Generative Adversarial Reviews: When LLMs Become the Critic
作者: Nicolas Bougie, Narimasa Watanabe
分类: cs.CL, cs.AI
发布日期: 2024-12-09
💡 一句话要点
提出GAR:利用LLM驱动的智能体模拟同行评审,提升科研反馈效率与公平性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成式智能体 同行评审 大型语言模型 知识图谱 论文评估
📋 核心要点
- 现有同行评审机制面临学术产出激增和专业领域细分的挑战,导致反馈效率降低。
- GAR利用LLM构建智能体,模拟同行评审员,通过记忆和角色扮演提供专业反馈。
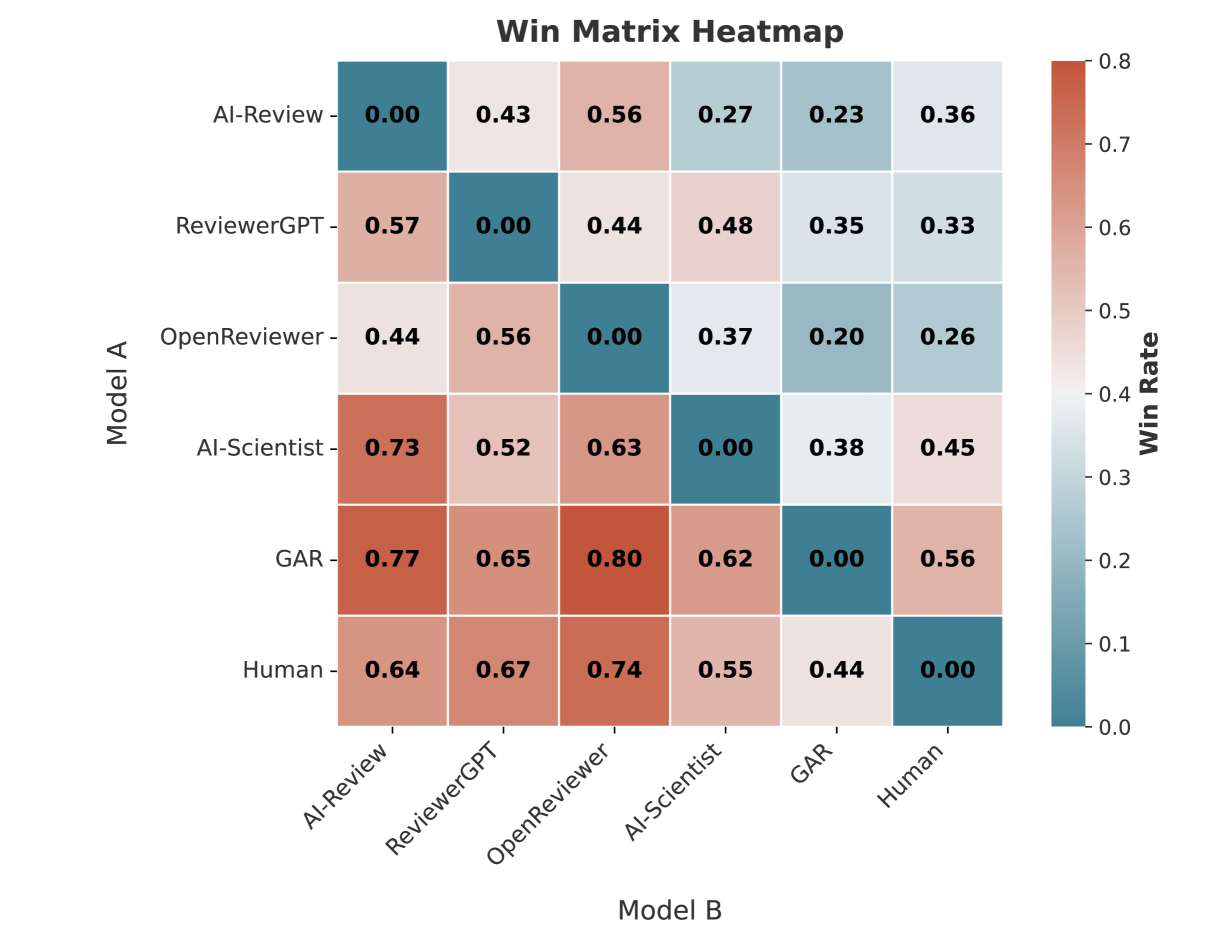
- 实验表明GAR在提供详细反馈和预测论文结果方面与人类评审员表现相当。
📝 摘要(中文)
同行评审是科学进步的基石,决定着哪些论文能够达到发表的质量标准。然而,学术产出的快速增长和知识领域日益专业化给传统的科学反馈机制带来了压力。为此,我们引入了生成式智能体评审员(GAR),利用LLM驱动的智能体来模拟真实的同行评审员。为了实现生成式评审员,我们设计了一个架构,该架构使用记忆能力扩展大型语言模型,并为智能体配备了从历史数据中提取的评审员角色。该方法的核心是基于图的稿件表示,它浓缩了内容并以逻辑方式组织信息——将想法与证据和技术细节联系起来。GAR的评审过程利用外部知识来评估论文的新颖性,然后使用图表示和多轮评估进行详细评估。最后,元评审员汇总个人评审以预测接受决策。我们的实验表明,GAR在提供详细反馈和预测论文结果方面与人类评审员相当。除了单纯的性能比较之外,我们还进行了深刻的实验,例如评估评审员专业知识的影响以及检查评审中的公平性。通过提供通常仅限于少数研究人员的早期专家级反馈,GAR使人们能够更公平地获得透明和深入的评估。
🔬 方法详解
问题定义:当前同行评审过程面临着评审专家数量不足、评审周期长、评审意见主观性强等问题。尤其是在新兴领域,找到合适的评审专家更加困难。现有方法难以有效应对学术论文数量的快速增长,并且评审结果的公平性也受到关注。
核心思路:论文的核心思路是利用大型语言模型(LLM)构建生成式智能体评审员(GAR),模拟人类评审员的评审过程。通过赋予LLM记忆能力和评审员角色,使其能够像人类专家一样对论文进行评估,从而提高评审效率和公平性。
技术框架:GAR的整体架构包含以下几个主要模块:1) 稿件图表示:将论文内容转换为图结构,节点表示概念,边表示概念之间的关系。2) 评审员角色建模:从历史评审数据中学习评审员的专业知识和偏好,构建评审员角色。3) 评审过程模拟:利用LLM驱动的智能体,根据稿件图表示和评审员角色,进行多轮评审,生成评审意见。4) 元评审:汇总多个智能体评审员的意见,预测论文的接受决策。
关键创新:该论文的关键创新在于:1) 提出了利用LLM构建生成式智能体评审员的概念,将LLM应用于同行评审领域。2) 设计了基于图的稿件表示方法,能够有效地提取和组织论文内容。3) 实现了多轮评审过程模拟,使智能体能够像人类评审员一样进行深入评估。
关键设计:稿件图表示的关键设计包括:节点表示论文中的概念(例如,方法、实验结果),边表示概念之间的关系(例如,支持、反对)。评审员角色建模的关键设计包括:利用历史评审数据训练LLM,使其能够学习评审员的专业知识和偏好。评审过程模拟的关键设计包括:多轮评审,每一轮评审关注不同的方面(例如,新颖性、技术细节)。元评审的关键设计包括:使用加权平均或机器学习模型,汇总多个智能体评审员的意见。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GAR在提供详细反馈和预测论文接受决策方面与人类评审员的表现相当。GAR能够识别论文中的关键问题,并给出有针对性的改进建议。此外,研究还评估了评审员专业知识对评审结果的影响,并探讨了评审的公平性问题。
