LLM-BIP: Structured Pruning for Large Language Models with Block-Wise Forward Importance Propagation
作者: Haihang Wu
分类: cs.CL, cs.AI
发布日期: 2024-12-09
💡 一句话要点
LLM-BIP:基于块级前向重要性传播的大语言模型结构化剪枝
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 结构化剪枝 重要性传播 模型压缩 Lipschitz连续性
📋 核心要点
- 现有全局剪枝方法依赖不可靠的梯度评估连接重要性,而逐层剪枝则存在误差累积问题,导致剪枝效果不佳。
- LLM-BIP通过块级重要性得分传播,精确评估连接对Transformer块输出的影响,并利用Lipschitz连续性进行高效近似。
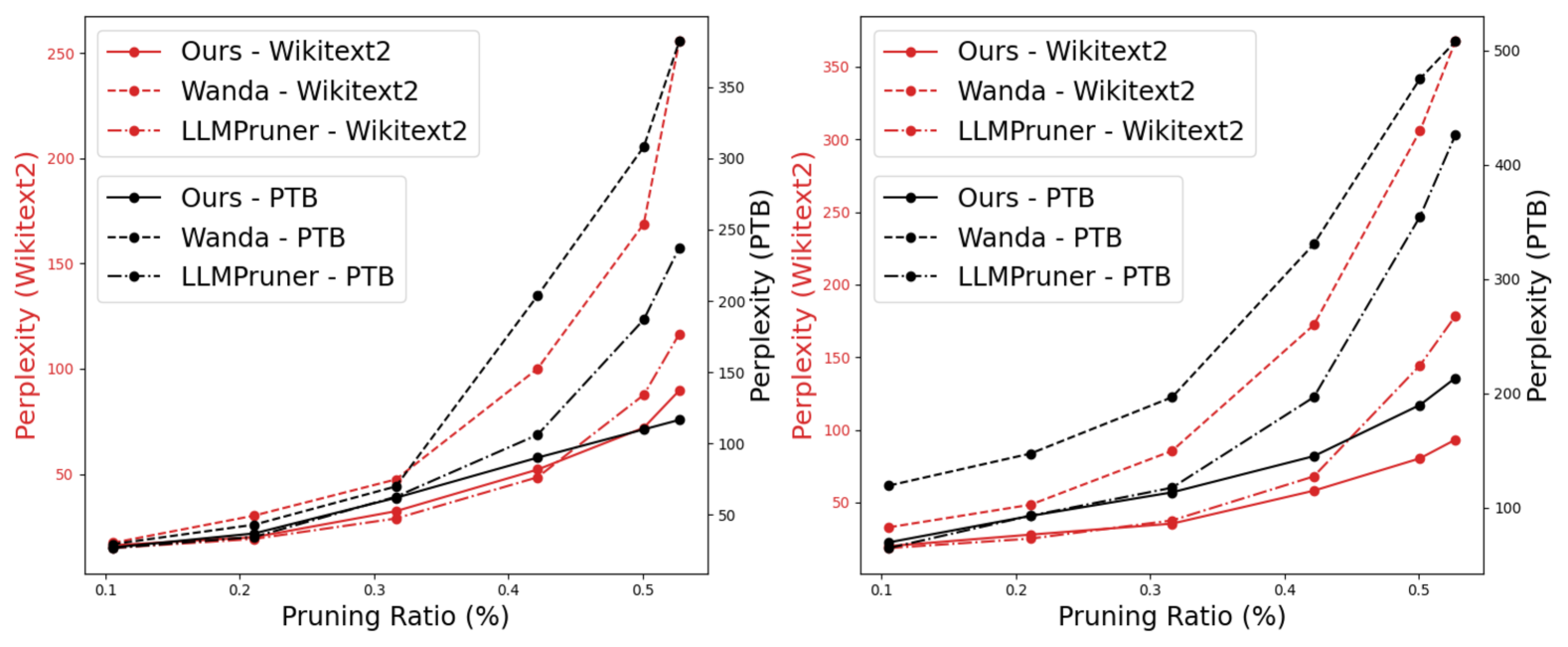
- 实验结果表明,LLM-BIP在常见推理任务中平均提升3.26%准确率,并在WikiText2和PTB数据集上显著降低困惑度。
📝 摘要(中文)
大型语言模型(LLMs)在各种语言任务中表现出卓越的性能,但其庞大的规模和高计算成本阻碍了它们的广泛部署。结构化剪枝是一种流行的技术,通过移除冗余连接(结构化分组参数),如通道和注意力头,将稀疏性引入预训练模型,并促进推理期间的直接硬件加速。现有的结构化剪枝方法通常采用全局或逐层剪枝标准;然而,它们受到连接重要性评估不准确导致的效果不佳的阻碍。全局剪枝方法通常使用接近于零且不可靠的梯度来评估组件的重要性,而逐层剪枝方法则遇到显著的剪枝误差累积问题。为此,我们提出了一种基于块级重要性得分传播的更准确的剪枝指标,称为LLM-BIP。具体来说,LLM-BIP通过衡量连接对各自Transformer块输出的影响来精确评估连接的重要性,这可以通过在Lipschitz连续性假设下导出的上限的单次前向传递来有效地近似。我们使用LLaMA-7B、Vicuna-7B和LLaMA-13B在常见的零样本任务中评估了所提出的方法。结果表明,与之前的最佳基线相比,我们的方法在常见推理任务中的准确率平均提高了3.26%。它还在WikiText2数据集和PTB数据集上的困惑度分别平均降低了14.09和68.76。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)结构化剪枝中连接重要性评估不准确的问题。现有的全局剪枝方法依赖于不稳定的梯度信息,而逐层剪枝则会累积误差,导致剪枝后的模型性能下降。因此,如何更准确地评估连接的重要性,从而实现更有效的结构化剪枝,是本文要解决的关键问题。
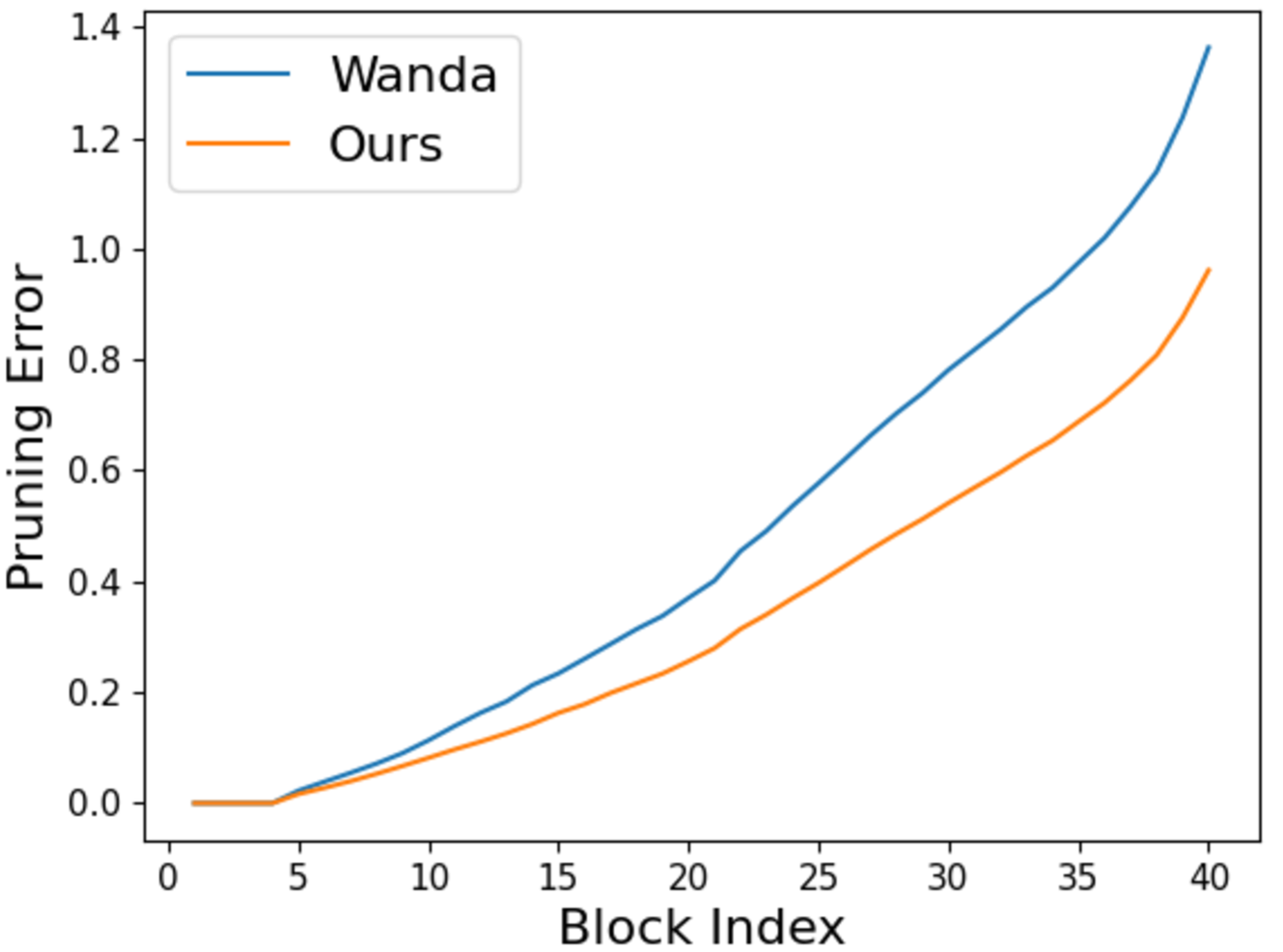
核心思路:论文的核心思路是通过块级重要性传播来更精确地评估连接的重要性。不同于全局或逐层的方法,LLM-BIP关注每个连接对Transformer块输出的影响。通过衡量这种影响,可以更准确地判断哪些连接是冗余的,从而进行更有效的剪枝。这种方法的设计基于这样的假设:一个连接的重要性应该与其对模型最终输出的影响相关联。
技术框架:LLM-BIP的技术框架主要包含以下几个步骤:1) 对LLM进行前向传播,计算每个Transformer块的输出;2) 利用Lipschitz连续性假设,推导出一个上限,用于近似计算每个连接对相应Transformer块输出的影响;3) 基于计算出的影响值,对连接的重要性进行排序;4) 根据设定的剪枝比例,移除重要性较低的连接。整个过程只需要一次前向传播,因此效率较高。
关键创新:LLM-BIP最重要的技术创新点在于提出了块级重要性传播的概念,并利用Lipschitz连续性进行高效近似。与现有方法相比,LLM-BIP不再依赖于不稳定的梯度信息,而是直接衡量连接对Transformer块输出的影响,从而更准确地评估连接的重要性。此外,利用Lipschitz连续性进行近似计算,大大提高了计算效率。
关键设计:LLM-BIP的关键设计包括:1) 如何定义连接对Transformer块输出的影响;2) 如何利用Lipschitz连续性推导出一个可高效计算的上限;3) 如何选择合适的剪枝比例。论文中具体采用了Frobenius范数来衡量连接对Transformer块输出的影响,并基于Lipschitz连续性推导出了一个易于计算的上限。剪枝比例的选择则需要根据具体的任务和模型进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM-BIP在LLaMA-7B、Vicuna-7B和LLaMA-13B等模型上取得了显著的性能提升。在常见推理任务中,LLM-BIP的准确率平均提高了3.26%,并且在WikiText2和PTB数据集上的困惑度分别平均降低了14.09和68.76。这些结果表明,LLM-BIP能够有效地进行结构化剪枝,并在保持模型性能的同时显著降低计算成本。
🎯 应用场景
LLM-BIP具有广泛的应用前景,可用于压缩和加速大型语言模型,使其能够在资源受限的设备上部署,例如移动设备和边缘服务器。通过降低模型大小和计算成本,LLM-BIP可以促进LLM在各个领域的应用,例如智能助手、机器翻译和文本生成等,并降低部署成本。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable performance across various language tasks, but their widespread deployment is impeded by their large size and high computational costs. Structural pruning is a prevailing technique used to introduce sparsity into pre-trained models and facilitate direct hardware acceleration during inference by removing redundant connections (structurally-grouped parameters), such as channels and attention heads. Existing structural pruning approaches often employ either global or layer-wise pruning criteria; however, they are hindered by ineffectiveness stemming from inaccurate evaluation of connection importance. Global pruning methods typically assess component importance using near-zero and unreliable gradients, while layer-wise pruning approaches encounter significant pruning error accumulation issues. To this end, we propose a more accurate pruning metric based on the block-wise importance score propagation, termed LLM-BIP. Specifically, LLM-BIP precisely evaluates connection importance by gauging its influence on the respective transformer block output, which can be efficiently approximated in a single forward pass through an upper bound derived from the assumption of Lipschitz continuity. We evaluate the proposed method using LLaMA-7B, Vicuna-7B, and LLaMA-13B across common zero-shot tasks. The results demonstrate that our approach achieves an average of 3.26% increase in accuracy for common reasoning tasks compared to previous best baselines. It also reduces perplexity by 14.09 and 68.76 on average for the WikiText2 dataset and PTB dataset, respectively.