Generating Knowledge Graphs from Large Language Models: A Comparative Study of GPT-4, LLaMA 2, and BERT
作者: Ahan Bhatt, Nandan Vaghela, Kush Dudhia
分类: cs.CL, cs.AI, cs.DB
发布日期: 2024-12-10
备注: 4 pages, 4 figures, 3 tables
💡 一句话要点
利用大型语言模型生成知识图谱,提升GraphRAG性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱生成 大型语言模型 GraphRAG GPT-4 LLaMA 2 BERT 非结构化数据 实体关系抽取
📋 核心要点
- 传统知识图谱构建方法在准确性和可扩展性方面存在瓶颈,难以满足GraphRAG对高质量知识图谱的需求。
- 该论文提出利用大型语言模型直接从非结构化数据生成知识图谱,无需复杂的传统流程,简化了构建过程。
- 实验结果表明,GPT-4在语义保真度和结构准确性方面表现优异,LLaMA 2擅长生成轻量级领域知识图谱。
📝 摘要(中文)
知识图谱(KGs)对于GraphRAGs的功能至关重要,GraphRAGs是一种检索增强生成系统(RAGs),擅长需要结构化推理和语义理解的任务。然而,由于传统方法在准确性和可扩展性方面的限制,为GraphRAGs创建KGs仍然是一个重大挑战。本文提出了一种新方法,利用大型语言模型(LLMs),如GPT-4、LLaMA 2 (13B)和BERT,直接从非结构化数据生成KGs,绕过了传统的流程。使用精确率、召回率、F1分数、图编辑距离和语义相似度等指标,我们评估了模型生成高质量KGs的能力。结果表明,GPT-4在语义保真度和结构准确性方面表现出色,LLaMA 2在轻量级、特定领域的图方面表现出色,而BERT提供了对实体关系建模挑战的见解。这项研究强调了LLMs在简化KG创建和增强GraphRAG在实际应用中的可访问性的潜力,同时也为未来的发展奠定了基础。
🔬 方法详解
问题定义:论文旨在解决从非结构化数据中高效、准确地生成知识图谱的问题。传统知识图谱构建方法依赖于复杂的人工标注和规则定义,成本高昂且难以扩展,无法满足GraphRAG等应用对大规模、高质量知识图谱的需求。现有方法在处理复杂语义关系和长文本信息时表现不足,容易引入噪声和错误。
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的文本理解和生成能力,直接从非结构化文本中抽取实体和关系,自动构建知识图谱。这种方法避免了传统流程中繁琐的人工干预,提高了知识图谱构建的效率和可扩展性。
技术框架:该研究的技术框架主要包括三个阶段:1) 数据准备:收集和清洗非结构化文本数据;2) 知识图谱生成:使用GPT-4、LLaMA 2和BERT等LLM模型,从文本中抽取实体和关系,构建知识图谱;3) 评估:使用精确率、召回率、F1分数、图编辑距离和语义相似度等指标,评估生成的知识图谱的质量。
关键创新:该论文的关键创新在于直接利用LLM进行知识图谱生成,无需传统知识图谱构建流程中的实体识别、关系抽取等独立模块。这种端到端的方法简化了流程,并充分利用了LLM的上下文理解能力,提高了知识图谱的质量。与现有方法相比,该方法更具通用性和可扩展性。
关键设计:论文中,针对不同的LLM模型,采用了不同的prompt工程策略,以引导模型生成高质量的知识图谱。例如,针对GPT-4,设计了详细的指令,明确要求模型输出三元组形式的知识图谱。此外,论文还采用了多种评估指标,全面评估了不同LLM模型生成的知识图谱的质量。
