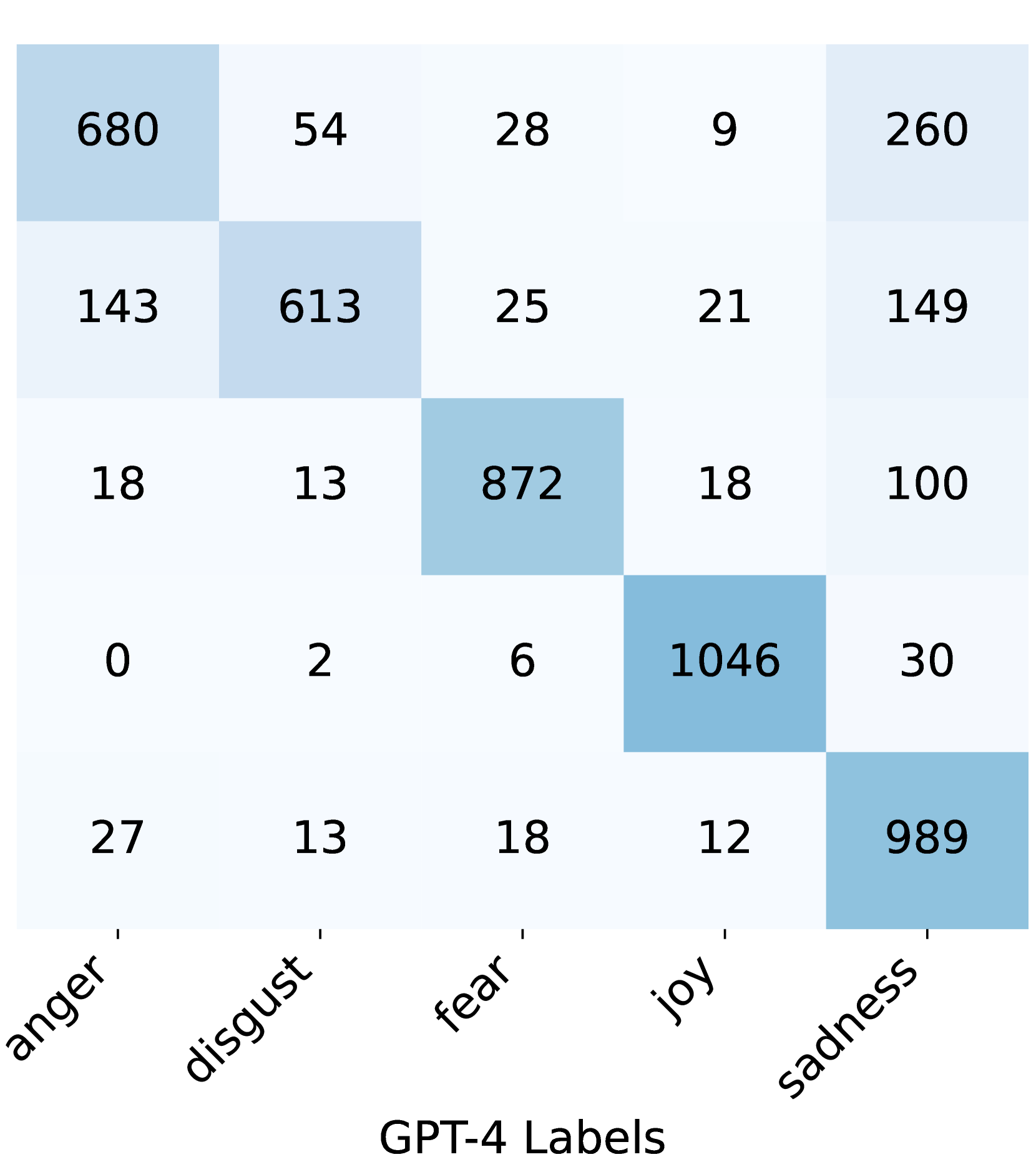

📊 实验亮点
实验结果表明,GPT-4在情感标注任务中表现出色,能够有效地识别低质量标签,并减少人工标注的工作量。人工评估显示,GPT-4的标注质量较高,与人工标注具有一定的相关性。通过将GPT-4集成到标注流程中,下游情感分类模型的性能得到了显著提升,同时标注效率也得到了提高。具体性能数据未知,但整体趋势表明LLM辅助标注具有显著优势。
🎯 应用场景
该研究成果可应用于各种情感计算相关的领域,例如情感分析、情感对话系统、用户情绪识别等。通过利用LLM辅助情感标注,可以更高效地构建高质量的情感数据集,从而提升下游情感计算模型的性能。此外,该方法还可以应用于其他需要人工标注的自然语言处理任务中,具有广泛的应用前景。
📄 摘要(原文)
Modern affective computing systems rely heavily on datasets with human-annotated emotion labels, for training and evaluation. However, human annotations are expensive to obtain, sensitive to study design, and difficult to quality control, because of the subjective nature of emotions. Meanwhile, Large Language Models (LLMs) have shown remarkable performance on many Natural Language Understanding tasks, emerging as a promising tool for text annotation. In this work, we analyze the complexities of emotion annotation in the context of LLMs, focusing on GPT-4 as a leading model. In our experiments, GPT-4 achieves high ratings in a human evaluation study, painting a more positive picture than previous work, in which human labels served as the only ground truth. On the other hand, we observe differences between human and GPT-4 emotion perception, underscoring the importance of human input in annotation studies. To harness GPT-4's strength while preserving human perspective, we explore two ways of integrating GPT-4 into emotion annotation pipelines, showing its potential to flag low-quality labels, reduce the workload of human annotators, and improve downstream model learning performance and efficiency. Together, our findings highlight opportunities for new emotion labeling practices and suggest the use of LLMs as a promising tool to aid human annotation.