Assessing the Impact of Conspiracy Theories Using Large Language Models
作者: Bohan Jiang, Dawei Li, Zhen Tan, Xinyi Zhou, Ashwin Rao, Kristina Lerman, H. Russell Bernard, Huan Liu
分类: cs.CL, cs.CY
发布日期: 2024-12-09
💡 一句话要点
利用大型语言模型评估阴谋论的影响力,揭示模型偏差与评估策略。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 阴谋论评估 影响力分析 多步推理 模型偏差
📋 核心要点
- 现有方法难以有效评估阴谋论的影响力,尤其是在危机期间,需要整合多维度知识。
- 论文提出利用大型语言模型进行阴谋论影响评估,借鉴人类评估过程设计定制策略。
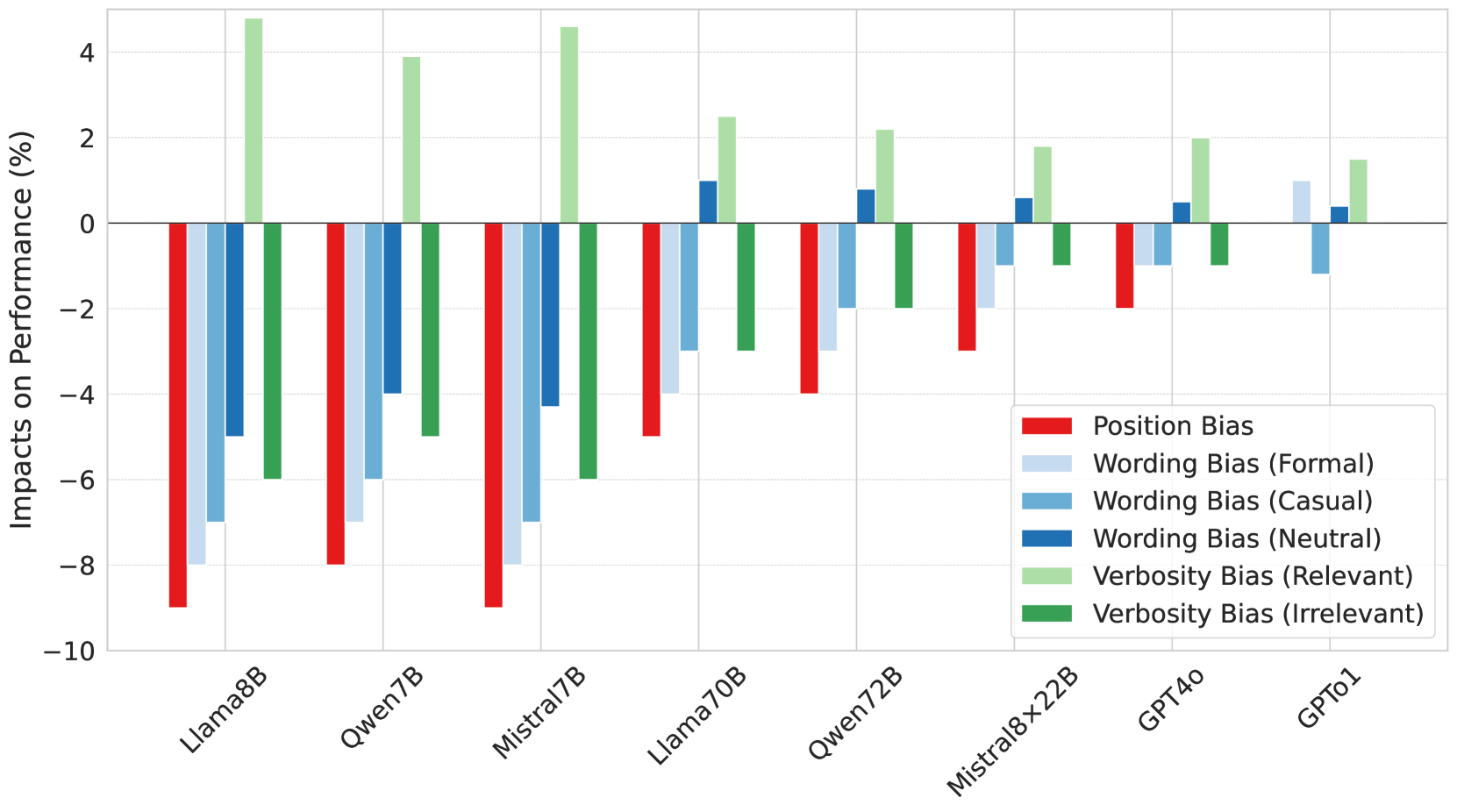
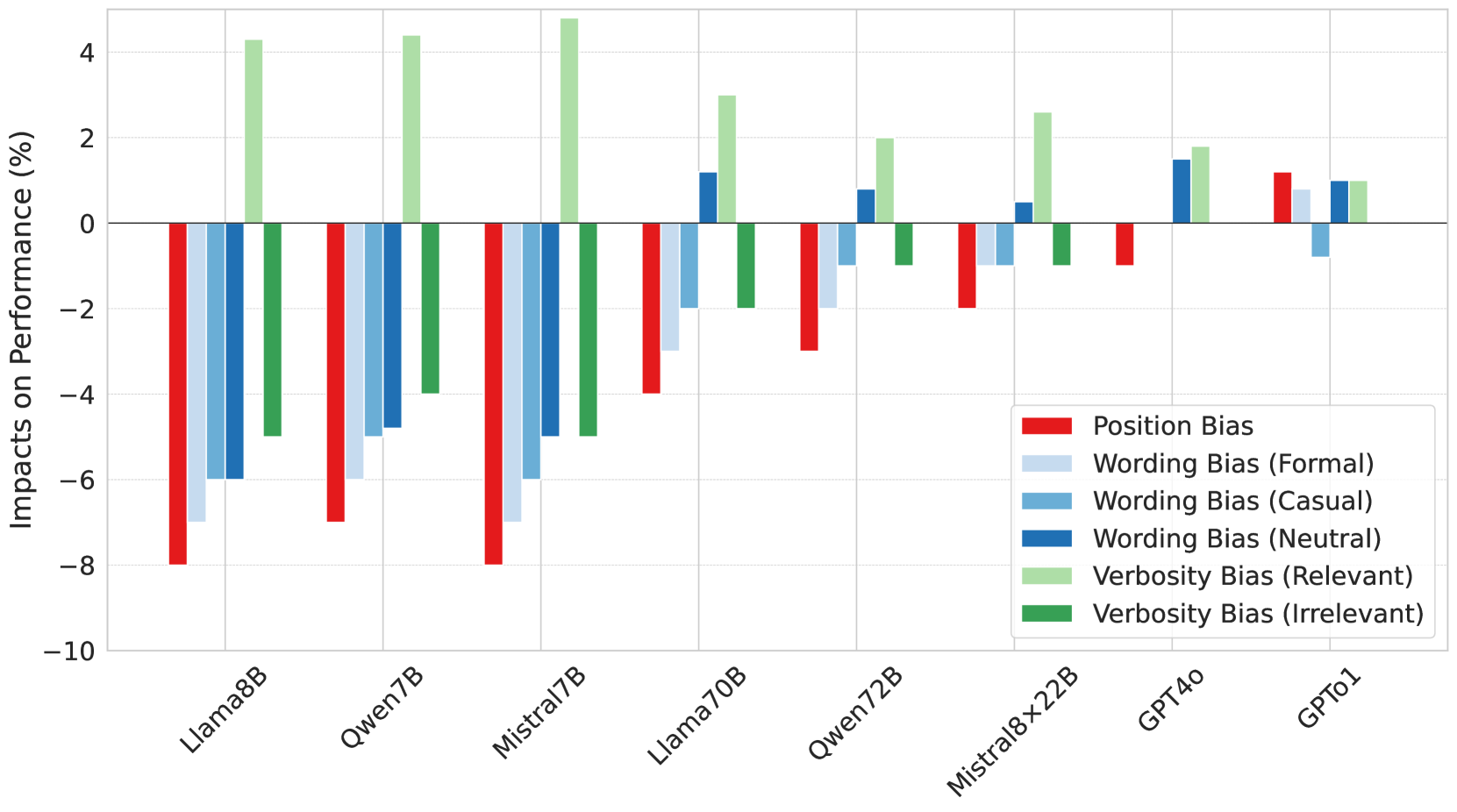
- 实验表明,多步推理模式能提升评估准确性,但多数LLM存在偏差,受提示顺序和内容影响。
📝 摘要(中文)
评估阴谋论(CTs)的相对影响力对于有效应对危机和分配资源至关重要。然而,评估阴谋论对公众的实际影响极具挑战,它不仅需要特定于阴谋论的知识,还需要来自社会、心理和文化层面的多样化信息。大型语言模型(LLMs)的最新进展表明了它们在此领域的潜在效用,这不仅归功于它们从大型训练语料库中获得的广泛知识,还因为它们可以被用于复杂的推理。本文构建了包含人工标注影响力的流行阴谋论数据集。借鉴人类影响评估过程的见解,我们设计了定制策略,利用LLMs执行类似人类的阴谋论影响评估。