The Rise and Down of Babel Tower: Investigating the Evolution Process of Multilingual Code Large Language Model
作者: Jiawei Chen, Wentao Chen, Jing Su, Jingjing Xu, Hongyu Lin, Mengjie Ren, Yaojie Lu, Xianpei Han, Le Sun
分类: cs.CL
发布日期: 2024-12-10 (更新: 2025-03-03)
备注: Accepted to ICLR 2025
💡 一句话要点
提出“巴别塔假说”,揭示多语言代码大模型能力演进过程并优化预训练语料。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 代码大模型 预训练 巴别塔假说 语言演进 神经元分析 语料优化
📋 核心要点
- 现有研究对LLM多语言能力在预训练过程中的演进机制理解不足,缺乏有效指导。
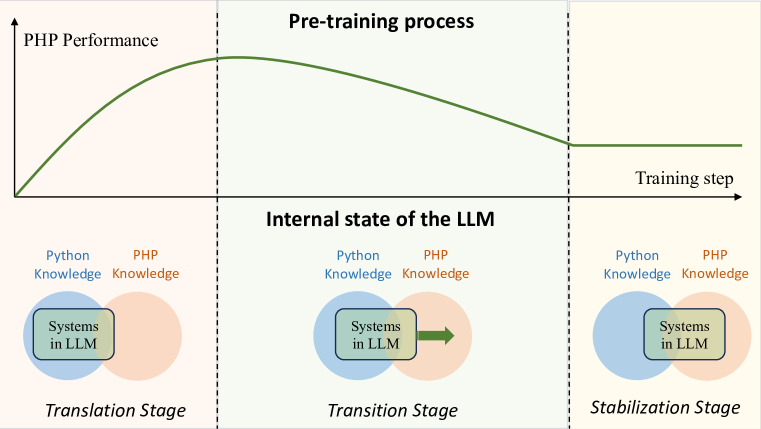
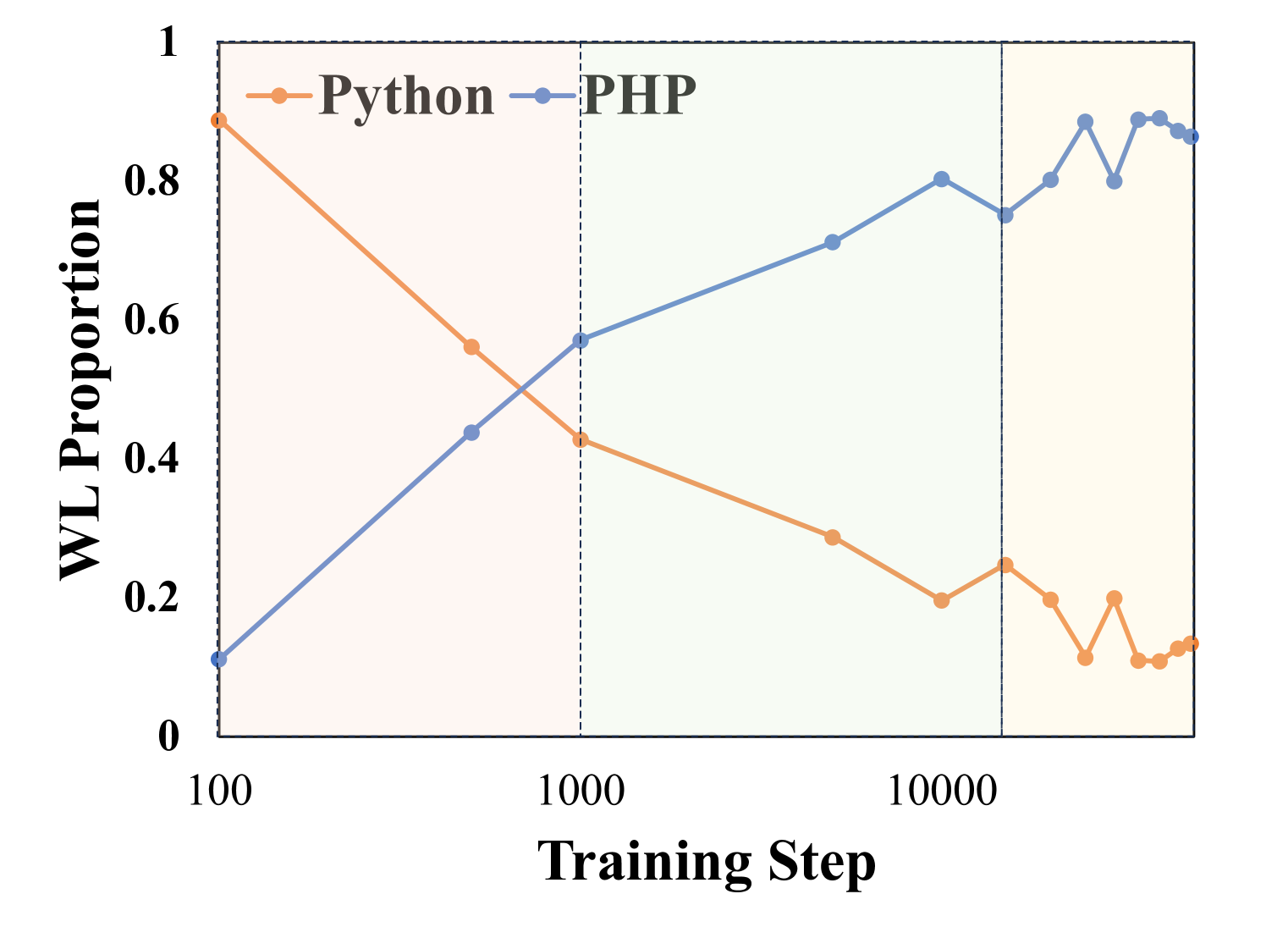
- 论文提出“巴别塔假说”,认为LLM从共享知识系统到发展语言特定知识系统。
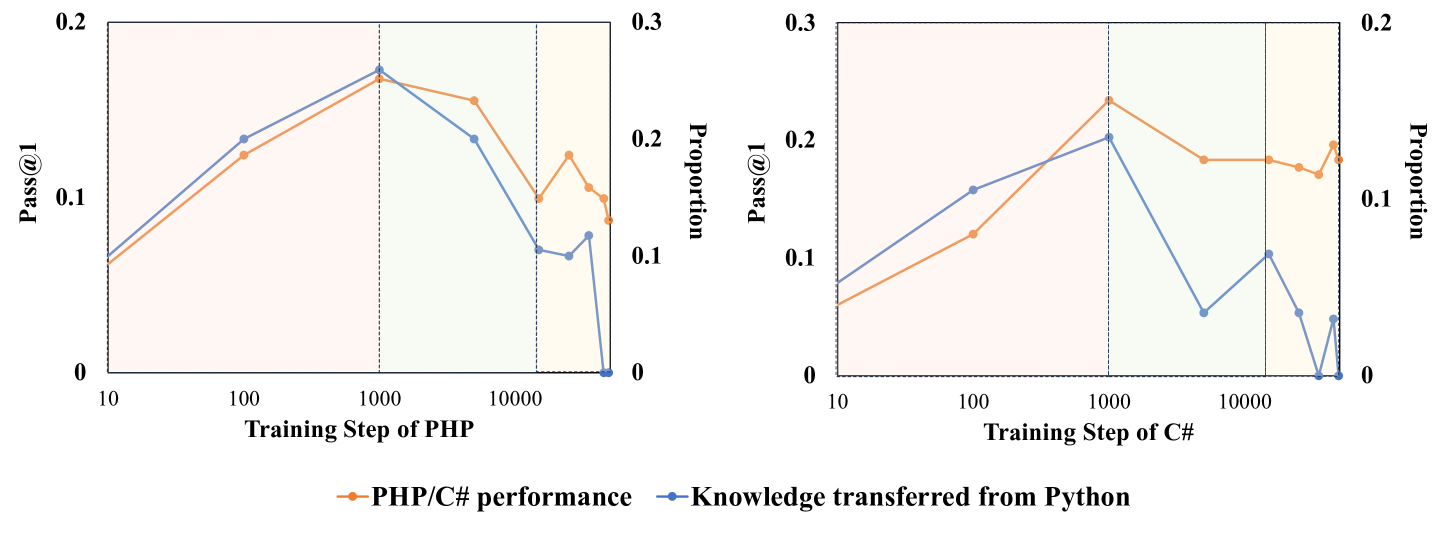
- 通过实验验证假说,并据此提出优化预训练语料的方法,显著提升模型性能。
📝 摘要(中文)
大型语言模型(LLM)展现出显著的多语言能力。然而,这些能力在预训练过程中发展背后的机制尚不清楚。本文以代码LLM为实验平台,探索LLM在预训练过程中多语言能力的演进。基于观察,我们提出了“巴别塔假说”,描述了LLM获得新语言能力的整个过程。在学习过程中,多种语言最初共享一个由主要语言主导的知识系统,并逐渐发展出特定于语言的知识系统。我们通过识别工作语言和语言转移神经元来跟踪LLM的内部状态,从而验证上述假设。实验结果表明,LLM的内部状态变化与我们的巴别塔假说一致。基于这些见解,我们提出了一种构建多语言代码LLM优化预训练语料的新方法,该方法显著优于在原始语料上训练的LLM。所提出的巴别塔假说为设计预训练数据分布以实现LLM的最佳多语言能力提供了新的见解。
🔬 方法详解
问题定义:现有方法缺乏对LLM多语言能力演进过程的深入理解,导致预训练数据配比策略缺乏理论指导,难以充分激发模型的多语言潜力。具体来说,如何理解不同语言在模型内部的表示形式,以及它们之间如何相互作用,是亟待解决的问题。
