A Comparative Study of Learning Paradigms in Large Language Models via Intrinsic Dimension
作者: Saahith Janapati, Yangfeng Ji
分类: cs.CL
发布日期: 2024-12-09 (更新: 2025-05-20)
💡 一句话要点
通过固有维度比较大型语言模型中监督微调和上下文学习的表征差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 监督微调 上下文学习 固有维度 表征学习
📋 核心要点
- 大型语言模型可以通过监督微调和上下文学习两种方式提升性能,但二者机制不同,需要深入理解其影响。
- 该论文利用固有维度(ID)来量化和比较监督微调和上下文学习对LLM表征空间的影响。
- 研究发现,上下文学习相比监督微调,能够诱导出更高维度的表征空间,揭示了两种学习范式的差异。
📝 摘要(中文)
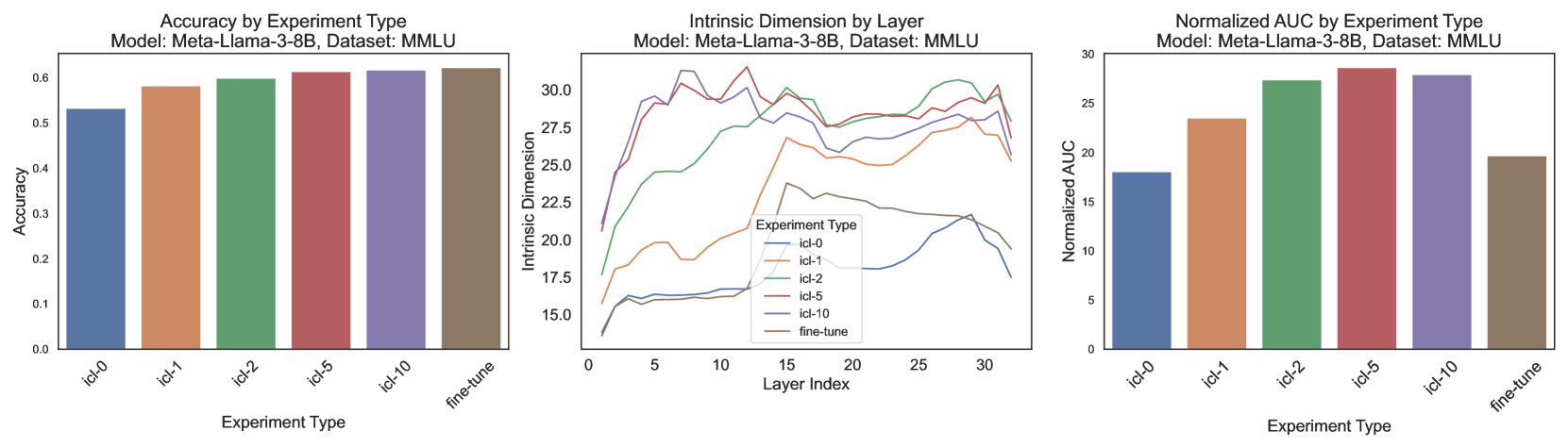
大型语言模型(LLMs)在自然语言任务上的性能可以通过监督微调(SFT)和上下文学习(ICL)来提高,这两种方法通过不同的机制运作。监督微调通过最小化训练数据上的损失来更新模型的权重,而上下文学习则利用嵌入在提示中的任务演示,而不改变模型的参数。