Zero-Shot ATC Coding with Large Language Models for Clinical Assessments
作者: Zijian Chen, John-Michael Gamble, Micaela Jantzi, John P. Hirdes, Jimmy Lin
分类: cs.CL
发布日期: 2024-12-10
💡 一句话要点
提出基于LLM的零样本ATC编码方法,解决临床评估中人工编码瓶颈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: ATC编码 大型语言模型 零样本学习 临床评估 信息提取
📋 核心要点
- 人工ATC编码耗时费力,是医疗研究和运营的瓶颈,亟需自动化解决方案。
- 利用LLM将ATC编码视为分层信息提取任务,逐层引导模型完成编码。
- 实验表明,该方法在保证隐私的前提下,使用Llama模型取得了可观的编码精度。
📝 摘要(中文)
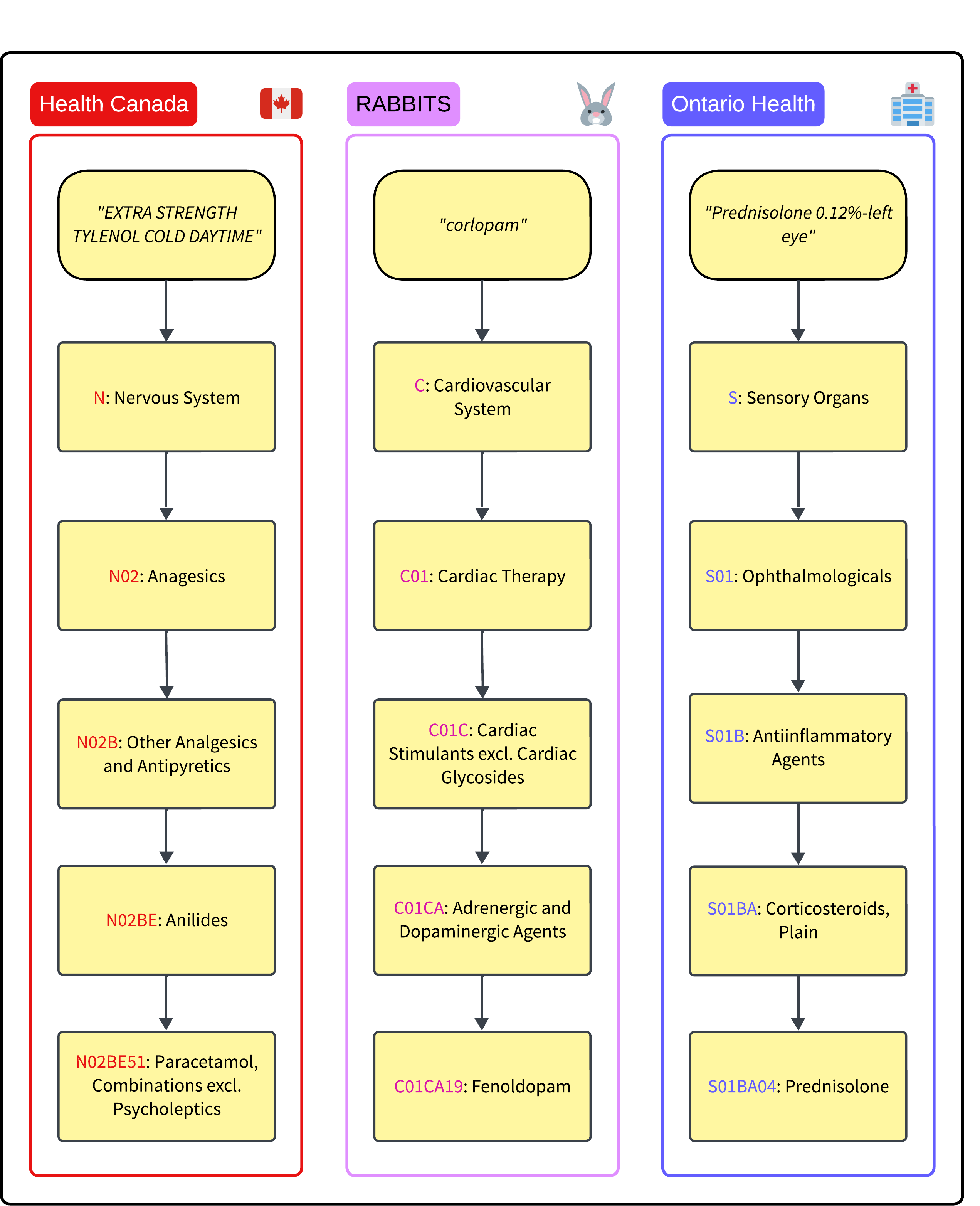
本研究针对Ontario Health和InterRAI Canada在医疗研究和运营中,处方记录的解剖学治疗化学(ATC)编码人工分配耗时费力的问题,提出了一种利用本地可部署的大型语言模型(LLM)的自动化方法。该方法借鉴了自动国际疾病分类(ICD)编码的最新进展,将ATC编码构建为分层信息提取任务,逐级引导LLM完成ATC本体。使用GPT-4o作为精度上限评估,并侧重于适用于隐私敏感部署的开源Llama模型。在加拿大卫生部药品数据、RABBITS基准和来自Ontario Health的真实临床记录上进行测试,该方法使用GPT-4o实现了78%的精确匹配准确率,使用Llama 3.1 70B实现了60%。研究了通过药物定义进行知识增强,发现准确率有小幅提升。此外,微调后的Llama 3.1 8B模型与零样本Llama 3.1 70B模型达到了相同的准确率,表明使用较小模型进行有效的ATC编码是可行的。研究结果证明了在隐私敏感的医疗环境中自动ATC编码的可行性,为未来的部署奠定了基础。
🔬 方法详解
问题定义:论文旨在解决临床评估中,处方记录的解剖学治疗化学(ATC)编码人工分配效率低下的问题。现有方法依赖人工,耗费大量专家时间和精力,且难以扩展到大规模数据集。此外,数据隐私也是一个重要的考虑因素,限制了使用云端API进行编码。
核心思路:论文的核心思路是将ATC编码问题转化为一个分层信息提取任务。利用大型语言模型(LLM)的自然语言理解和生成能力,逐层地从ATC本体中提取信息,从而实现自动编码。这种方法避免了传统的机器学习方法需要大量标注数据的缺点,实现了零样本学习。
技术框架:整体框架包含以下几个主要阶段:1) 输入处方记录或临床文本;2) LLM根据ATC本体的层级结构,逐层提取相关信息,例如治疗类别、药物亚类等;3) 将提取的信息组合成完整的ATC编码;4) 对编码结果进行评估和优化。该框架可以部署在本地,保证数据隐私。
关键创新:最重要的技术创新点在于将ATC编码问题转化为分层信息提取任务,并利用LLM的零样本学习能力。与传统的机器学习方法相比,该方法无需大量标注数据,降低了开发成本和时间。此外,该方法可以灵活地适应不同的ATC本体版本和编码规则。
关键设计:论文中一个关键的设计是利用药物定义进行知识增强。通过向LLM提供药物的详细描述,可以帮助模型更好地理解处方记录的含义,从而提高编码的准确率。此外,论文还探索了不同大小的LLM对编码性能的影响,发现微调后的较小模型可以达到与大型模型相当的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用GPT-4o模型,该方法在ATC编码任务上实现了78%的精确匹配准确率。使用开源的Llama 3.1 70B模型,准确率达到60%。更重要的是,经过微调的Llama 3.1 8B模型可以达到与零样本Llama 3.1 70B模型相当的准确率,这表明在保证隐私的前提下,使用较小的模型也能实现有效的ATC编码。