核心思路:论文的核心思路是,将LLM多语言能力的学习过程类比于“巴别塔”的建造过程。最初,所有语言共享一个统一的知识体系,随着训练的进行,模型逐渐为每种语言构建独立的知识表示,最终形成一个多语言共存的“巴别塔”。这种设计思路旨在揭示LLM内部多语言知识的组织方式和演进规律。
技术框架:论文的技术框架主要包括以下几个阶段:1) 模型训练:使用代码LLM作为实验平台,进行预训练。2) 语言识别:设计方法识别模型在处理不同语言时所激活的神经元,从而确定模型当前正在使用的“工作语言”。3) 神经元转移分析:分析不同语言之间的神经元转移情况,揭示语言之间的知识共享和迁移模式。4) 语料优化:基于“巴别塔假说”,设计一种新的预训练语料构建方法,优化不同语言的配比。
关键创新:论文最重要的技术创新点在于提出了“巴别塔假说”,并设计实验验证了该假说。该假说为理解LLM多语言能力的演进过程提供了一个新的视角,并为优化预训练数据分布提供了理论基础。与现有方法相比,该方法不再仅仅依赖于经验性的数据配比,而是基于对模型内部机制的理解进行优化。
关键设计:论文的关键设计包括:1) 工作语言识别方法:通过分析模型在处理不同语言时激活的神经元,识别当前的工作语言。具体方法未知。2) 语言转移神经元识别方法:通过分析不同语言之间的神经元激活模式,识别负责语言间知识转移的神经元。具体方法未知。3) 优化预训练语料构建方法:基于“巴别塔假说”,调整不同语言在预训练语料中的比例,以促进模型更好地学习多语言知识。具体调整策略未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于“巴别塔假说”构建的优化预训练语料,能够显著提升多语言代码LLM的性能。具体提升幅度未知,但优于在原始语料上训练的LLM。该结果验证了“巴别塔假说”的有效性,并为多语言LLM的预训练优化提供了新的方向。
🎯 应用场景
该研究成果可应用于多语言代码大模型的预训练优化,提升模型在跨语言代码生成、代码翻译等任务上的性能。此外,该研究提出的“巴别塔假说”也为通用多语言LLM的预训练数据设计提供了新的思路,有助于构建更高效、更强大的多语言模型,促进跨语言信息交流和知识共享。
📄 摘要(原文)
Large language models (LLMs) have shown significant multilingual capabilities. However, the mechanisms underlying the development of these capabilities during pre-training are not well understood. In this paper, we use code LLMs as an experimental platform to explore the evolution of multilingual capabilities in LLMs during the pre-training process. Based on our observations, we propose the Babel Tower Hypothesis, which describes the entire process of LLMs acquiring new language capabilities. During the learning process, multiple languages initially share a single knowledge system dominated by the primary language and gradually develop language-specific knowledge systems. We then validate the above hypothesis by tracking the internal states of the LLMs through identifying working languages and language transferring neurons. Experimental results show that the internal state changes of the LLM are consistent with our Babel Tower Hypothesis. Building on these insights, we propose a novel method to construct an optimized pre-training corpus for multilingual code LLMs, which significantly outperforms LLMs trained on the original corpus. The proposed Babel Tower Hypothesis provides new insights into designing pre-training data distributions to achieve optimal multilingual capabilities in LLMs.