本研究使用固有维度(ID)来研究这些学习范式对LLMs隐藏表示的影响。我们使用ID来估计从LLMs提取的表示在执行特定自然语言任务时的自由度。我们首先探讨了LLM表示的ID在SFT期间如何演变,以及它如何因ICL中的演示数量而变化。然后,我们比较了SFT和ICL引起的ID,发现ICL始终比SFT产生更高的ID,这表明ICL期间生成的表示位于嵌入空间中更高维的流形中。
🔬 方法详解
问题定义:论文旨在研究监督微调(SFT)和上下文学习(ICL)这两种不同的学习范式对大型语言模型(LLM)内部表征的影响。现有方法缺乏对这两种范式如何影响LLM表征空间的深入理解,特别是它们如何改变表征的复杂性和自由度。
核心思路:论文的核心思路是使用固有维度(Intrinsic Dimension, ID)作为一种度量标准,来量化LLM在执行特定任务时其内部表征的复杂性。ID可以理解为表征空间中有效自由度的数量,更高的ID意味着表征更加复杂,能够捕捉更多的信息。通过比较SFT和ICL下LLM表征的ID,可以揭示这两种学习范式在表征学习上的差异。
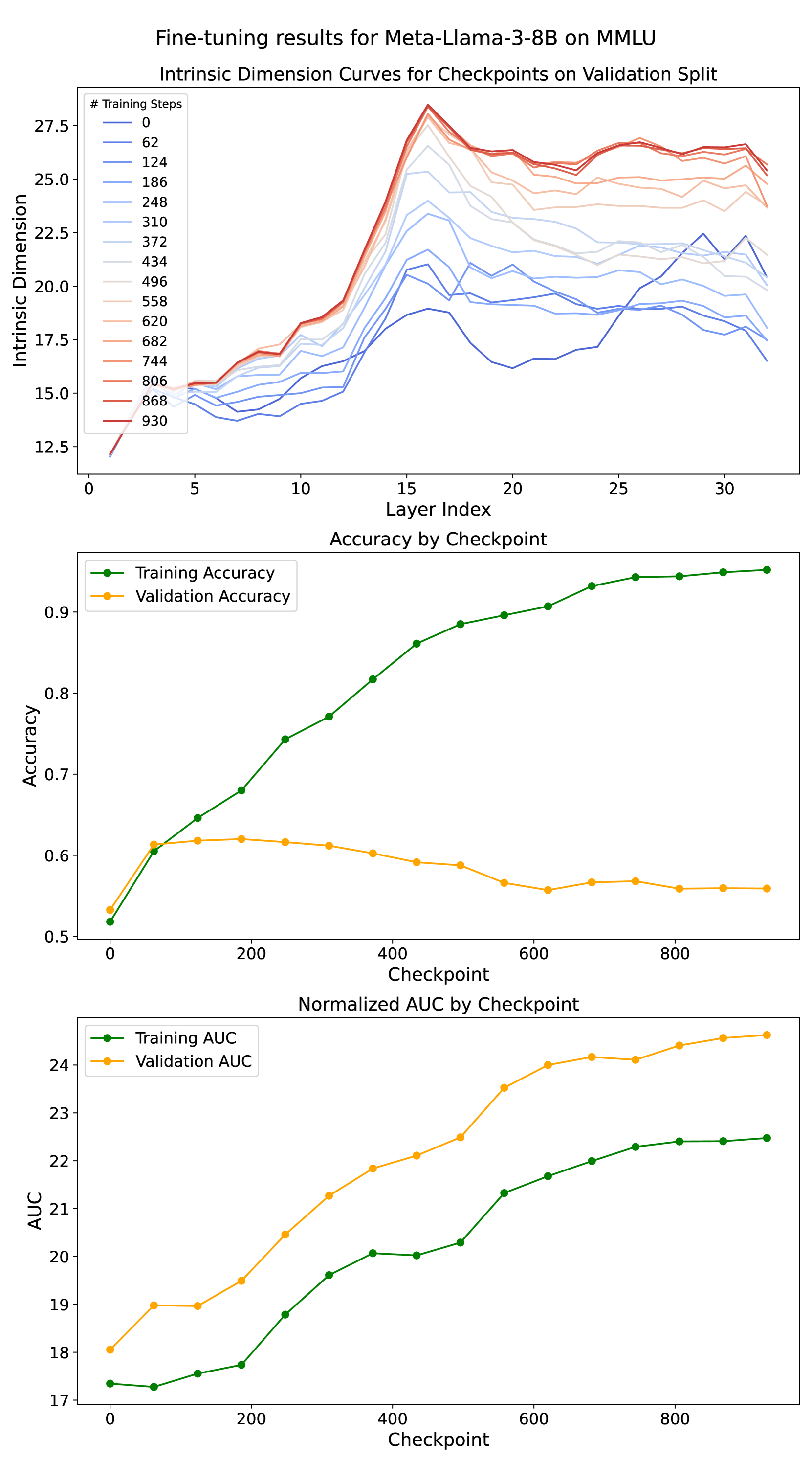
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择合适的LLM模型;2) 使用SFT或ICL对模型进行训练或提示;3) 从模型中提取中间层的表征;4) 使用ID估计方法计算这些表征的固有维度;5) 比较不同学习范式下ID的差异。