Exploring Coding Spot: Understanding Parametric Contributions to LLM Coding Performance
作者: Dongjun Kim, Minhyuk Kim, YongChan Chun, Chanjun Park, Heuiseok Lim
分类: cs.CL
发布日期: 2024-12-10
💡 一句话要点
探索LLM代码能力:揭示参数对代码性能的贡献,发现“代码区域”
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 代码生成 代码理解 参数贡献 代码区域
📋 核心要点
- 现有研究对LLM代码能力的机制探索不足,特别是不同编程语言的处理方式。
- 论文提出“代码区域”概念,认为LLM存在专门负责代码功能的参数子集。
- 实验表明,修改“代码区域”能显著影响代码任务性能,同时保持非代码功能。
📝 摘要(中文)
大型语言模型(LLM)在多种编程语言的代码生成和理解方面表现出显著的能力。然而,这种能力背后的机制仍未被充分探索,特别是不同的编程语言是否在独立或共享的参数区域中被处理。本文类比于大脑中负责不同认知功能的专门区域,引入了“代码区域”(Coding Spot)的概念,即LLM中促进代码能力的特定参数区域。研究结果识别出了这个“代码区域”,并表明对该子集的有针对性修改会显著影响代码任务的性能,同时在很大程度上保留非代码功能。这种划分与认知神经科学中观察到的功能专业化相似,其中特定的大脑区域专门用于不同的任务,这表明LLM可能类似地为不同的知识领域采用专门的参数区域。
🔬 方法详解
问题定义:论文旨在理解LLM代码能力的内在机制,特别是模型参数在不同编程语言处理中的作用。现有方法缺乏对LLM内部参数如何影响代码生成和理解的细致分析,未能揭示代码能力是否集中在特定的参数区域。
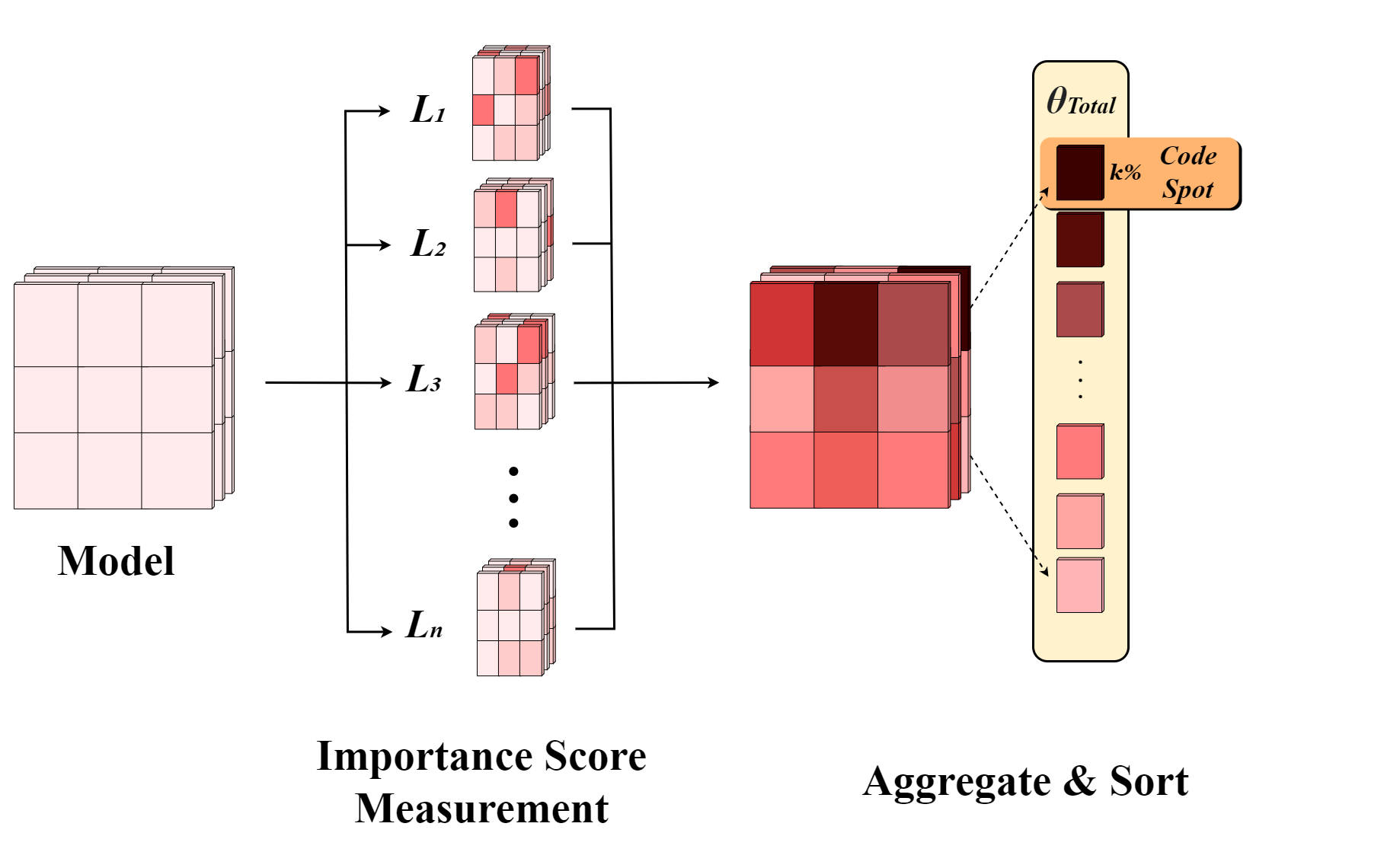
核心思路:论文的核心思路是将LLM的代码能力类比于大脑的功能分区,假设LLM中存在一个专门负责代码相关任务的“代码区域”。通过识别和修改这个区域,可以有针对性地提升或削弱LLM的代码能力,同时尽量不影响其其他功能。
技术框架:论文首先通过实验确定对代码任务影响最大的参数子集,即“代码区域”。然后,通过修改(例如,增加或减少这些参数的权重)这个区域的参数,观察LLM在代码生成、代码理解以及非代码任务上的性能变化。整体流程包括:1) 定义代码任务和非代码任务;2) 确定候选参数子集;3) 修改候选参数子集;4) 评估LLM在不同任务上的性能。
关键创新:论文最重要的创新点在于提出了“代码区域”的概念,并验证了LLM中存在专门负责代码功能的参数子集。这种参数的专门化使用方式,类似于认知神经科学中大脑的功能分区,为理解LLM的内部工作机制提供了一个新的视角。
