Bilingual BSARD: Extending Statutory Article Retrieval to Dutch
作者: Ehsan Lotfi, Nikolay Banar, Nerses Yuzbashyan, Walter Daelemans
分类: cs.CL, cs.IR
发布日期: 2024-12-10
备注: To be presented at RegNLP-2025 (COLING)
💡 一句话要点
提出bBSARD:扩展法规条文检索至荷兰语,并benchmark多种检索模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 法规条文检索 多语种检索 荷兰语 法律信息检索 双语数据集 BM25 零样本学习
📋 核心要点
- 多语种国家的法律信息检索面临挑战,需要处理多种语言的法律条文。
- 构建了bBSARD双语数据集,包含法语和荷兰语的平行法规条文及法律问题。
- 通过benchmark实验,发现BM25是强劲基线,微调小型语言模型可匹敌专有模型。
📝 摘要(中文)
法规条文检索在使法律信息更易于大众和法律专业人士获取方面起着关键作用。像比利时这样的多语种国家,由于需要处理多种语言的法律问题,给检索模型带来了独特的挑战。在法语比利时法规条文检索数据集(BSARD)的基础上,我们推出了该数据集的双语版本bBSARD。该数据集包含法语和荷兰语的比利时平行法规条文,以及来自BSARD的法律问题及其荷兰语翻译。利用bBSARD,我们对适用于荷兰语和法语的检索模型进行了广泛的基准测试。我们的基准测试设置包括词汇模型、零样本密集模型和微调的小型基础模型。实验表明,与许多零样本密集模型相比,BM25在两种语言中仍然是一个有竞争力的基线。我们还观察到,虽然专有模型在零样本设置中优于开放替代方案,但可以通过微调小型特定语言模型来匹配或超越它们。我们的数据集和评估代码已公开。
🔬 方法详解
问题定义:论文旨在解决多语种环境下,特别是比利时法语和荷兰语法律条文的检索问题。现有方法在跨语言法律检索方面存在不足,难以有效处理不同语言的法律文本,并且缺乏针对荷兰语法律条文检索的专用数据集。
核心思路:论文的核心思路是构建一个双语数据集bBSARD,包含法语和荷兰语的平行法律条文和问题,从而能够对现有的检索模型在多语种法律检索场景下进行有效评估和比较。通过benchmark实验,分析不同模型的性能,并探索如何通过微调小型语言模型来提升检索效果。
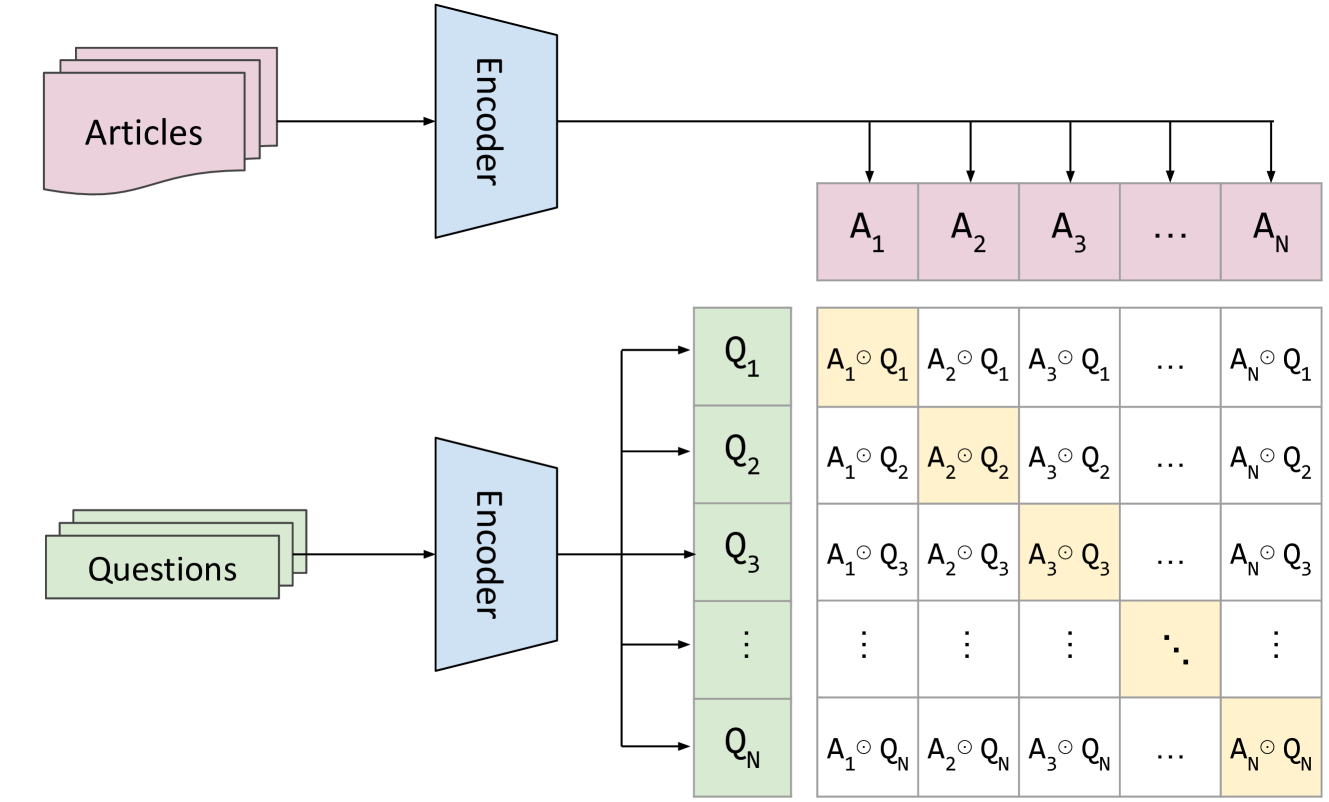
技术框架:论文的技术框架主要包括以下几个部分:1) 构建bBSARD数据集,包括法语和荷兰语的平行法律条文和问题;2) 选择一系列检索模型,包括词汇模型(如BM25)、零样本密集模型和微调的小型基础模型;3) 在bBSARD数据集上对这些模型进行benchmark测试;4) 分析实验结果,比较不同模型的性能,并探讨如何通过微调来提升模型效果。
关键创新:论文的关键创新在于构建了bBSARD双语数据集,为多语种法律检索研究提供了一个新的资源。此外,论文还通过benchmark实验,系统地比较了不同检索模型在多语种法律检索场景下的性能,并验证了微调小型语言模型在提升检索效果方面的潜力。
