FlexLLM: Exploring LLM Customization for Moving Target Defense on Black-Box LLMs Against Jailbreak Attacks
作者: Bocheng Chen, Hanqing Guo, Qiben Yan
分类: cs.CR, cs.CL
发布日期: 2024-12-10
💡 一句话要点
FlexLLM:探索LLM定制化,针对黑盒LLM的越狱攻击实施移动目标防御
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 移动目标防御 黑盒防御 解码策略
📋 核心要点
- 现有LLM防御方法通常需要访问模型内部结构或进行额外训练,这对于使用API的服务提供商不切实际。
- 论文提出一种移动目标防御方法,通过动态调整解码超参数和系统提示,增强模型对越狱攻击的鲁棒性。
- 实验结果表明,该防御方法在多个测试模型中对越狱攻击有效,同时降低了推理成本并保持了响应质量。
📝 摘要(中文)
大型语言模型(LLM)的防御对于对抗利用这些系统通过恶意提示(即越狱攻击)生成有害内容的攻击者至关重要。虽然已经提出了许多防御策略,但它们通常需要访问模型的内部结构或额外的训练,这对于使用LLM API(如OpenAI API或Claude API)的服务提供商来说是不切实际的。本文提出了一种移动目标防御方法,通过改变解码超参数来增强模型对各种越狱攻击的鲁棒性。该方法不需要访问模型的内部结构,也不产生额外的训练成本。提出的防御包括两个关键组成部分:(1)通过识别和调整影响token生成概率的解码超参数来优化解码策略;(2)将解码超参数和模型系统提示转换为动态目标,在每次运行时不断改变。通过不断修改解码策略和提示,该防御有效地缓解了现有攻击。结果表明,在使用LLM作为黑盒API时,我们的防御在三个测试模型中对越狱攻击最有效。此外,我们的防御提供了更低的推理成本,并保持了相当的响应质量,使其成为与其他防御方法一起使用时潜在的保护层。
🔬 方法详解
问题定义:论文旨在解决黑盒LLM在面对越狱攻击时防御能力不足的问题。现有防御方法通常依赖于模型内部信息或需要额外的训练,这对于通过API使用LLM的服务提供商来说是不现实的。因此,如何在不访问模型内部结构和不进行额外训练的情况下,有效防御越狱攻击是一个挑战。
核心思路:论文的核心思路是通过移动目标防御来增强LLM的鲁棒性。具体来说,通过动态改变解码超参数和系统提示,使得攻击者难以找到稳定的攻击策略。这种方法类似于在网络安全中使用的移动目标防御,通过不断变化防御策略来迷惑攻击者。
技术框架:该防御框架主要包含两个阶段:解码策略优化和动态目标转换。首先,通过分析解码超参数对token生成概率的影响,选择合适的超参数进行调整。然后,将解码超参数和系统提示转换为动态目标,在每次运行时随机改变这些参数,从而实现移动目标防御。
关键创新:该方法最重要的创新点在于将移动目标防御的思想应用于黑盒LLM的越狱攻击防御。与传统的静态防御方法不同,该方法通过不断变化防御策略,增加了攻击的难度,提高了防御的有效性。此外,该方法不需要访问模型内部结构和进行额外训练,具有很强的实用性。
关键设计:解码超参数的选择和调整是关键。论文分析了temperature、top_p、top_k等超参数对token生成概率的影响,并设计了一种优化算法来选择合适的超参数组合。此外,系统提示的动态转换也需要精心设计,以保证模型在防御攻击的同时,仍然能够生成高质量的响应。
🖼️ 关键图片

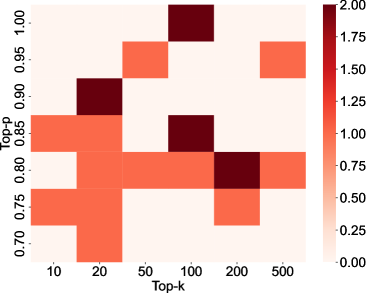
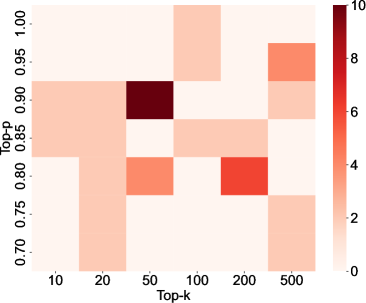
📊 实验亮点
实验结果表明,该防御方法在三个测试模型中对越狱攻击表现出最强的防御能力。与现有防御方法相比,该方法在防御效果上具有显著优势,同时降低了推理成本,并保持了相当的响应质量。具体性能数据未知,但结论表明该方法是一种有效的黑盒LLM越狱攻击防御方案。
🎯 应用场景
该研究成果可应用于各种基于LLM API的服务,例如聊天机器人、内容生成平台等。通过部署该防御方法,可以有效提高这些服务对恶意攻击的抵抗能力,保障用户安全和平台稳定。未来,该方法还可以扩展到其他类型的攻击防御,例如对抗样本攻击等,具有广阔的应用前景。
📄 摘要(原文)
Defense in large language models (LLMs) is crucial to counter the numerous attackers exploiting these systems to generate harmful content through manipulated prompts, known as jailbreak attacks. Although many defense strategies have been proposed, they often require access to the model's internal structure or need additional training, which is impractical for service providers using LLM APIs, such as OpenAI APIs or Claude APIs. In this paper, we propose a moving target defense approach that alters decoding hyperparameters to enhance model robustness against various jailbreak attacks. Our approach does not require access to the model's internal structure and incurs no additional training costs. The proposed defense includes two key components: (1) optimizing the decoding strategy by identifying and adjusting decoding hyperparameters that influence token generation probabilities, and (2) transforming the decoding hyperparameters and model system prompts into dynamic targets, which are continuously altered during each runtime. By continuously modifying decoding strategies and prompts, the defense effectively mitigates the existing attacks. Our results demonstrate that our defense is the most effective against jailbreak attacks in three of the models tested when using LLMs as black-box APIs. Moreover, our defense offers lower inference costs and maintains comparable response quality, making it a potential layer of protection when used alongside other defense methods.