FM2DS: Few-Shot Multimodal Multihop Data Synthesis with Knowledge Distillation for Question Answering
作者: Amirhossein Abaskohi, Spandana Gella, Giuseppe Carenini, Issam H. Laradji
分类: cs.CL, cs.AI, cs.CV, cs.IR, cs.LG
发布日期: 2024-12-09 (更新: 2025-09-13)
备注: Findings of EMNLP 2025
💡 一句话要点
提出FM2DS框架,用于少样本多模态多跳问答数据合成与知识蒸馏
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态问答 数据合成 知识蒸馏 多跳推理 长文档理解
📋 核心要点
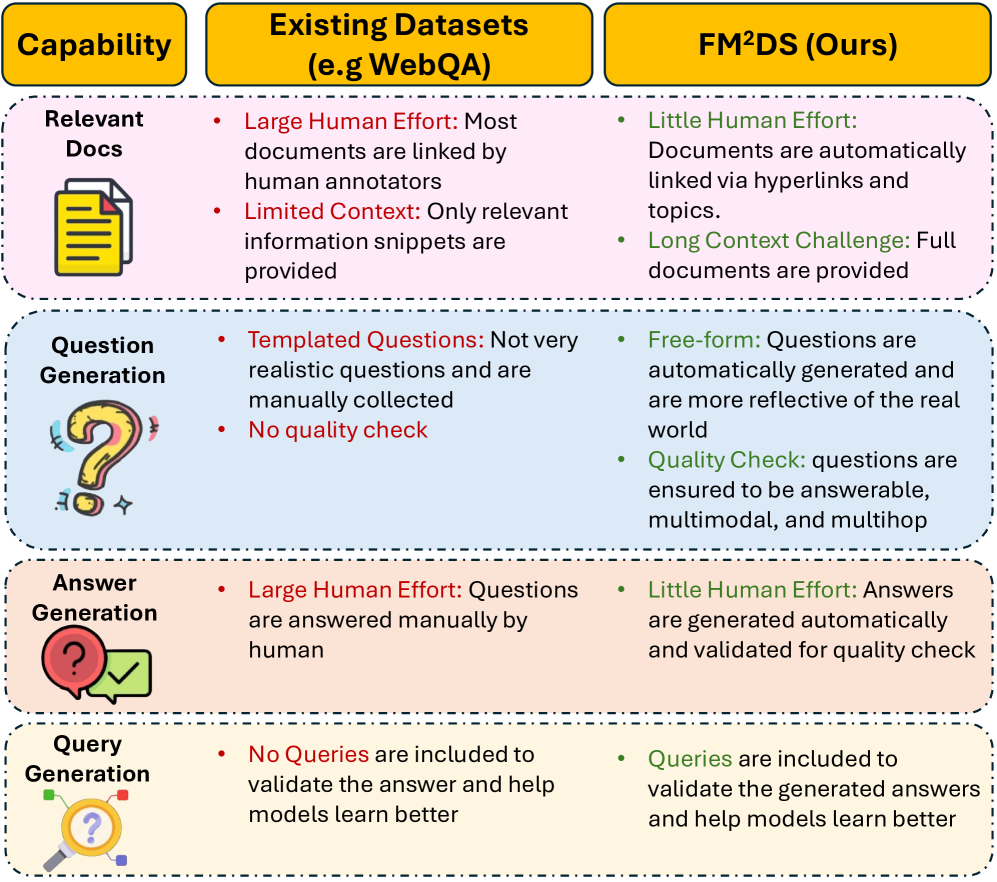
- 多模态多跳问答(MMQA)面临高质量数据集匮乏的挑战,现有数据集通常局限于单跳、单模态或短文本。
- FM2DS框架通过五阶段流程,从维基百科获取多模态文档,合成高质量问题和答案,并进行严格验证。
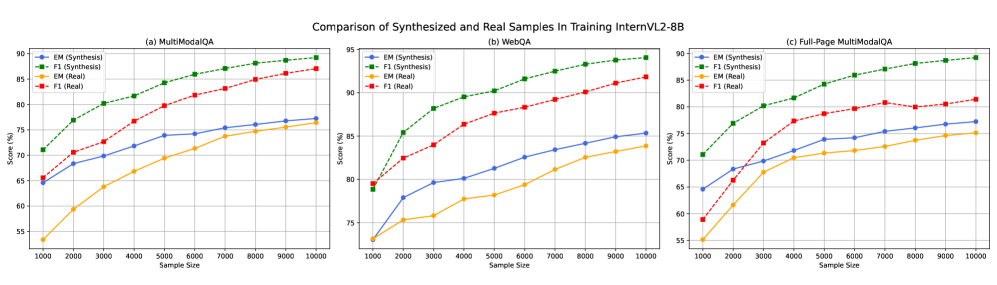
- 实验表明,使用FM2DS合成数据训练的模型在MultimodalQA和WebQA上优于人工标注数据,并构建了新的M2QA-Bench基准。
📝 摘要(中文)
多模态多跳问答(MMQA)需要在来自多个来源的图像和文本上进行推理。尽管视觉问答取得了进展,但由于缺乏高质量的数据集,这种多跳设置仍未得到充分探索。现有方法侧重于单跳、单模态或短文本,限制了现实应用,例如解释具有长篇多模态内容的教育文档。为了填补这一空白,我们推出了FM2DS,这是第一个用于创建高质量MMQA数据集的框架。我们的方法包括一个5阶段的流程,涉及从维基百科获取相关的多模态文档,综合生成高级问题和答案,并通过严格的标准验证它们,以确保数据质量。我们通过在我们合成的数据集上训练模型并在两个基准测试MultimodalQA和WebQA上进行测试来评估我们的方法。我们的结果表明,在样本量相等的情况下,在我们合成的数据上训练的模型在精确匹配(EM)得分上平均优于在人工收集的数据上训练的模型1.9。此外,我们还推出了包含1k个样本的M2QA-Bench,这是第一个基于长文档的MMQA基准测试,使用FM2DS生成并由人工注释员改进。我们相信我们的数据合成方法将为训练和评估MMQA模型奠定坚实的基础。
🔬 方法详解
问题定义:论文旨在解决多模态多跳问答(MMQA)领域缺乏高质量训练数据集的问题。现有数据集通常规模小、质量低,或者侧重于单跳、单模态等简单场景,难以支持复杂的多模态推理任务。这限制了MMQA模型在实际应用中的性能,例如处理包含长篇文本和图像的教育文档。
