TRIM: Token Reduction and Inference Modeling for Cost-Effective Language Generation
作者: Alfredo Garrachón Ruiz, Tomás de la Rosa, Daniel Borrajo
分类: cs.CL
发布日期: 2024-12-10 (更新: 2025-11-24)
备注: 16 pages, 9 tables, 5 figures
💡 一句话要点
TRIM:通过Token缩减与推理建模,实现高性价比的语言生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 token缩减 推理优化 文本生成 计算效率
📋 核心要点
- 大型语言模型推理成本高昂,尤其在长文本生成任务中面临挑战,现有方法难以兼顾效率与质量。
- TRIM通过让LLM省略冗余token生成精简文本,再由小型模型重建完整答案,降低整体计算成本。
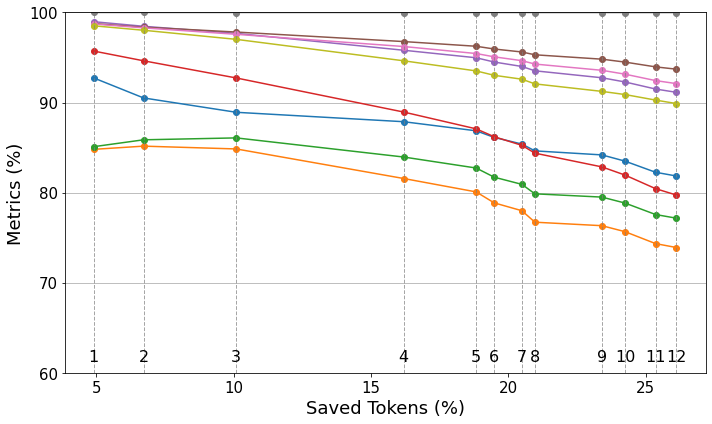
- 实验表明,TRIM在GPT-4o上平均节省19.4%的token,同时评估指标仅略微下降,实现了效率与准确性的平衡。
📝 摘要(中文)
大型语言模型(LLM)的高推理成本带来了挑战,尤其是在需要生成长篇输出的任务中。然而,自然语言通常包含冗余,这为优化提供了机会。我们观察到,通过适当的提示,LLM可以生成精简的语言(即,保留基本含义的简洁输出)。我们提出了TRIM,一种用于节省计算成本的流程,其中LLM在推理过程中省略一组预定义的、语义上不相关且易于根据上下文推断的词。然后,一个经过专门训练的、推理成本较低的小型语言模型将精简后的答案重建为理想的答案。我们的实验显示出有希望的结果,特别是在我们提出的专注于重建任务的NaLDA评估数据集上,GPT-4o平均节省了19.4%的token,而评估指标仅略有下降。这表明该方法可以有效地平衡语言处理任务中的效率和准确性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在生成长文本时推理成本过高的问题。现有方法通常难以在计算效率和生成质量之间取得平衡,尤其是在自然语言中存在大量冗余信息的情况下。如何有效去除冗余信息,降低推理成本,同时保持生成文本的质量是本研究要解决的核心问题。
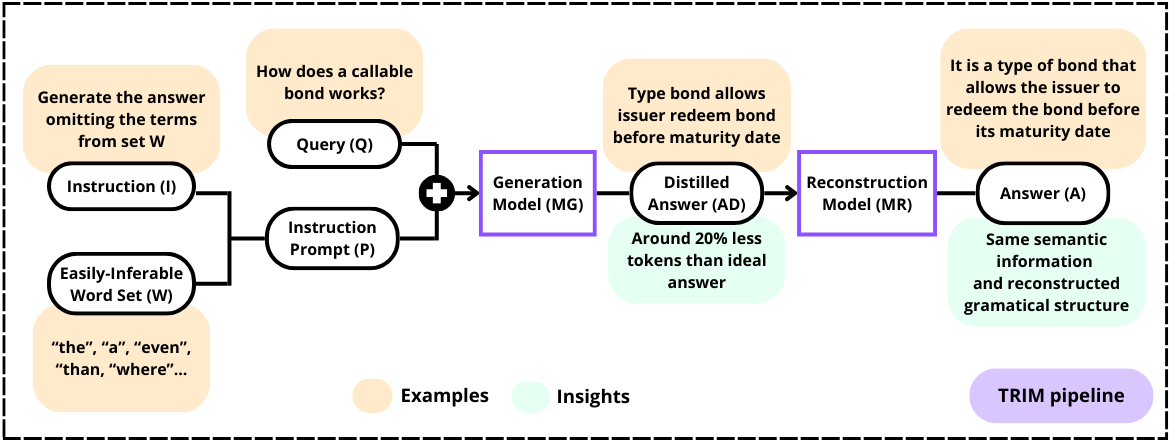
核心思路:TRIM的核心思路是利用LLM本身的能力,通过特定的prompt引导其生成“精简”的文本,即省略那些语义上不重要且容易根据上下文推断出的词语。然后,使用一个专门训练的小型语言模型,将这些精简后的文本“重建”为完整的、理想的答案。这种两阶段的方法旨在将复杂的生成任务分解为两个更易于管理的部分,从而降低整体的计算成本。
技术框架:TRIM包含两个主要阶段:Token缩减阶段和推理建模阶段。在Token缩减阶段,使用大型语言模型(如GPT-4o)接收输入prompt,并根据预定义的规则和上下文信息,省略一部分token,生成精简的文本。在推理建模阶段,使用一个小型语言模型(具体模型未知),该模型经过专门训练,能够将精简的文本作为输入,并重建出完整的、理想的答案。整个流程的关键在于如何定义和选择需要省略的token,以及如何训练小型模型进行有效的文本重建。
关键创新:TRIM的关键创新在于其将LLM的生成过程分解为两个阶段:首先利用LLM的强大能力进行token缩减,然后利用小型模型进行文本重建。这种分解允许在不同的阶段使用不同的模型,从而优化整体的计算效率。与传统的直接生成方法相比,TRIM能够更有效地利用LLM的知识和能力,同时降低推理成本。