🎯 应用场景
该研究成果可应用于医疗机构、药物监管部门和医疗研究机构,实现处方记录的自动ATC编码,提高数据处理效率,降低人工成本。同时,该方法可以促进药物使用监测、药物流行病学研究和临床决策支持系统的发展。未来,该技术有望扩展到其他医学编码领域,例如ICD编码。
📄 摘要(原文)
Manual assignment of Anatomical Therapeutic Chemical (ATC) codes to prescription records is a significant bottleneck in healthcare research and operations at Ontario Health and InterRAI Canada, requiring extensive expert time and effort. To automate this process while maintaining data privacy, we develop a practical approach using locally deployable large language models (LLMs). Inspired by recent advances in automatic International Classification of Diseases (ICD) coding, our method frames ATC coding as a hierarchical information extraction task, guiding LLMs through the ATC ontology level by level. We evaluate our approach using GPT-4o as an accuracy ceiling and focus development on open-source Llama models suitable for privacy-sensitive deployment. Testing across Health Canada drug product data, the RABBITS benchmark, and real clinical notes from Ontario Health, our method achieves 78% exact match accuracy with GPT-4o and 60% with Llama 3.1 70B. We investigate knowledge grounding through drug definitions, finding modest improvements in accuracy. Further, we show that fine-tuned Llama 3.1 8B matches zero-shot Llama 3.1 70B accuracy, suggesting that effective ATC coding is feasible with smaller models. Our results demonstrate the feasibility of automatic ATC coding in privacy-sensitive healthcare environments, providing a foundation for future deployments.