Filling Memory Gaps: Enhancing Continual Semantic Parsing via SQL Syntax Variance-Guided LLMs without Real Data Replay
作者: Ruiheng Liu, Jinyu Zhang, Yanqi Song, Yu Zhang, Bailong Yang
分类: cs.CL, cs.DB
发布日期: 2024-12-10
💡 一句话要点
提出LECSP方法,利用SQL语法变异引导LLM增强持续语义解析,无需真实数据回放。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续语义解析 大语言模型 SQL语法变异 知识蒸馏 灾难性遗忘 任务感知 数据隐私
📋 核心要点
- 现有持续语义解析方法依赖历史数据回放或参数高效微调,存在数据隐私泄露或依赖理想化持续学习环境的问题。
- LECSP方法通过分析SQL语法变异性,引导大语言模型重建关键记忆,并使用任务感知的双教师蒸馏框架促进知识迁移。
- 实验结果表明,LECSP在两个CSP基准测试上显著优于现有方法,并实现了超越上限的泛化性能。
📝 摘要(中文)
本文提出了一种新的大语言模型增强的持续语义解析方法LECSP,旨在解决持续语义解析(CSP)问题,即在有限的标注样本下,训练解析器将自然语言问题转换为SQL,并适应动态更新的数据库。LECSP方法无需真实数据回放或理想设置,能够在缓解遗忘的同时促进泛化。该方法首先从SQL语法角度分析任务间的共性和差异,引导LLM重建关键记忆,并通过校准策略提高记忆准确性。然后,采用任务感知的双教师蒸馏框架,促进序列训练期间的知识积累和迁移。在两个CSP基准测试上的实验结果表明,LECSP方法显著优于现有方法,甚至优于那些使用数据回放或理想设置的方法。此外,LECSP实现了超越上限的泛化性能,更好地适应了未见过的任务。
🔬 方法详解
问题定义:持续语义解析(CSP)旨在解决自然语言到SQL的转换问题,特别是在数据库动态更新的环境下,需要模型能够持续学习新的任务,同时不遗忘旧的任务。现有方法主要面临两个痛点:一是需要回放历史数据,存在数据隐私问题;二是依赖理想的持续学习环境,与实际应用场景存在差距。
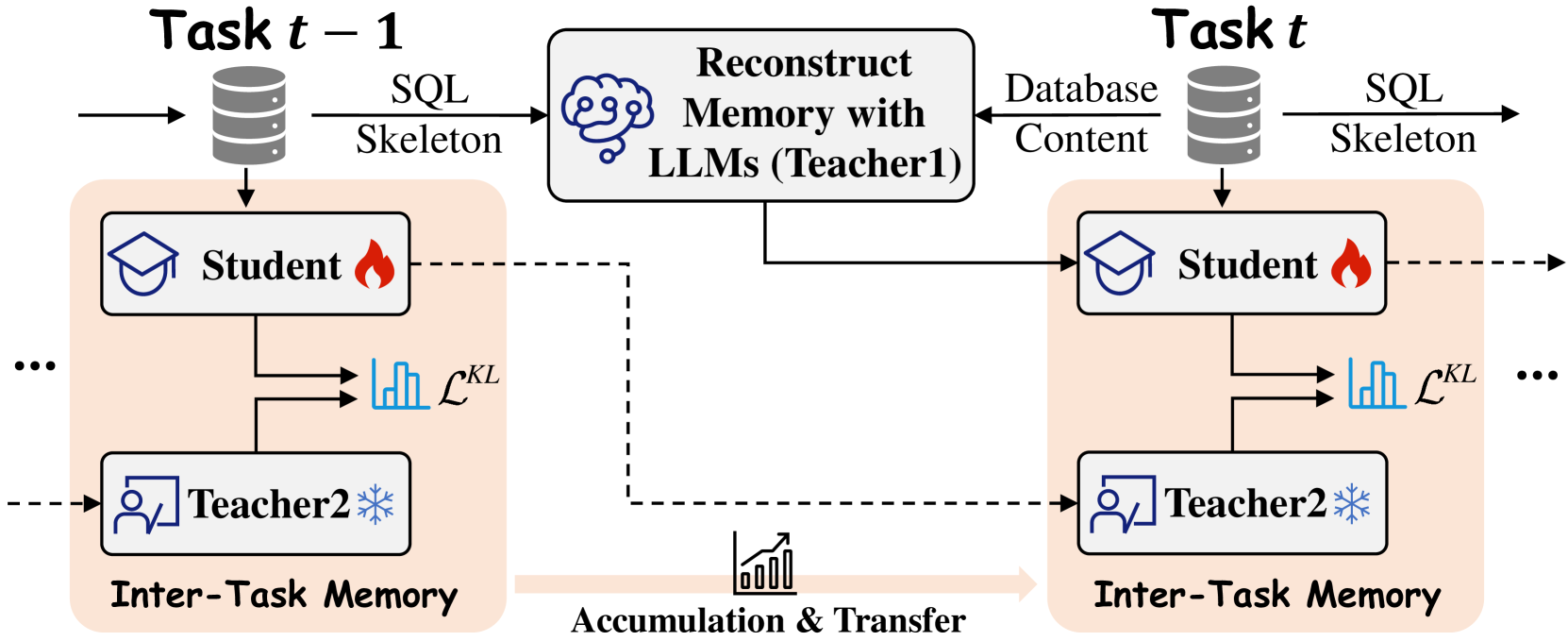
核心思路:LECSP的核心思路是利用大语言模型(LLM)的强大记忆和生成能力,结合SQL语法结构的分析,来缓解持续学习过程中的灾难性遗忘问题。通过分析不同任务SQL语法的共性和差异,引导LLM更准确地重建关键记忆,从而提高模型在旧任务上的性能。同时,利用双教师蒸馏框架,促进知识在不同任务之间的迁移,提高模型的泛化能力。
技术框架:LECSP方法主要包含两个阶段:1) 基于SQL语法变异的LLM记忆重建:首先分析不同任务的SQL语法差异,然后利用这些差异引导LLM生成更准确的任务描述,并以此重建关键记忆。2) 任务感知的双教师蒸馏:使用两个教师模型,一个负责生成旧任务的伪标签,另一个负责生成新任务的伪标签。学生模型同时学习这两个教师模型的知识,从而实现知识的积累和迁移。
关键创新:LECSP的关键创新在于:1) SQL语法变异引导的LLM记忆重建:通过分析SQL语法的差异,更有效地利用LLM的记忆能力,避免了简单地依赖LLM的通用知识。2) 任务感知的双教师蒸馏框架:该框架能够同时利用旧任务和新任务的信息,促进知识的积累和迁移,提高了模型的泛化能力。
