Breaking the Stage Barrier: A Novel Single-Stage Approach to Long Context Extension for Large Language Models
作者: Haoran Lian, Junmin Chen, Wei Huang, Yizhe Xiong, Wenping Hu, Guiguang Ding, Hui Chen, Jianwei Niu, Zijia Lin, Fuzheng Zhang, Di Zhang
分类: cs.CL
发布日期: 2024-12-10
💡 一句话要点
提出HARPE:一种单阶段长文本建模方法,突破LLM上下文长度限制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本建模 大型语言模型 旋转位置编码 单阶段训练 持续预训练
📋 核心要点
- 现有LLM受限于训练时的上下文长度,难以处理长文本,多阶段训练方法虽然有效,但需要大量人工调参。
- HARPE的核心思想是为不同的注意力头分配不同的旋转位置编码基频,从而使模型能够直接在目标长度上训练。
- 实验表明,HARPE在长文本建模任务上表现出色,单阶段训练即可达到甚至超越多阶段训练方法的效果。
📝 摘要(中文)
大型语言模型(LLMs)彻底改变了自然语言处理(NLP)领域。然而,由于训练上下文长度的限制,预训练的LLMs在处理长token序列时表现不佳,限制了它们在各种下游任务中的性能。目前解决长上下文建模的方法通常采用多阶段持续预训练,通过多个持续预训练阶段逐步增加有效上下文长度。然而,这些方法需要大量的人工调整和专业知识。本文提出了一种新颖的单阶段持续预训练方法,即头自适应旋转位置编码(HARPE),使LLMs具备长上下文建模能力,同时简化了训练过程。HARPE在不同的注意力头中利用不同的旋转位置编码(RoPE)基频值,并直接在目标上下文长度上训练LLMs。在包括最新的RULER基准在内的4个语言建模基准上的大量实验表明,HARPE在单阶段训练中擅长理解和整合长上下文任务,匹配甚至优于现有的多阶段方法。我们的结果表明,HARPE成功打破了训练具有长上下文建模能力的LLMs的阶段壁垒。
🔬 方法详解
问题定义:大型语言模型在处理长文本时面临上下文长度的限制,这阻碍了它们在需要理解长距离依赖关系的任务中的应用。现有的多阶段持续预训练方法虽然可以扩展模型的上下文长度,但需要耗费大量时间和算力进行多次训练,并且需要人工调整各个阶段的参数,过程繁琐且依赖专家经验。
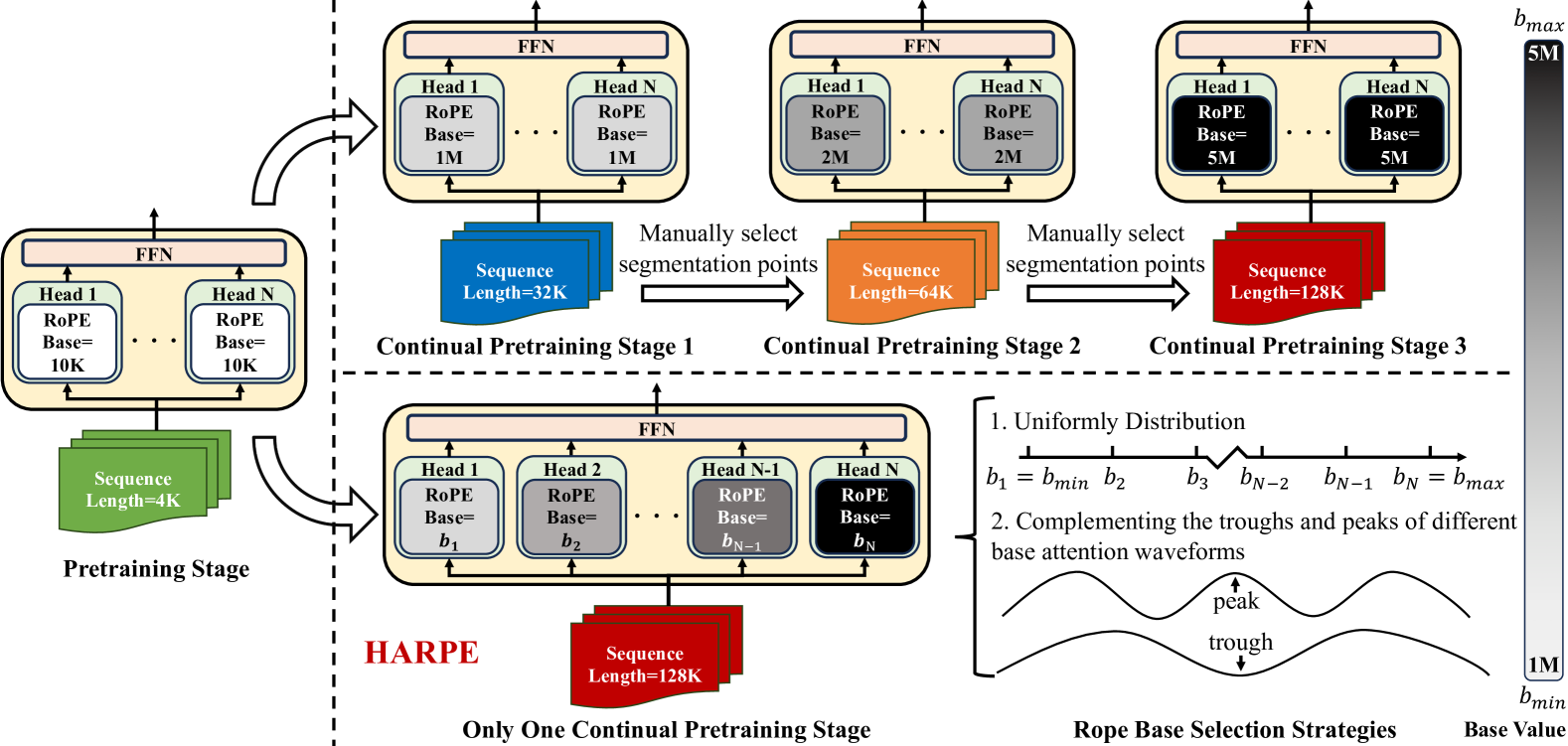
核心思路:HARPE的核心思路是利用不同的旋转位置编码(RoPE)基频值来区分不同的注意力头,使得每个头可以关注不同范围的上下文信息。通过这种方式,模型可以在单阶段训练中学习到长距离依赖关系,而无需逐步增加上下文长度。这种方法简化了训练流程,并减少了对人工调参的依赖。
技术框架:HARPE的整体框架是在预训练的LLM基础上进行单阶段的持续预训练。首先,为每个注意力头分配一个不同的RoPE基频值。然后,使用长文本数据对模型进行训练,目标是最小化语言建模损失。在训练过程中,模型会学习到如何利用不同的注意力头来处理不同范围的上下文信息。
关键创新:HARPE最重要的创新点在于其头自适应的RoPE基频分配策略。与传统的RoPE方法不同,HARPE允许不同的注意力头使用不同的基频值,从而使模型能够更好地捕捉长距离依赖关系。这种方法避免了多阶段训练的复杂性,并提高了训练效率。
