Evaluating LLM-based Approaches to Legal Citation Prediction: Domain-specific Pre-training, Fine-tuning, or RAG? A Benchmark and an Australian Law Case Study
作者: Jiuzhou Han, Paul Burgess, Ehsan Shareghi
分类: cs.CL, cs.AI, cs.IR
发布日期: 2024-12-09 (更新: 2025-05-22)
备注: For code, data, and models see https://auslawbench.github.io
💡 一句话要点
提出AusLaw Citation Benchmark,评估LLM在法律引用预测中的应用,并探索领域预训练、微调和RAG方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 法律引用预测 大型语言模型 检索增强生成 领域预训练 微调 澳大利亚法律 基准测试
📋 核心要点
- 法律引用预测任务需要细粒度的上下文理解和精确的法律条文识别,现有方法难以有效解决。
- 论文探索了领域预训练、微调和检索增强生成(RAG)等方法,并结合LLM进行法律引用预测。
- 实验表明,指令调优的LLM表现最佳,但仍有较大提升空间,证明了基准测试的价值。
📝 摘要(中文)
大型语言模型(LLM)在法律任务中展现出巨大潜力,但法律引用预测问题仍未得到充分研究。该任务的核心在于对上下文的细粒度理解以及对相关法律或判例的精确识别。我们引入了AusLaw Citation Benchmark,这是一个包含5.5万个澳大利亚法律实例和18,677个唯一引用的真实世界数据集,据我们所知,这是同等规模和范围内的首个数据集。我们对一系列解决方案进行了系统基准测试:(i)通用和法律专用LLM的标准提示,(ii)具有通用和领域特定嵌入的检索管道,(iii)监督微调,以及(iv)几种混合策略,将LLM与通过查询扩展、投票集成或重新排序的检索增强相结合。结果表明,通用或法律专用LLM都不能作为独立解决方案,性能接近于零。在特定任务数据集上进行指令调优(即使是通用的开源LLM)是表现最佳的解决方案之一。我们强调,数据库粒度以及嵌入类型在基于检索的方法中起着关键作用,而利用训练过的重排序器的混合方法能够提供最佳结果。尽管如此,仍然存在近50%的性能差距,突显了这个具有挑战性的基准作为法律领域未来研究的严格测试平台的价值。
🔬 方法详解
问题定义:论文旨在解决法律引用预测问题,即给定一段法律文本,预测其中应该引用哪些法律条文或判例。现有方法,包括通用LLM和法律专用LLM,在该任务上表现不佳,无法有效捕捉法律文本的细粒度语义和上下文信息。
核心思路:论文的核心思路是结合LLM的语言理解能力和检索增强技术,通过检索相关法律知识来辅助LLM进行引用预测。同时,探索不同的训练策略,包括领域预训练、微调和指令调优,以提升LLM在法律领域的性能。
技术框架:整体框架包括以下几个主要模块:1) 数据集构建:构建大规模的澳大利亚法律引用数据集AusLaw Citation Benchmark。2) 基线方法:评估通用LLM和法律专用LLM的直接提示效果。3) 检索模块:使用通用和领域特定的嵌入模型进行法律条文检索。4) 微调模块:对LLM进行监督微调和指令调优。5) 混合策略:结合检索增强和LLM,通过查询扩展、投票集成或重排序等方式提升性能。
关键创新:论文的关键创新在于:1) 构建了大规模的澳大利亚法律引用数据集AusLaw Citation Benchmark,为法律领域的LLM研究提供了基准。2) 系统地评估了多种LLM应用策略,包括直接提示、微调和检索增强,并分析了不同方法的优缺点。3) 提出了结合重排序器的混合方法,有效提升了法律引用预测的性能。
关键设计:在检索模块中,论文比较了不同类型的嵌入模型,包括通用嵌入和领域特定嵌入,并分析了数据库粒度对检索效果的影响。在混合策略中,论文使用了训练过的重排序器来对检索结果进行排序,从而提升了引用预测的准确性。指令调优使用了特定任务数据集,优化了LLM的生成能力。
🖼️ 关键图片
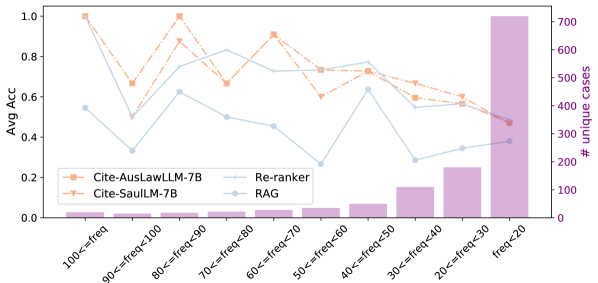
📊 实验亮点
实验结果表明,通用和法律专用LLM的直接提示效果不佳,性能接近于零。指令调优的LLM在特定任务数据集上表现最佳。结合重排序器的混合方法能够显著提升性能,但仍有近50%的性能差距,表明该基准测试具有挑战性。
🎯 应用场景
该研究成果可应用于智能法律咨询、法律文书自动生成、法律信息检索等领域,有助于提高法律工作的效率和准确性。未来,该研究可以扩展到其他法律体系,并与其他法律任务相结合,构建更智能的法律AI系统。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated strong potential across legal tasks, yet the problem of legal citation prediction remains under-explored. At its core, this task demands fine-grained contextual understanding and precise identification of relevant legislation or precedent. We introduce the AusLaw Citation Benchmark, a real-world dataset comprising 55k Australian legal instances and 18,677 unique citations which to the best of our knowledge is the first of its scale and scope. We then conduct a systematic benchmarking across a range of solutions: (i) standard prompting of both general and law-specialised LLMs, (ii) retrieval-only pipelines with both generic and domain-specific embeddings, (iii) supervised fine-tuning, and (iv) several hybrid strategies that combine LLMs with retrieval augmentation through query expansion, voting ensembles, or re-ranking. Results show that neither general nor law-specific LLMs suffice as stand-alone solutions, with performance near zero. Instruction tuning (of even a generic open-source LLM) on task-specific dataset is among the best performing solutions. We highlight that database granularity along with the type of embeddings play a critical role in retrieval-based approaches, with hybrid methods which utilise a trained re-ranker delivering the best results. Despite this, a performance gap of nearly 50% remains, underscoring the value of this challenging benchmark as a rigorous test-bed for future research in legal-domain.