核心思路:论文的核心思路是通过数据合成来生成大规模、高质量的MMQA数据集。作者设计了一个自动化的流程,从维基百科等知识库中提取相关信息,并利用规则和模板自动生成问题和答案。为了保证数据质量,还引入了验证机制,过滤掉不合理或不准确的样本。
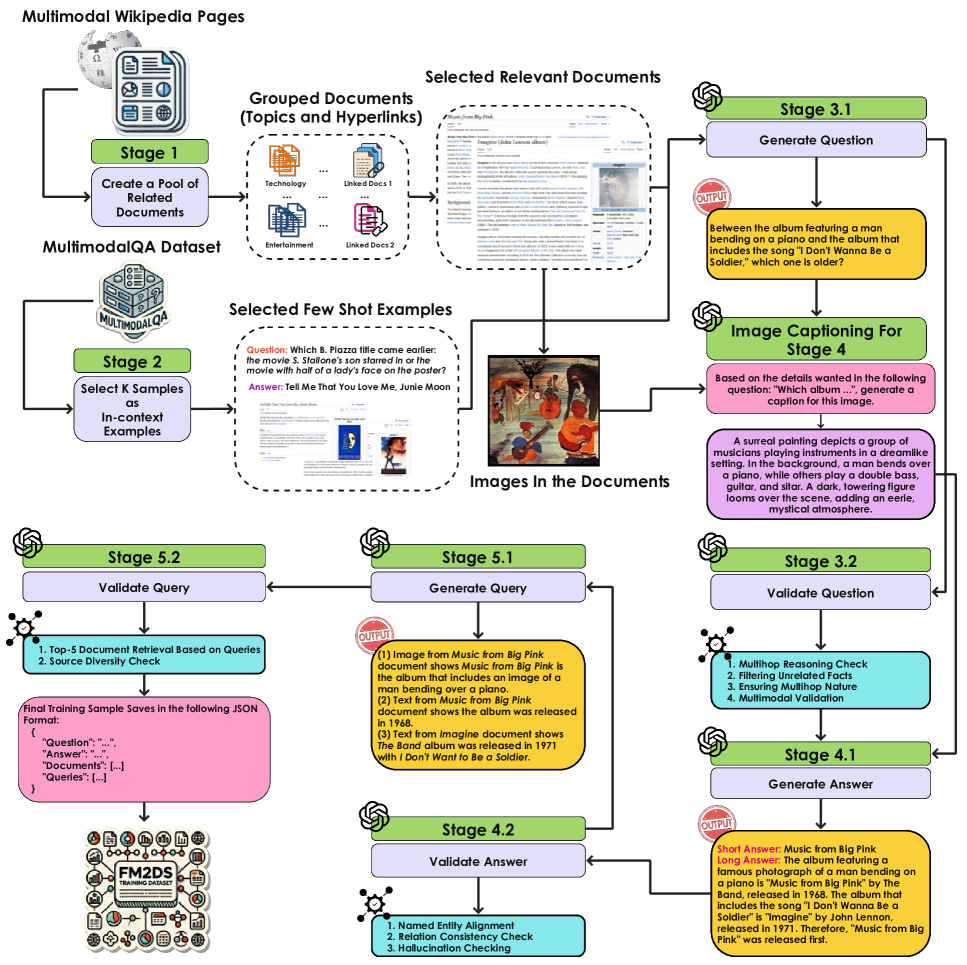
技术框架:FM2DS框架包含五个主要阶段:1) 文档获取:从维基百科等来源获取相关的多模态文档(文本和图像);2) 问题生成:基于文档内容,利用规则和模板自动生成问题;3) 答案生成:根据问题和文档内容,生成对应的答案;4) 问题-答案验证:使用一系列规则和模型来验证生成的问题和答案的质量,过滤掉不合格的样本;5) 数据集构建:将验证通过的问题-答案对及其对应的文档组成最终的数据集。
关键创新:FM2DS的关键创新在于其自动化数据合成流程,能够高效地生成大规模、高质量的MMQA数据集。与传统的人工标注方法相比,FM2DS能够显著降低数据获取的成本,并提高数据的多样性和覆盖范围。此外,FM2DS还引入了问题-答案验证机制,确保生成的数据具有较高的质量。
关键设计:在问题生成阶段,作者设计了一系列规则和模板,用于生成不同类型的问题,例如比较、推理、解释等。在答案生成阶段,作者利用信息抽取技术从文档中提取相关信息,并将其组合成答案。在问题-答案验证阶段,作者使用了基于规则的方法和预训练的语言模型来评估问题和答案的合理性和准确性。具体的参数设置和网络结构在论文中未详细说明,可能使用了标准的NLP模型和技术。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用FM2DS合成的数据训练的模型在MultimodalQA和WebQA数据集上取得了显著的性能提升,平均精确匹配(EM)得分提高了1.9%。此外,作者还构建了一个新的基准测试M2QA-Bench,包含1k个样本,为评估MMQA模型在长文档上的性能提供了新的平台。
🎯 应用场景
该研究成果可应用于教育、医疗、金融等领域,例如,可以帮助学生理解包含长篇文本和图像的教材,辅助医生进行病例分析,或者帮助金融分析师从大量的报告中提取关键信息。FM2DS框架为构建大规模多模态问答数据集提供了一种有效的方法,有望推动相关领域的发展。
📄 摘要(原文)
Multimodal multihop question answering (MMQA) requires reasoning over images and text from multiple sources. Despite advances in visual question answering, this multihop setting remains underexplored due to a lack of quality datasets. Existing methods focus on single-hop, single-modality, or short texts, limiting real-world applications like interpreting educational documents with long, multimodal content. To fill this gap, we introduce FM2DS, the first framework for creating a high-quality dataset for MMQA. Our approach consists of a 5-stage pipeline that involves acquiring relevant multimodal documents from Wikipedia, synthetically generating high-level questions and answers, and validating them through rigorous criteria to ensure data quality. We evaluate our methodology by training models on our synthesized dataset and testing on two benchmarks: MultimodalQA and WebQA. Our results demonstrate that, with an equal sample size, models trained on our synthesized data outperform those trained on human-collected data by 1.9 in exact match (EM) score on average. Additionally, we introduce M2QA-Bench with 1k samples, the first benchmark for MMQA on long documents, generated using FM2DS and refined by human annotators. We believe our data synthesis method will serve as a strong foundation for training and evaluating MMQA models.