CMT: A Memory Compression Method for Continual Knowledge Learning of Large Language Models
作者: Dongfang Li, Zetian Sun, Xinshuo Hu, Baotian Hu, Min Zhang
分类: cs.CL, cs.AI
发布日期: 2024-12-10
备注: AAAI 2025; Pre-print
💡 一句话要点
提出CMT:一种面向大语言模型持续知识学习的记忆压缩方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 大型语言模型 知识保留 记忆压缩 在线学习
📋 核心要点
- 大型语言模型需要持续学习新知识,但全量微调成本高昂且易发生灾难性遗忘。
- CMT方法通过压缩新文档信息到记忆库,并在推理时聚合相关记忆来更新知识,无需修改LLM参数。
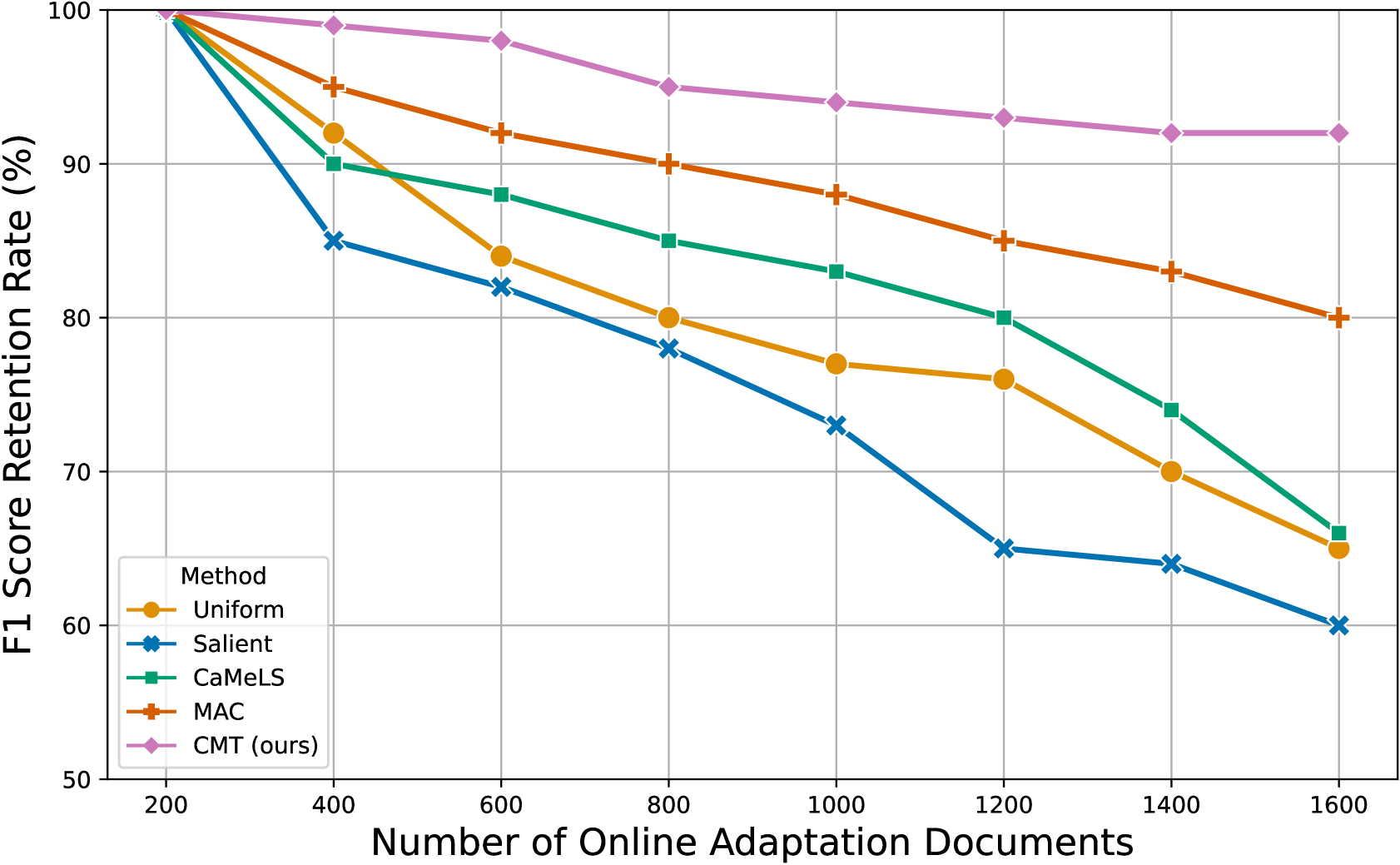
- 实验表明,CMT在多个数据集和LLM上均能有效提升模型适应性和鲁棒性,例如在StreamingQA数据集上使用Llama-2-7b模型时,EM和F1指标分别提升了4.07和4.19。
📝 摘要(中文)
大型语言模型(LLMs)需要适应数据、任务和用户偏好的持续变化。由于其庞大的规模和相关的训练成本,LLMs不适合频繁的重新训练。然而,更新对于使其与快速发展的人类知识保持同步是必要的。为了应对这些挑战,本文提出了一种压缩记忆训练(CMT)方法,这是一种高效且有效的LLMs在线自适应框架,具有强大的知识保留能力。受到人类记忆机制的启发,CMT压缩并提取新文档中的信息,存储在记忆库中。当回答与这些新文档相关的查询时,模型会聚合来自记忆库的这些文档记忆,以更好地回答用户问题。LLM本身的参数在训练和推理过程中不会改变,从而降低了灾难性遗忘的风险。为了增强记忆的编码、检索和聚合,我们进一步提出了三种新的通用且灵活的技术,包括记忆感知目标、自匹配和顶部聚合。在三个持续学习数据集(即StreamingQA、SQuAD和ArchivalQA)上进行的大量实验表明,所提出的方法提高了模型在多个基础LLMs上的适应性和鲁棒性(例如,在使用Llama-2-7b的StreamingQA中,EM提高+4.07,F1提高+4.19)。
🔬 方法详解
问题定义:大型语言模型需要不断学习新的知识以适应快速变化的世界,但由于模型参数量巨大,全量微调的成本非常高昂。此外,频繁的微调容易导致灾难性遗忘,即模型忘记之前学习过的知识。现有方法难以在效率和知识保留之间取得平衡。
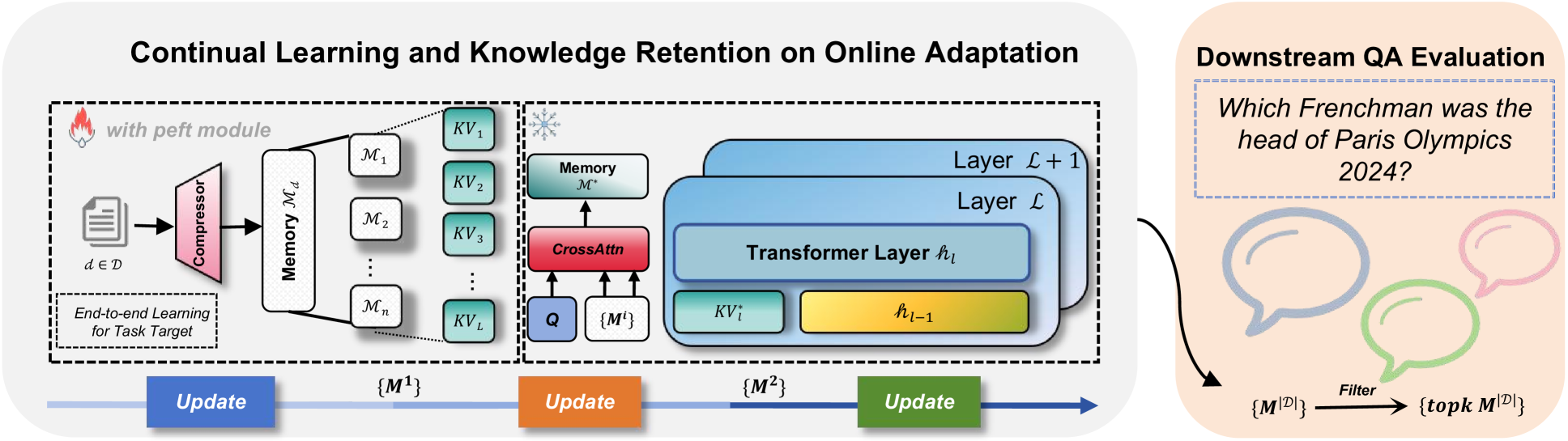
核心思路:CMT方法的核心思想是借鉴人类的记忆机制,将新知识压缩并存储到外部记忆库中,而不是直接修改LLM的参数。在回答问题时,模型从记忆库中检索相关信息,并将其与原始知识结合起来,从而实现知识的更新和增强,同时避免灾难性遗忘。
技术框架:CMT方法包含以下几个主要模块:1) 记忆压缩:将新文档压缩成向量表示,存储到记忆库中。2) 记忆检索:根据用户查询,从记忆库中检索相关的记忆向量。3) 记忆聚合:将检索到的记忆向量与原始LLM的知识结合起来,生成最终的答案。整个过程中,LLM本身的参数保持不变。
关键创新:CMT的关键创新在于:1) 记忆压缩:设计高效的压缩算法,将新知识压缩成紧凑的向量表示。2) 记忆检索:提出有效的检索策略,快速准确地找到相关的记忆。3) 记忆聚合:开发合适的聚合机制,将检索到的记忆与LLM的知识融合,避免信息冲突。此外,论文还提出了记忆感知目标、自匹配和顶部聚合等技术来增强记忆的编码、检索和聚合。
关键设计:论文提出了三种关键技术:1) 记忆感知目标:在训练记忆编码器时,引入额外的损失函数,鼓励编码器学习到对下游任务有用的记忆表示。2) 自匹配:利用自注意力机制,增强记忆向量之间的关联性,提高检索的准确性。3) 顶部聚合:只选择最相关的几个记忆向量进行聚合,避免噪声信息的干扰。具体的参数设置和损失函数细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CMT方法在三个持续学习数据集(StreamingQA、SQuAD和ArchivalQA)上均取得了显著的性能提升。例如,在使用Llama-2-7b作为基础LLM的StreamingQA数据集上,CMT方法使EM指标提高了4.07,F1指标提高了4.19。此外,实验还证明了CMT方法具有良好的鲁棒性,可以适应不同的基础LLM。
🎯 应用场景
CMT方法可应用于各种需要持续知识学习的场景,例如:智能客服、知识问答、信息检索等。它可以帮助LLM及时更新知识,提高回答的准确性和相关性,从而提升用户体验。此外,CMT方法还可以用于构建个性化的知识库,根据用户的兴趣和需求,存储和检索相关的知识。
📄 摘要(原文)
Large Language Models (LLMs) need to adapt to the continuous changes in data, tasks, and user preferences. Due to their massive size and the high costs associated with training, LLMs are not suitable for frequent retraining. However, updates are necessary to keep them in sync with rapidly evolving human knowledge. To address these challenges, this paper proposes the Compression Memory Training (CMT) method, an efficient and effective online adaptation framework for LLMs that features robust knowledge retention capabilities. Inspired by human memory mechanisms, CMT compresses and extracts information from new documents to be stored in a memory bank. When answering to queries related to these new documents, the model aggregates these document memories from the memory bank to better answer user questions. The parameters of the LLM itself do not change during training and inference, reducing the risk of catastrophic forgetting. To enhance the encoding, retrieval, and aggregation of memory, we further propose three new general and flexible techniques, including memory-aware objective, self-matching and top-aggregation. Extensive experiments conducted on three continual learning datasets (i.e., StreamingQA, SQuAD and ArchivalQA) demonstrate that the proposed method improves model adaptability and robustness across multiple base LLMs (e.g., +4.07 EM & +4.19 F1 in StreamingQA with Llama-2-7b).