关键设计:在SQL语法变异分析中,论文可能使用了某种形式的语法树或规则来表示SQL查询,并计算不同任务之间的语法差异。在双教师蒸馏框架中,可能使用了交叉熵损失函数或KL散度来衡量学生模型与教师模型之间的差异。具体的参数设置(例如,LLM的选择、蒸馏温度等)和网络结构(例如,学生模型的具体架构)在论文中应该有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LECSP方法在两个CSP基准测试上显著优于现有方法,包括那些使用数据回放或理想设置的方法。LECSP不仅缓解了灾难性遗忘问题,还实现了超越上限的泛化性能,更好地适应了未见过的任务。具体的性能提升幅度需要在论文中查找。
🎯 应用场景
LECSP方法可应用于需要持续学习的语义解析系统,例如智能客服、数据库查询助手等。该方法能够适应数据库结构的动态变化,提高系统的智能化水平和用户体验。此外,该方法无需真实数据回放,具有良好的数据隐私保护能力,更符合实际应用需求。未来,该方法可以扩展到其他自然语言处理任务,例如机器翻译、文本摘要等。
📄 摘要(原文)
Continual Semantic Parsing (CSP) aims to train parsers to convert natural language questions into SQL across tasks with limited annotated examples, adapting to the real-world scenario of dynamically updated databases. Previous studies mitigate this challenge by replaying historical data or employing parameter-efficient tuning (PET), but they often violate data privacy or rely on ideal continual learning settings. To address these problems, we propose a new Large Language Model (LLM)-Enhanced Continuous Semantic Parsing method, named LECSP, which alleviates forgetting while encouraging generalization, without requiring real data replay or ideal settings. Specifically, it first analyzes the commonalities and differences between tasks from the SQL syntax perspective to guide LLMs in reconstructing key memories and improving memory accuracy through a calibration strategy. Then, it uses a task-aware dual-teacher distillation framework to promote the accumulation and transfer of knowledge during sequential training. Experimental results on two CSP benchmarks show that our method significantly outperforms existing methods, even those utilizing data replay or ideal settings. Additionally, we achieve generalization performance beyond the upper limits, better adapting to unseen tasks.