🎯 应用场景
GAR可应用于学术出版领域,加速论文评审流程,缓解评审专家短缺问题。同时,该技术可用于科研人员自查,在投稿前获得初步的专家级反馈,提高论文质量。未来,GAR有望扩展到其他需要专家评估的领域,如项目评审、专利评估等。
📄 摘要(原文)
The peer review process is fundamental to scientific progress, determining which papers meet the quality standards for publication. Yet, the rapid growth of scholarly production and increasing specialization in knowledge areas strain traditional scientific feedback mechanisms. In light of this, we introduce Generative Agent Reviewers (GAR), leveraging LLM-empowered agents to simulate faithful peer reviewers. To enable generative reviewers, we design an architecture that extends a large language model with memory capabilities and equips agents with reviewer personas derived from historical data. Central to this approach is a graph-based representation of manuscripts, condensing content and logically organizing information - linking ideas with evidence and technical details. GAR's review process leverages external knowledge to evaluate paper novelty, followed by detailed assessment using the graph representation and multi-round assessment. Finally, a meta-reviewer aggregates individual reviews to predict the acceptance decision. Our experiments demonstrate that GAR performs comparably to human reviewers in providing detailed feedback and predicting paper outcomes. Beyond mere performance comparison, we conduct insightful experiments, such as evaluating the impact of reviewer expertise and examining fairness in reviews. By offering early expert-level feedback, typically restricted to a limited group of researchers, GAR democratizes access to transparent and in-depth evaluation.