关键设计:论文的关键设计包括:1) 精心设计的代码任务和非代码任务,用于评估LLM的性能;2) 一种有效的参数选择方法,用于识别“代码区域”;3) 一种参数修改策略,用于有针对性地调整“代码区域”的参数。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了“代码区域”的存在,并表明修改该区域的参数可以显著影响代码任务的性能,同时保持非代码功能。具体的性能数据和提升幅度在摘要中未提及,属于未知信息。实验结果支持了LLM可能采用专门的参数区域来处理不同知识领域的假设。
🎯 应用场景
该研究成果可应用于提升LLM的代码生成和理解能力,例如通过有针对性地训练“代码区域”来提高代码质量。此外,该研究也为理解LLM的内部工作机制提供了新的思路,有助于开发更高效、更可控的LLM。未来,可以探索如何利用“代码区域”实现特定编程语言的优化,或者将代码能力与其他知识领域更好地融合。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated notable proficiency in both code generation and comprehension across multiple programming languages. However, the mechanisms underlying this proficiency remain underexplored, particularly with respect to whether distinct programming languages are processed independently or within a shared parametric region. Drawing an analogy to the specialized regions of the brain responsible for distinct cognitive functions, we introduce the concept of Coding Spot, a specialized parametric region within LLMs that facilitates coding capabilities. Our findings identify this Coding Spot and show that targeted modifications to this subset significantly affect performance on coding tasks, while largely preserving non-coding functionalities. This compartmentalization mirrors the functional specialization observed in cognitive neuroscience, where specific brain regions are dedicated to distinct tasks, suggesting that LLMs may similarly employ specialized parameter regions for different knowledge domains.