Granite Guardian
作者: Inkit Padhi, Manish Nagireddy, Giandomenico Cornacchia, Subhajit Chaudhury, Tejaswini Pedapati, Pierre Dognin, Keerthiram Murugesan, Erik Miehling, Martín Santillán Cooper, Kieran Fraser, Giulio Zizzo, Muhammad Zaid Hameed, Mark Purcell, Michael Desmond, Qian Pan, Zahra Ashktorab, Inge Vejsbjerg, Elizabeth M. Daly, Michael Hind, Werner Geyer, Ambrish Rawat, Kush R. Varshney, Prasanna Sattigeri
分类: cs.CL
发布日期: 2024-12-10 (更新: 2024-12-16)
🔗 代码/项目: GITHUB
💡 一句话要点
Granite Guardian:开源LLM安全保障模型,覆盖多维度风险检测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型安全 风险检测 越狱攻击 检索增强生成 幻觉检测 开源模型 人工智能安全
📋 核心要点
- 现有风险检测模型在应对LLM的越狱攻击和检索增强生成(RAG)中的幻觉问题方面存在不足。
- Granite Guardian通过结合人工标注和合成数据训练,全面覆盖社会偏见、不道德行为等多种风险维度。
- 实验表明,Granite Guardian在有害内容和RAG幻觉检测基准测试中表现出色,AUC分别达到0.871和0.854。
📝 摘要(中文)
本文介绍 Granite Guardian 模型,这是一套旨在为提示和响应提供风险检测的安全保障措施,能够与任何大型语言模型 (LLM) 结合使用,实现安全和负责任的使用。这些模型全面覆盖多个风险维度,包括社会偏见、亵渎、暴力、性内容、不道德行为、越狱以及与幻觉相关的风险,例如上下文相关性、依据性和检索增强生成 (RAG) 的答案相关性。Granite Guardian 模型在结合来自不同来源的人工标注和合成数据的独特数据集上进行训练,解决了传统风险检测模型通常忽略的风险,例如越狱和 RAG 特定的问题。在有害内容和 RAG 幻觉相关基准测试中,AUC 分数分别为 0.871 和 0.854,Granite Guardian 是该领域中最具通用性和竞争力的模型。Granite Guardian 以开源形式发布,旨在促进整个社区负责任的 AI 开发。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在实际应用中存在的安全风险问题,包括社会偏见、不道德行为、越狱攻击和检索增强生成(RAG)中的幻觉等。现有风险检测模型通常无法有效识别和缓解这些风险,导致LLM可能产生有害或不准确的输出,影响用户体验和信任度。
核心思路:Granite Guardian的核心思路是构建一套全面的安全保障模型,能够检测和识别LLM在提示和响应中存在的各种风险。通过结合人工标注和合成数据,训练模型识别更广泛的风险类型,包括传统方法难以检测的越狱攻击和RAG幻觉。
技术框架:Granite Guardian的技术框架主要包括数据收集与标注、模型训练和风险评估三个阶段。首先,收集来自不同来源的人工标注数据和合成数据,构建一个包含多种风险类型的数据集。然后,使用该数据集训练一系列风险检测模型,每个模型负责检测特定类型的风险。最后,通过基准测试评估模型的性能,并与其他现有模型进行比较。
关键创新:Granite Guardian最重要的技术创新点在于其全面的风险覆盖和独特的数据集。该模型不仅能够检测传统的有害内容,还能识别越狱攻击和RAG幻觉等新型风险。此外,通过结合人工标注和合成数据,构建了一个更加丰富和多样化的数据集,提高了模型的泛化能力和鲁棒性。
关键设计:论文中没有详细描述具体的参数设置、损失函数和网络结构等技术细节。但是,可以推断,模型可能采用了Transformer架构,并使用了交叉熵损失函数进行训练。此外,为了提高模型的性能,可能还采用了数据增强、正则化和集成学习等技术。
🖼️ 关键图片
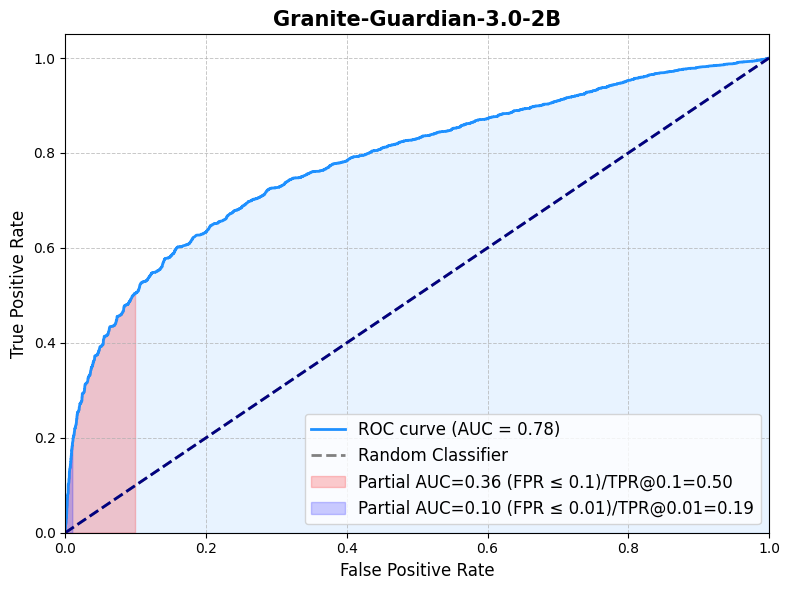


📊 实验亮点
Granite Guardian 在有害内容和 RAG 幻觉相关基准测试中表现出色,AUC 分数分别达到 0.871 和 0.854。这些结果表明,Granite Guardian 在风险检测方面具有很强的竞争力,能够有效识别和缓解 LLM 存在的各种安全风险。相较于其他现有模型,Granite Guardian 具有更强的通用性和泛化能力。
🎯 应用场景
Granite Guardian 可广泛应用于各种基于大型语言模型的应用场景,例如聊天机器人、内容生成、智能助手等。通过集成 Granite Guardian,可以有效降低 LLM 产生有害或不准确输出的风险,提高用户体验和信任度,促进 LLM 的安全和负责任使用。该模型开源发布,也为其他研究者和开发者提供了便利,加速了相关领域的发展。
📄 摘要(原文)
We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian