AutoReason: Automatic Few-Shot Reasoning Decomposition
作者: Arda Sevinc, Abdurrahman Gumus
分类: cs.CL, cs.AI
发布日期: 2024-12-09
🔗 代码/项目: GITHUB
💡 一句话要点
提出AutoReason,自动生成Few-Shot推理分解,提升LLM在问答任务中的推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动推理 链式思考 Few-Shot学习 问题分解 大型语言模型
📋 核心要点
- 现有CoT方法依赖于手工设计的few-shot示例提示,且无法根据不同的查询进行自我调整,限制了其应用。
- AutoReason通过将隐式查询分解为多个显式问题,自动生成推理链,提高模型的可解释性和推理能力。
- 在StrategyQA和HotpotQA数据集上的实验表明,AutoReason能够有效提高问答准确率,尤其在StrategyQA上表现突出。
📝 摘要(中文)
本文提出了一种名为AutoReason的系统,用于自动生成Chain of Thought (CoT) 推理链。该方法通过将隐式查询分解为多个显式问题,从而增强大型语言模型的多步隐式推理能力。这种分解过程为模型提供了可解释性,并改善了较弱语言模型的推理性能。作者在StrategyQA和HotpotQA两个问答数据集上验证了该方法的有效性,结果表明,该方法在两个数据集上均提高了准确率,尤其是在StrategyQA数据集上提升显著。该研究的完整源代码已在GitHub上公开。
🔬 方法详解
问题定义:现有的大型语言模型在进行复杂推理时,依赖于Chain of Thought (CoT) 方法,但CoT需要人工设计few-shot示例,成本高昂且泛化性差。此外,CoT无法根据不同的问题进行动态调整,导致在面对复杂或未见过的推理场景时表现不佳。因此,如何自动生成高质量的推理链,并使模型具备更强的自适应能力,是本文要解决的核心问题。
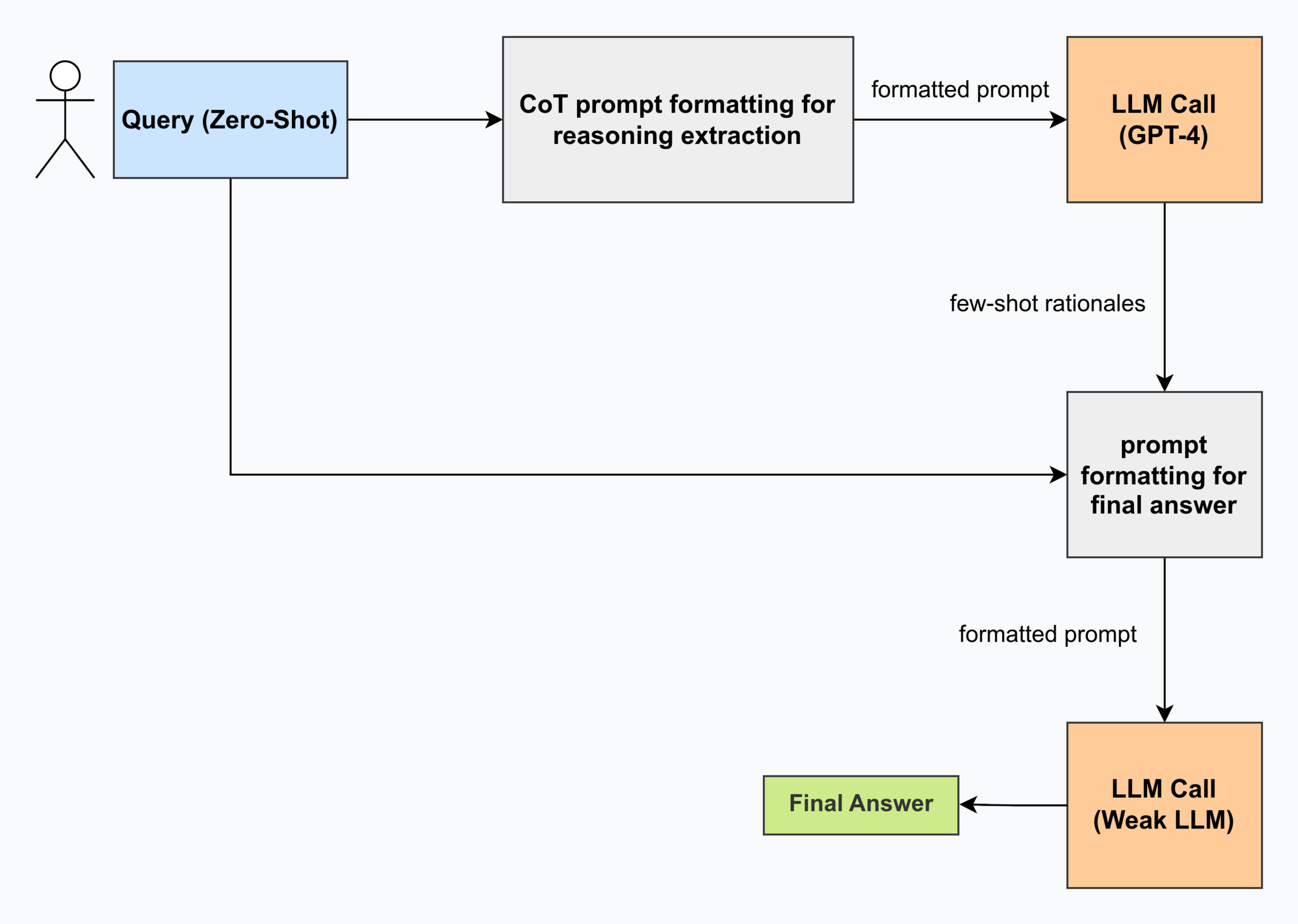
核心思路:AutoReason的核心思路是将复杂的隐式问题分解为一系列更简单、更明确的显式子问题。通过回答这些子问题,模型逐步构建推理链,最终得出原始问题的答案。这种分解的方式不仅提高了模型的可解释性,还使得模型能够更好地利用已有的知识,从而提升推理能力。
技术框架:AutoReason的整体框架包含以下几个主要阶段:1) 问题分解:将原始问题分解为一系列相关的子问题。2) 子问题解答:利用大型语言模型对每个子问题进行解答。3) 答案整合:将子问题的答案整合起来,形成最终的答案。4) 推理链构建:将子问题及其答案串联起来,形成完整的推理链。
关键创新:AutoReason最重要的创新在于其自动生成推理链的能力。与传统的CoT方法需要人工设计示例不同,AutoReason能够根据不同的问题自动生成相应的推理步骤,从而大大降低了人工成本,并提高了模型的泛化能力。此外,通过将问题分解为更小的子问题,AutoReason能够更好地利用大型语言模型的知识,从而提升推理的准确性。