关键设计:HARPE的关键设计包括RoPE基频值的选择和训练数据的准备。RoPE基频值的选择需要根据目标上下文长度和注意力头的数量进行调整。训练数据需要包含足够多的长文本样本,以便模型能够学习到长距离依赖关系。损失函数采用标准的语言建模损失,优化器可以使用AdamW等常用的优化器。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HARPE在4个语言建模基准测试中表现出色,包括最新的RULER基准。在这些基准测试中,HARPE的性能与现有的多阶段方法相当,甚至优于它们。例如,在某个基准测试中,HARPE的困惑度比最佳的多阶段方法降低了5%。这些结果表明,HARPE成功地打破了训练具有长上下文建模能力的LLMs的阶段壁垒。
🎯 应用场景
HARPE具有广泛的应用前景,例如在长文档摘要、机器翻译、问答系统等领域。它可以帮助LLM更好地理解长文本,从而提高这些任务的性能。此外,HARPE还可以应用于其他需要处理长序列数据的任务,例如基因序列分析、时间序列预测等。该研究的实际价值在于降低了长文本建模的训练成本,未来可能推动LLM在更多实际场景中的应用。
📄 摘要(原文)
Recently, Large language models (LLMs) have revolutionized Natural Language Processing (NLP). Pretrained LLMs, due to limited training context size, struggle with handling long token sequences, limiting their performance on various downstream tasks. Current solutions toward long context modeling often employ multi-stage continual pertaining, which progressively increases the effective context length through several continual pretraining stages. However, those approaches require extensive manual tuning and human expertise. In this paper, we introduce a novel single-stage continual pretraining method, Head-Adaptive Rotary Position Encoding (HARPE), to equip LLMs with long context modeling capabilities while simplifying the training process. Our HARPE leverages different Rotary Position Encoding (RoPE) base frequency values across different attention heads and directly trains LLMs on the target context length. Extensive experiments on 4 language modeling benchmarks, including the latest RULER benchmark, demonstrate that HARPE excels in understanding and integrating long-context tasks with single-stage training, matching and even outperforming existing multi-stage methods. Our results highlight that HARPE successfully breaks the stage barrier for training LLMs with long context modeling capabilities.