关键设计:论文中关键的设计包括:1) 如何定义和选择需要省略的token,这可能涉及到语义分析、上下文理解等技术;2) 如何训练小型语言模型,使其能够有效地将精简的文本重建为完整的答案,这可能涉及到特定的损失函数、网络结构等设计;3) 如何设计prompt,引导LLM生成精简的文本。此外,NaLDA数据集的构建也是一个关键设计,用于评估重建任务的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TRIM方法在GPT-4o上平均节省了19.4%的token,同时评估指标仅略有下降。这一结果表明,TRIM能够在显著降低计算成本的同时,保持生成文本的质量。特别是在NaLDA数据集上的表现,验证了该方法在重建任务上的有效性。
🎯 应用场景
TRIM方法具有广泛的应用前景,尤其适用于对计算资源敏感的场景,如移动设备上的自然语言生成、低功耗嵌入式系统中的文本处理等。该方法可以降低LLM的使用门槛,使其能够在更多资源受限的环境中部署和应用。此外,TRIM还可以应用于对话系统、机器翻译等领域,提高系统的响应速度和效率。
📄 摘要(原文)
The high inference cost of Large Language Models (LLMs) poses challenges, especially for tasks requiring lengthy outputs. However, natural language often contains redundancy, which presents an opportunity for optimization. We have observed that LLMs can generate distilled language (i.e., concise outputs that retain essential meaning) when prompted appropriately. We propose TRIM, a pipeline for saving computational cost in which the LLM omits a predefined set of semantically irrelevant and easily inferable words based on the context during inference. Then, a specifically trained smaller language model with lower inference cost reconstructs the distilled answer into the ideal answer. Our experiments show promising results, particularly on the proposed NaLDA evaluation dataset focused on the reconstruction task, with 19.4% saved tokens on average for GPT-4o and only a tiny decrease in evaluation metrics. This suggests that the approach can effectively balance efficiency and accuracy in language processing tasks.