SpecFuse: Ensembling Large Language Models via Next-Segment Prediction
作者: Bo Lv, Chen Tang, Yanan Zhang, Xin Liu, Yue Yu, Ping Luo
分类: cs.CL, cs.AI
发布日期: 2024-12-10 (更新: 2025-02-19)
备注: 15 pages, 5 figures
💡 一句话要点
SpecFuse:通过下一片段预测集成大型语言模型,提升生成质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型集成 文本生成 协同生成 模型融合 下一片段预测 模型退出机制
📋 核心要点
- 现有LLM集成方法侧重于训练额外的融合模型来组合完整回复,未能充分利用LLM的协作潜力。
- SpecFuse通过迭代生成下一片段的方式,促使LLM协同工作,无需额外训练即可实现模型集成。
- SpecFuse引入模型退出机制,动态排除表现不佳的模型,在保证性能的同时降低计算成本。
📝 摘要(中文)
本文提出了一种新颖的集成框架SpecFuse,它通过大型语言模型(LLM)之间的协作,迭代地生成下一个片段,从而输出融合结果。SpecFuse通过循环执行推理和验证组件来实现这一目标。在每一轮中,推理组件并行调用每个基础LLM以生成候选片段,验证组件再次调用这些LLM来预测片段的排名。排名最高的片段随后被广播到所有LLM,鼓励它们在下一轮中生成更高质量的片段。这种方法还允许基础LLM即插即用,无需任何训练或调整,避免了泛化限制。此外,为了节省计算资源,本文提出了一种模型退出机制,该机制在每个查询响应期间动态排除在先前轮次中表现不佳的模型,从而有效地减少了模型调用次数,同时保持了整体性能。
🔬 方法详解
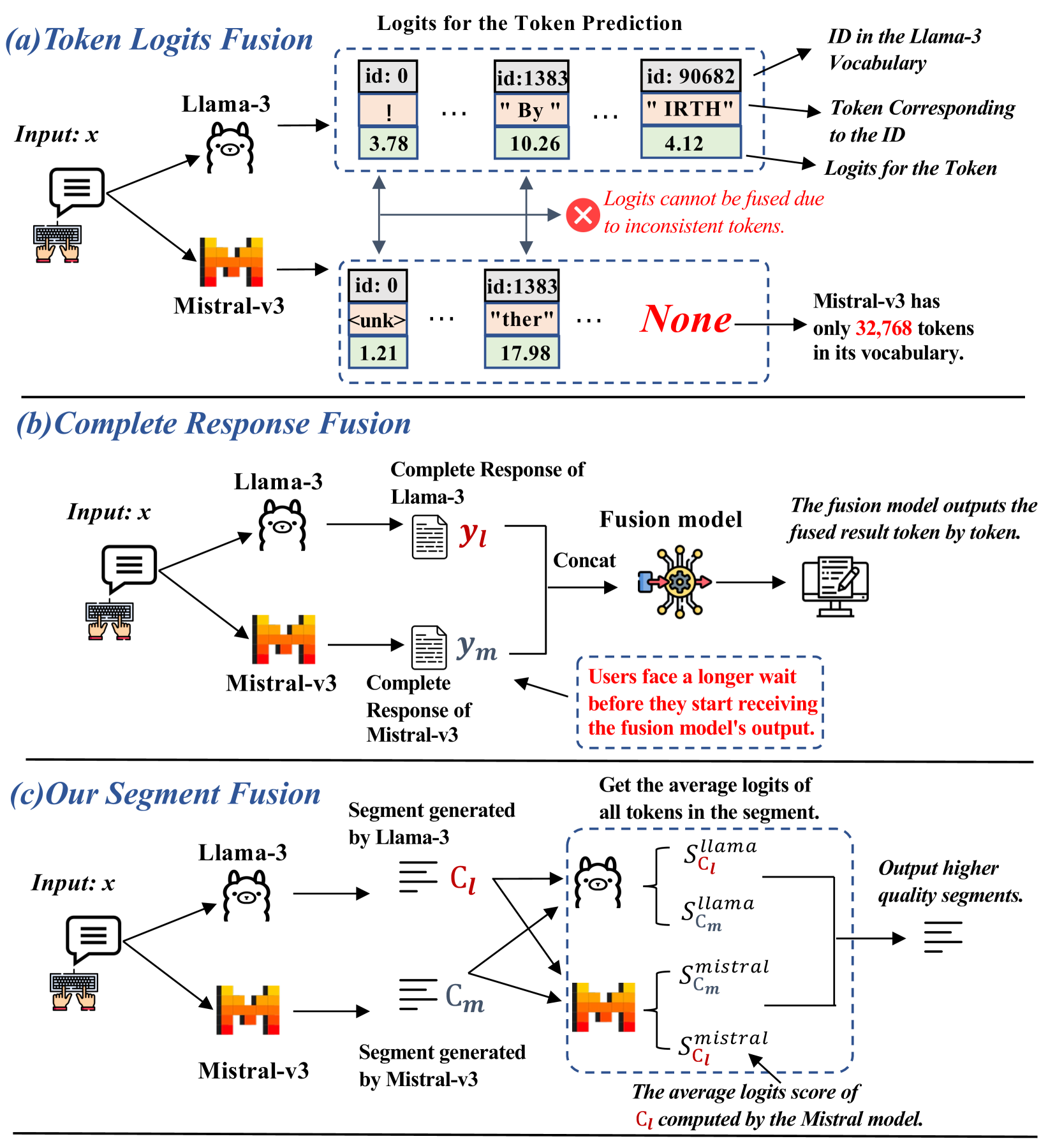
问题定义:现有的大型语言模型集成方法通常训练一个额外的融合模型,该模型以各个LLM的完整输出作为输入,然后生成最终的融合结果。这种方法存在两个主要问题:一是未能充分利用LLM之间的协作潜力,各个LLM独立生成结果,融合模型只是简单地进行组合;二是融合模型需要在特定的数据集上进行训练,这限制了其在开放领域查询中的泛化能力。
核心思路:SpecFuse的核心思路是通过迭代地生成下一个片段,促使LLM之间进行协作。具体来说,SpecFuse不是直接融合各个LLM的完整输出,而是让它们在每一轮迭代中共同生成一个片段,并将该片段广播给所有LLM,作为下一轮迭代的上下文。通过这种方式,LLM可以相互学习,共同提高生成质量。
技术框架:SpecFuse的整体框架包含两个主要组件:推理组件和验证组件。推理组件负责并行调用各个基础LLM,让它们根据当前的上下文生成候选片段。验证组件负责对这些候选片段进行排序,选择排名最高的片段作为当前轮次的输出。然后,将该片段广播给所有LLM,作为下一轮迭代的上下文。这个过程会循环执行,直到生成完整的响应。此外,SpecFuse还包含一个模型退出机制,该机制会动态地排除在先前轮次中表现不佳的模型,以节省计算资源。
关键创新:SpecFuse的关键创新在于其迭代式的生成方式,以及LLM之间的协作机制。与传统的融合方法不同,SpecFuse不是简单地组合各个LLM的输出,而是让它们在每一轮迭代中共同生成一个片段,并通过广播机制进行信息共享。这种方式可以充分利用LLM之间的协作潜力,提高生成质量。此外,SpecFuse的模型退出机制也可以有效地节省计算资源。
关键设计:SpecFuse的关键设计包括:1) 推理组件中,每个LLM生成候选片段的方式,可以使用不同的采样策略或解码算法;2) 验证组件中,对候选片段进行排序的方式,可以使用LLM自身的预测能力,也可以使用额外的排序模型;3) 模型退出机制中,判断模型表现的标准,可以使用生成片段的质量、一致性等指标;4) 迭代的停止条件,可以使用生成文本的长度、质量等指标。
🖼️ 关键图片

📊 实验亮点
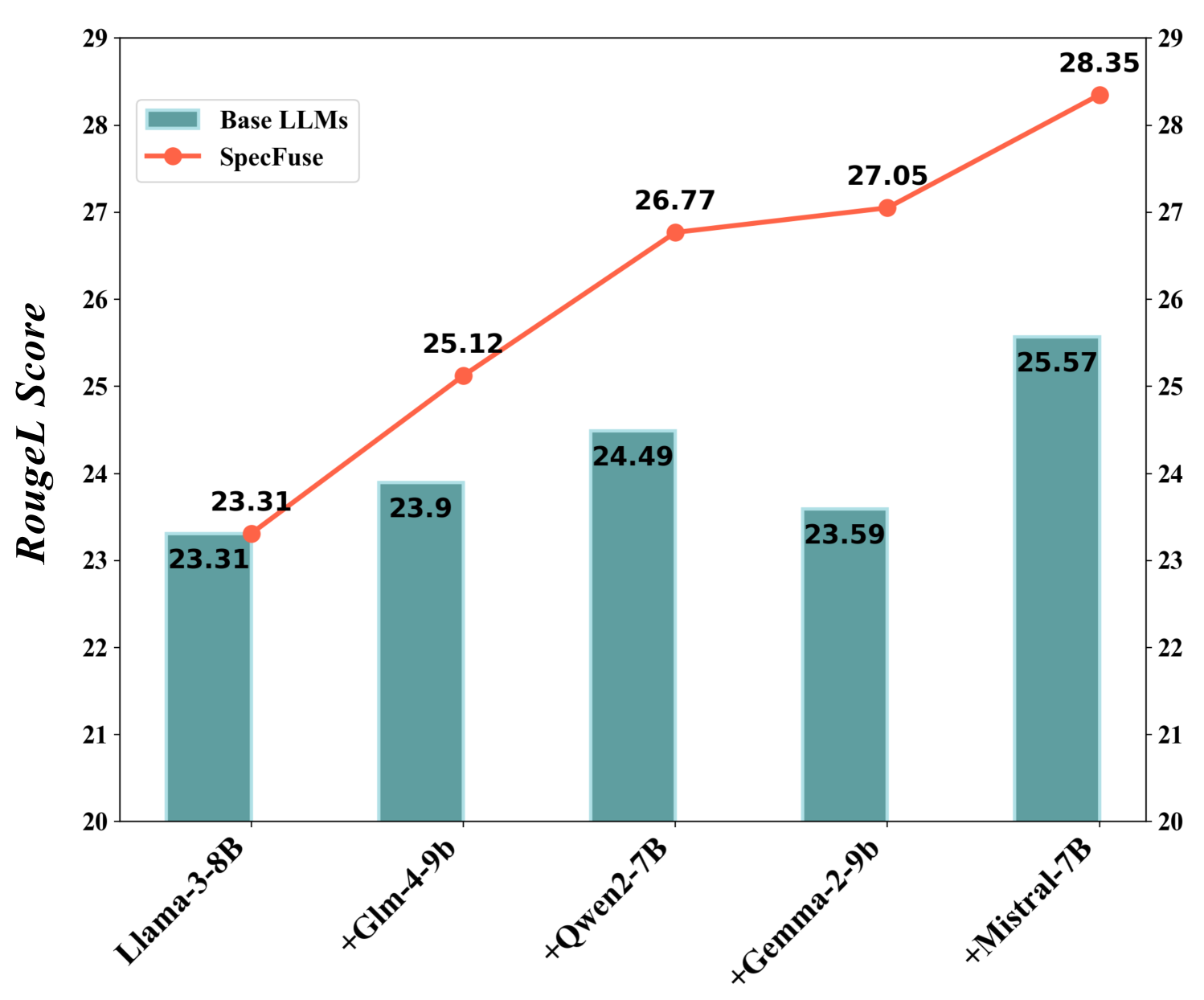
论文提出的SpecFuse框架无需训练额外的融合模型,即可有效集成多个LLM。通过迭代生成和模型退出机制,SpecFuse在保证生成质量的同时,降低了计算成本。实验结果(具体数据未知)表明,SpecFuse在多个文本生成任务上取得了显著的性能提升,优于现有的融合方法。
🎯 应用场景
SpecFuse可应用于各种需要高质量文本生成的场景,例如智能客服、机器翻译、内容创作等。通过集成多个LLM的优势,SpecFuse可以生成更准确、更流畅、更具创造性的文本,提升用户体验。此外,SpecFuse的即插即用特性使其易于部署和扩展,可以方便地集成到现有的文本生成系统中。
📄 摘要(原文)
Ensembles of generative large language models (LLMs) can integrate the strengths of different LLMs to compensate for the limitations of individual models. However, recent work has focused on training an additional fusion model to combine complete responses from multiple LLMs, failing to tap into their collaborative potential to generate higher-quality responses. Moreover, as the additional fusion model is trained on a specialized dataset, these methods struggle with generalizing to open-domain queries from online users. In this paper, we propose SpecFuse, a novel ensemble framework that outputs the fused result by iteratively producing the next segment through collaboration among LLMs. This is achieved through cyclic execution of its inference and verification components. In each round, the inference component invokes each base LLM to generate candidate segments in parallel, and the verify component calls these LLMs again to predict the ranking of the segments. The top-ranked segment is then broadcast to all LLMs, encouraging them to generate higher-quality segments in the next round. This approach also allows the base LLMs to be plug-and-play, without any training or adaptation, avoiding generalization limitations. Furthermore, to conserve computational resources, we propose a model exit mechanism that dynamically excludes models exhibiting poor performance in previous rounds during each query response. In this way, it effectively reduces the number of model calls while maintaining overall performance.