🖼️ 关键图片
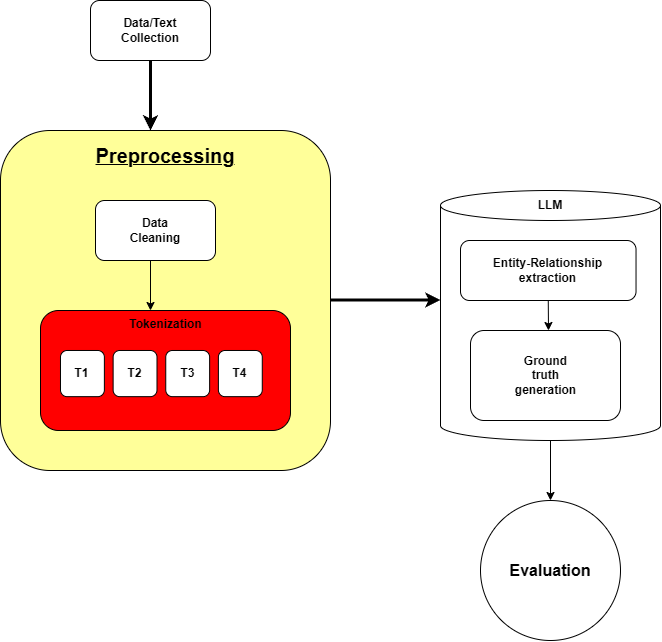

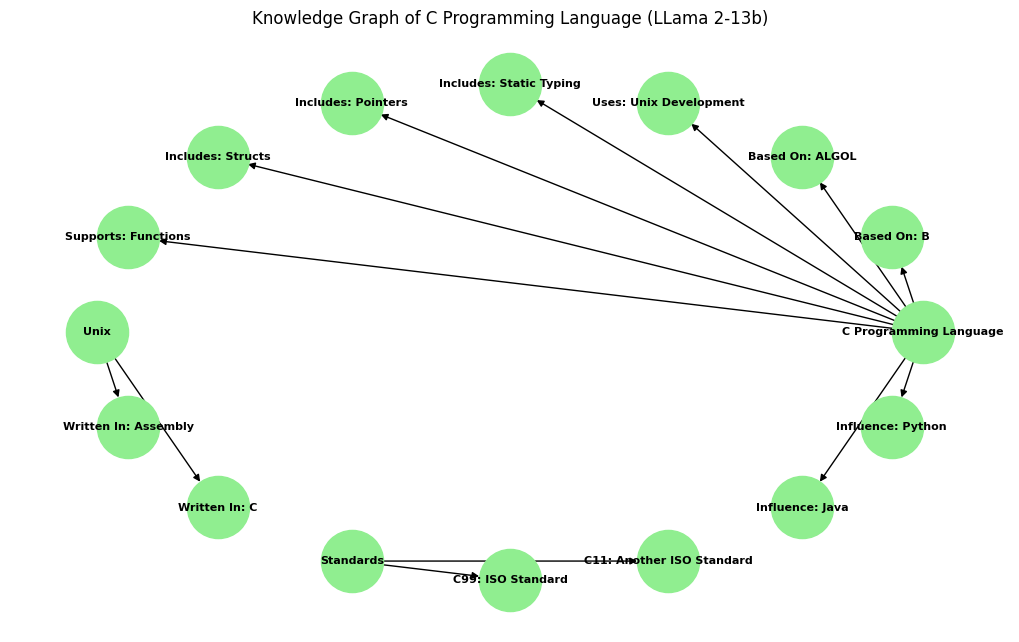
📊 实验亮点
实验结果表明,GPT-4在知识图谱生成方面表现最佳,在语义保真度和结构准确性方面均优于LLaMA 2和BERT。LLaMA 2在生成轻量级、特定领域的知识图谱方面表现出色。BERT在实体关系建模方面面临挑战,但为未来的研究提供了有价值的见解。该研究为利用LLM构建知识图谱提供了有力的证据。
🎯 应用场景
该研究成果可广泛应用于GraphRAG、智能问答、信息检索、推荐系统等领域。通过利用LLM自动构建知识图谱,可以降低知识图谱构建成本,提高知识图谱的覆盖范围和质量,从而提升下游应用的性能。未来,该方法有望应用于构建特定领域的知识图谱,例如医疗、金融等。
📄 摘要(原文)
Knowledge Graphs (KGs) are essential for the functionality of GraphRAGs, a form of Retrieval-Augmented Generative Systems (RAGs) that excel in tasks requiring structured reasoning and semantic understanding. However, creating KGs for GraphRAGs remains a significant challenge due to accuracy and scalability limitations of traditional methods. This paper introduces a novel approach leveraging large language models (LLMs) like GPT-4, LLaMA 2 (13B), and BERT to generate KGs directly from unstructured data, bypassing traditional pipelines. Using metrics such as Precision, Recall, F1-Score, Graph Edit Distance, and Semantic Similarity, we evaluate the models' ability to generate high-quality KGs. Results demonstrate that GPT-4 achieves superior semantic fidelity and structural accuracy, LLaMA 2 excels in lightweight, domain-specific graphs, and BERT provides insights into challenges in entity-relationship modeling. This study underscores the potential of LLMs to streamline KG creation and enhance GraphRAG accessibility for real-world applications, while setting a foundation for future advancements.