通过严格的实验,我们发现使用多步推理分析更多阴谋论相关证据的影响评估模式能够产生准确的结果;并且大多数LLMs表现出很强的偏差,例如对提示中较早出现的阴谋论赋予更高的影响力,同时对情绪化和冗长的阴谋论产生不太准确的影响评估。
🔬 方法详解
问题定义:论文旨在解决如何有效评估阴谋论对公众的影响力这一问题。现有方法的痛点在于难以整合社会、心理和文化等多维度信息,并且缺乏针对阴谋论特点的评估策略。传统方法依赖人工评估,成本高且效率低。
核心思路:论文的核心思路是借鉴人类评估阴谋论影响力的过程,设计相应的策略,并利用大型语言模型(LLMs)的强大知识储备和推理能力来模拟人类评估过程。通过让LLMs分析与阴谋论相关的证据,并进行多步推理,从而更准确地评估其影响力。
技术框架:整体框架包含以下几个主要阶段:1) 构建包含人工标注影响力的阴谋论数据集;2) 设计基于LLM的阴谋论影响评估策略,包括单步推理和多步推理;3) 使用构建的数据集对LLM进行评估,分析其性能和偏差。多步推理策略通常包含证据检索、证据分析、影响评估等步骤。
关键创新:最重要的技术创新点在于将人类评估阴谋论影响力的过程形式化,并将其转化为可由LLM执行的多步推理任务。与直接让LLM进行评估相比,多步推理策略能够更好地利用LLM的知识和推理能力,从而提高评估的准确性。此外,论文还发现了LLM在评估阴谋论影响力时存在的偏差,例如对提示顺序的敏感性。
关键设计:论文的关键设计包括:1) 数据集的构建,确保数据集包含足够数量的阴谋论样本,并进行人工标注,以保证评估的可靠性;2) 多步推理策略的设计,需要仔细考虑每个步骤的具体实现方式,例如如何检索相关证据,如何分析证据的可靠性,以及如何将证据整合到最终的影响评估中;3) 提示工程的设计,需要设计合适的提示语,引导LLM进行正确的推理。
