Asynchronous LLM Function Calling
作者: In Gim, Seung-seob Lee, Lin Zhong
分类: cs.CL, cs.AI
发布日期: 2024-12-09
💡 一句话要点
提出AsyncLM以解决LLM函数调用的同步限制问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 异步函数调用 中断机制 推理效率 人机交互
📋 核心要点
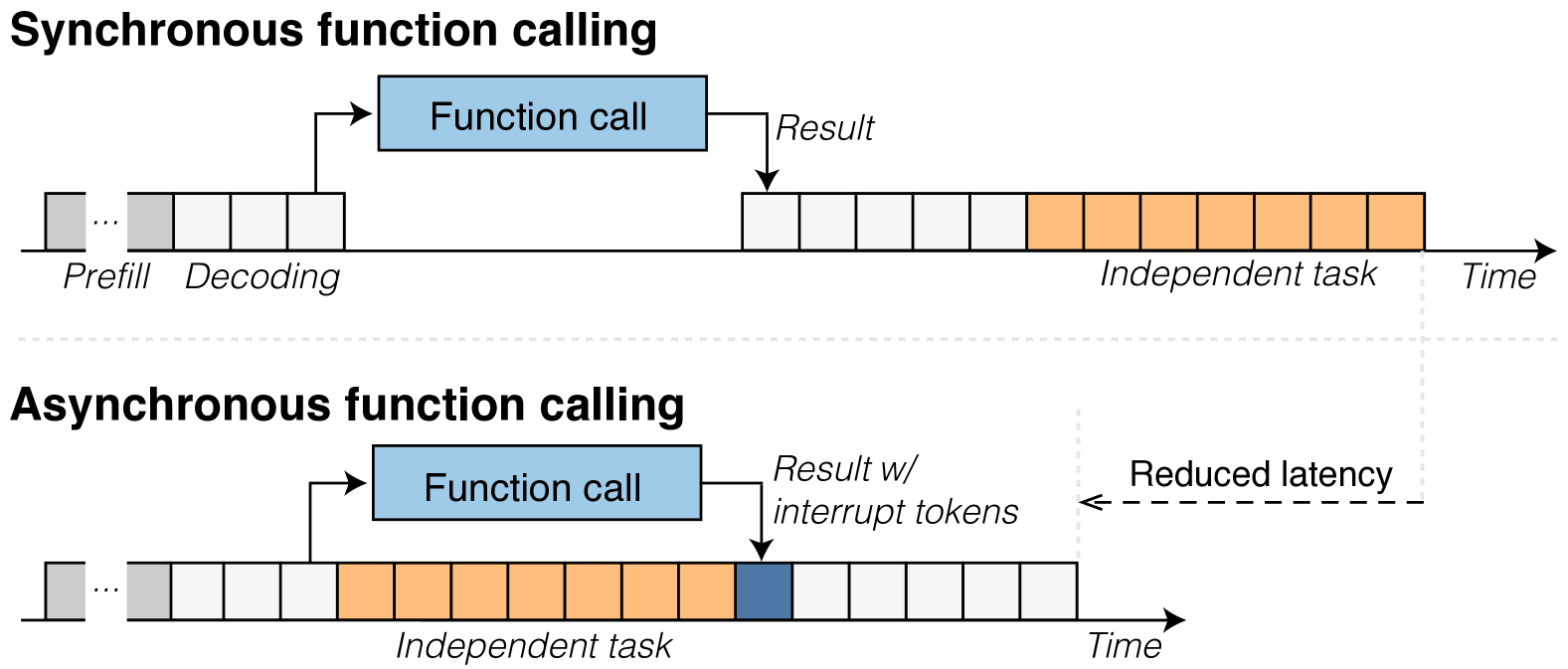
- 现有的LLM函数调用方法是同步的,导致每次调用都阻塞推理过程,限制了并发执行能力。
- 本文提出AsyncLM,通过引入中断机制实现异步函数调用,允许LLM并发生成和执行函数调用。
- 实验结果显示,AsyncLM在多个基准任务上将任务完成延迟减少了1.6倍至5.4倍,显著提升了效率。
📝 摘要(中文)
大型语言模型(LLMs)通过函数调用与外部工具和数据源进行交互。然而,现有的LLM函数调用方法是同步的,每次调用都会阻塞LLM推理,限制了LLM的操作和并发执行能力。本文提出了AsyncLM,一个用于异步LLM函数调用的系统。AsyncLM通过允许LLM并发生成和执行函数调用来提高操作效率。它引入了一种中断机制,在函数调用返回时异步通知正在进行中的LLM。我们设计了一种用于函数调用和中断的上下文协议,提供了适应中断语义的微调策略,并在LLM推理过程中高效实现这些机制。实验表明,AsyncLM在伯克利函数调用基准测试(BFCL)上相比于同步函数调用,能够将端到端任务完成延迟减少1.6倍至5.4倍。此外,我们讨论了如何扩展中断机制以实现新型的人类-LLM或LLM-LLM交互。
🔬 方法详解
问题定义:当前大型语言模型的函数调用是同步的,这意味着每次函数调用都会阻塞模型的推理过程,导致效率低下和并发能力不足。
核心思路:本文提出的AsyncLM系统通过引入异步函数调用和中断机制,使得LLM能够在等待函数调用返回的同时继续进行其他推理任务,从而提高整体效率。
技术框架:AsyncLM的整体架构包括函数调用生成模块、异步执行模块和中断通知模块。函数调用生成模块负责生成调用请求,异步执行模块处理函数调用的执行,而中断通知模块则在函数调用完成时通知LLM。
关键创新:AsyncLM的核心创新在于中断机制的引入,使得LLM能够在函数调用返回时异步接收结果,而不是阻塞等待。这一设计与传统的同步调用方法本质上不同,极大地提升了并发处理能力。
关键设计:在实现中,AsyncLM采用了特定的上下文协议来处理函数调用和中断,确保LLM能够正确理解和响应中断信号。此外,微调策略被设计用来适应新的中断语义,从而优化模型的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,AsyncLM在伯克利函数调用基准测试(BFCL)上相比于传统的同步函数调用,能够将任务完成延迟减少1.6倍至5.4倍。这一显著提升展示了异步函数调用在实际应用中的巨大潜力。
🎯 应用场景
AsyncLM的研究成果在多个领域具有广泛的应用潜力,包括智能助手、自动化客服和复杂数据处理等场景。通过提高LLM的并发处理能力,AsyncLM能够显著提升用户体验和系统响应速度,推动人机交互的进一步发展。
📄 摘要(原文)
Large language models (LLMs) use function calls to interface with external tools and data source. However, the current approach to LLM function calling is inherently synchronous, where each call blocks LLM inference, limiting LLM operation and concurrent function execution. In this work, we propose AsyncLM, a system for asynchronous LLM function calling. AsyncLM improves LLM's operational efficiency by enabling LLMs to generate and execute function calls concurrently. Instead of waiting for each call's completion, AsyncLM introduces an interrupt mechanism to asynchronously notify the LLM in-flight when function calls return. We design an in-context protocol for function calls and interrupts, provide fine-tuning strategy to adapt LLMs to the interrupt semantics, and implement these mechanisms efficiently on LLM inference process. We demonstrate that AsyncLM can reduce end-to-end task completion latency from 1.6x-5.4x compared to synchronous function calling on a set of benchmark tasks in the Berkeley function calling leaderboard (BFCL). Furthermore, we discuss how interrupt mechanisms can be extended to enable novel human-LLM or LLM-LLM interactions.