关键设计:论文的关键设计包括:1) 数据集的构建方式,确保法语和荷兰语法律条文的平行性;2) 检索模型的选择,涵盖了词汇模型、零样本密集模型和微调的小型基础模型;3) 实验评估指标的选择,用于全面评估不同模型的检索性能;4) 微调策略的设计,探索如何有效地利用bBSARD数据集来提升小型语言模型的检索效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,BM25在法语和荷兰语中都是一个具有竞争力的基线。虽然专有模型在零样本设置中表现优异,但通过在bBSARD数据集上微调小型特定语言模型,可以达到甚至超过专有模型的性能。例如,微调后的模型在检索准确率上取得了显著提升,缩小了与专有模型的差距。
🎯 应用场景
该研究成果可应用于多语种国家的法律信息检索系统,例如比利时、加拿大等。通过构建高效的跨语言法律检索系统,可以帮助法律专业人士和普通民众更便捷地获取所需的法律信息,提高法律服务的效率和质量。未来,该研究可以扩展到更多语种和法律领域,构建更加完善的多语种法律知识库。
📄 摘要(原文)
Statutory article retrieval plays a crucial role in making legal information more accessible to both laypeople and legal professionals. Multilingual countries like Belgium present unique challenges for retrieval models due to the need for handling legal issues in multiple languages. Building on the Belgian Statutory Article Retrieval Dataset (BSARD) in French, we introduce the bilingual version of this dataset, bBSARD. The dataset contains parallel Belgian statutory articles in both French and Dutch, along with legal questions from BSARD and their Dutch translation. Using bBSARD, we conduct extensive benchmarking of retrieval models available for Dutch and French. Our benchmarking setup includes lexical models, zero-shot dense models, and fine-tuned small foundation models. Our experiments show that BM25 remains a competitive baseline compared to many zero-shot dense models in both languages. We also observe that while proprietary models outperform open alternatives in the zero-shot setting, they can be matched or surpassed by fine-tuning small language-specific models. Our dataset and evaluation code are publicly available.