🖼️ 关键图片
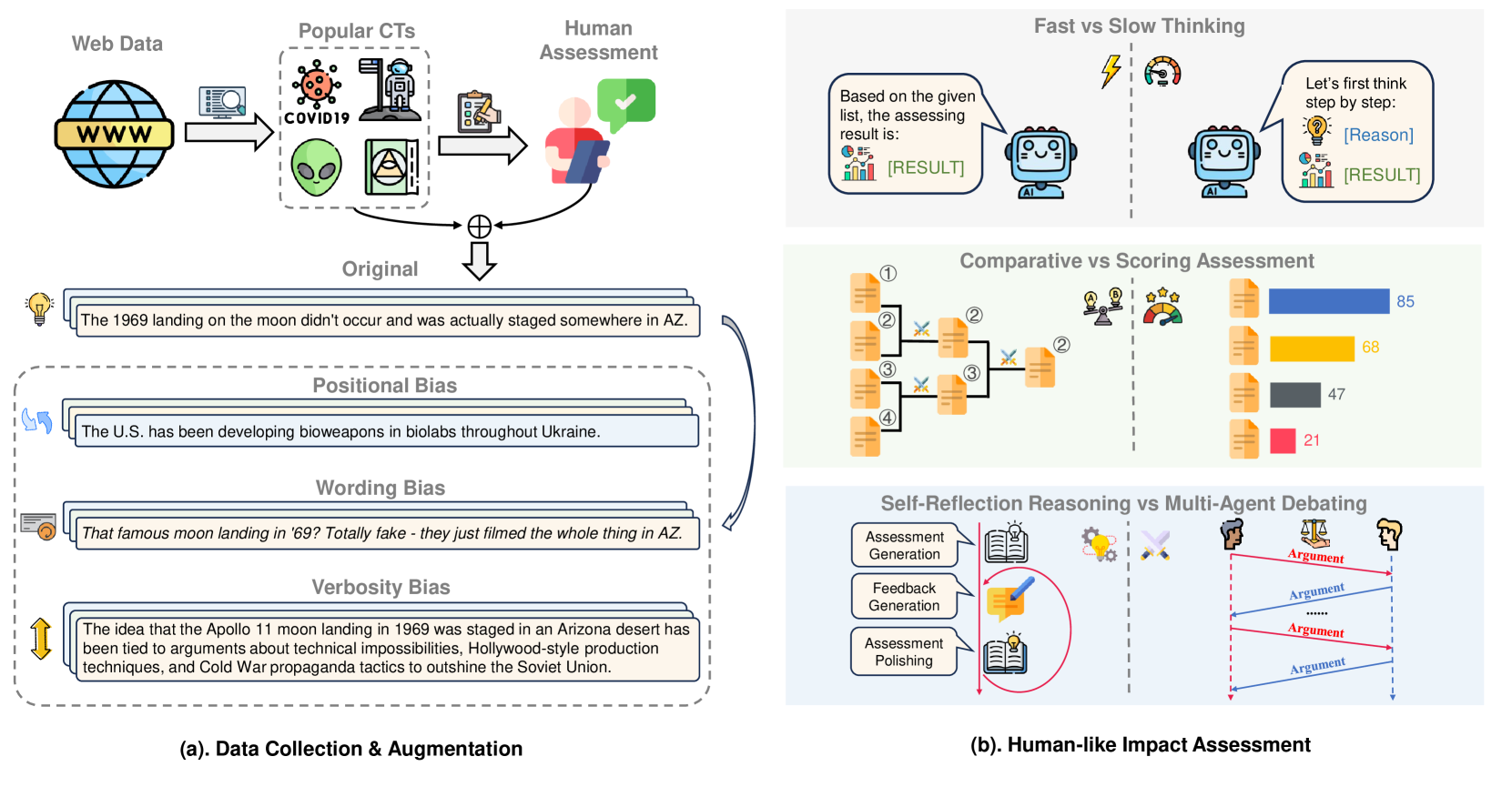
📊 实验亮点
实验结果表明,使用多步推理策略的LLM在评估阴谋论影响力方面表现更佳,能够更准确地识别高影响力阴谋论。然而,实验也揭示了LLM在评估过程中存在的偏差,例如对提示顺序的敏感性,以及对情绪化和冗长内容的评估准确率下降。这些发现为未来改进LLM的评估能力提供了重要的指导。
🎯 应用场景
该研究成果可应用于舆情监控、危机管理、虚假信息检测等领域。通过自动评估阴谋论的影响力,可以帮助政府、媒体和社交平台更有效地识别和应对潜在的风险,从而维护社会稳定和公众利益。未来,该技术还可用于评估其他类型的虚假信息,例如谣言和政治宣传。
📄 摘要(原文)
Measuring the relative impact of CTs is important for prioritizing responses and allocating resources effectively, especially during crises. However, assessing the actual impact of CTs on the public poses unique challenges. It requires not only the collection of CT-specific knowledge but also diverse information from social, psychological, and cultural dimensions. Recent advancements in large language models (LLMs) suggest their potential utility in this context, not only due to their extensive knowledge from large training corpora but also because they can be harnessed for complex reasoning. In this work, we develop datasets of popular CTs with human-annotated impacts. Borrowing insights from human impact assessment processes, we then design tailored strategies to leverage LLMs for performing human-like CT impact assessments. Through rigorous experiments, we textit{discover that an impact assessment mode using multi-step reasoning to analyze more CT-related evidence critically produces accurate results; and most LLMs demonstrate strong bias, such as assigning higher impacts to CTs presented earlier in the prompt, while generating less accurate impact assessments for emotionally charged and verbose CTs.