关键设计:AutoReason的具体实现细节包括:1) 使用特定的提示工程技术来引导大型语言模型进行问题分解。2) 采用不同的策略来选择和排序子问题,以确保推理链的连贯性和有效性。3) 设计合适的答案整合机制,将子问题的答案组合成最终的答案。4) 使用特定的评估指标来衡量推理链的质量,并根据评估结果对模型进行优化。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AutoReason在StrategyQA和HotpotQA两个问答数据集上均取得了显著的性能提升。尤其是在StrategyQA数据集上,AutoReason的准确率提升幅度尤为明显,证明了其在复杂推理场景下的有效性。这些结果表明,通过自动生成推理链,AutoReason能够有效提高大型语言模型的推理能力。
🎯 应用场景
AutoReason具有广泛的应用前景,例如可以应用于智能客服、自动问答系统、知识图谱推理等领域。通过自动生成推理链,AutoReason可以帮助模型更好地理解用户的问题,并提供更准确、更可靠的答案。此外,AutoReason还可以用于教育领域,帮助学生理解复杂的概念和解决问题。未来,AutoReason有望成为提升人工智能系统推理能力的关键技术。
📄 摘要(原文)
Chain of Thought (CoT) was introduced in recent research as a method for improving step-by-step reasoning in Large Language Models. However, CoT has limited applications such as its need for hand-crafted few-shot exemplar prompts and no capability to adjust itself to different queries. In this work, we propose a system to automatically generate rationales using CoT. Our method improves multi-step implicit reasoning capabilities by decomposing the implicit query into several explicit questions. This provides interpretability for the model, improving reasoning in weaker LLMs. We test our approach with two Q\&A datasets: StrategyQA and HotpotQA. We show an increase in accuracy with both, especially on StrategyQA. To facilitate further research in this field, the complete source code for this study has been made publicly available on GitHub: https://github.com/miralab-ai/autoreason.