具体来说,研究首先探索了SFT过程中ID的演变,以及ICL中演示数量对ID的影响。然后,直接比较了SFT和ICL所诱导的ID值。
关键创新:该论文的关键创新在于将固有维度(ID)引入到LLM表征学习的研究中。ID提供了一种量化表征复杂性的有效方法,使得研究者能够更深入地理解不同学习范式对LLM内部运作的影响。与以往主要关注模型性能的研究不同,该研究侧重于分析模型内部的表征,从而揭示了SFT和ICL在表征学习上的本质区别。
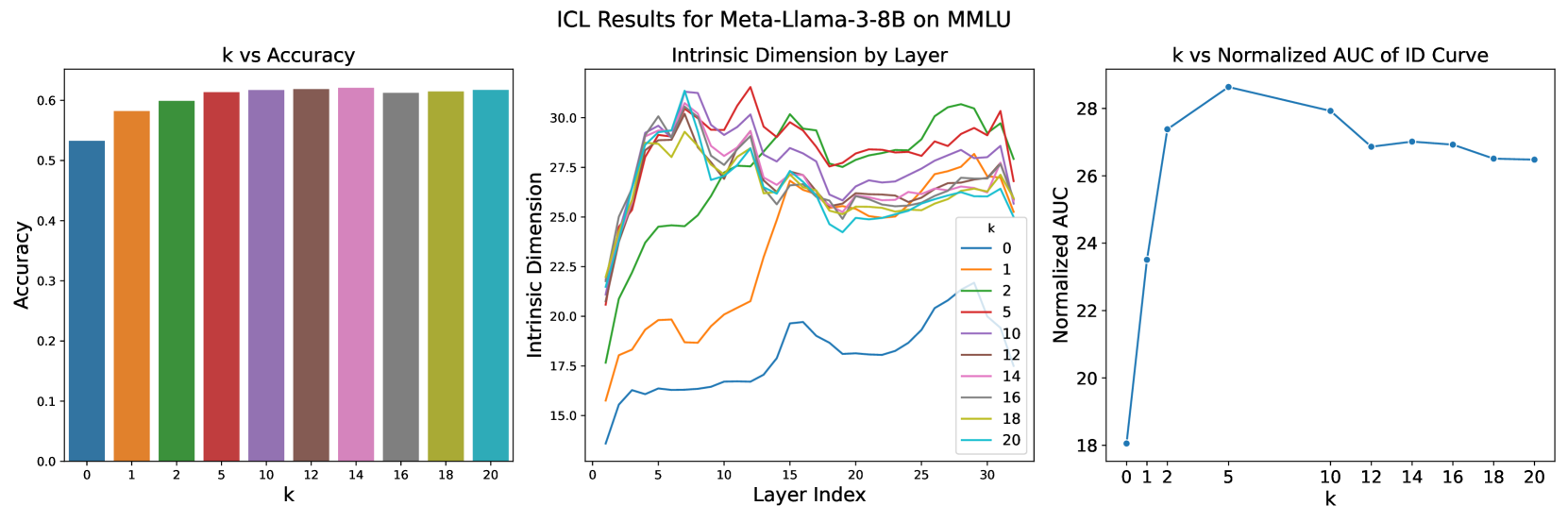
关键设计:论文的关键设计包括:1) 使用不同的自然语言任务来评估SFT和ICL的效果;2) 采用多种ID估计方法来保证结果的鲁棒性;3) 控制实验变量,例如SFT的训练数据量和ICL的演示数量,以便更清晰地观察不同因素对ID的影响。具体的参数设置和损失函数取决于所使用的LLM模型和SFT的训练目标。对于ICL,关键在于选择合适的演示样本,以确保模型能够有效地学习到任务的知识。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在相同的自然语言任务上,上下文学习(ICL)始终比监督微调(SFT)产生更高的固有维度(ID)。这表明ICL生成的表征位于更高维度的流形中,能够捕捉更多的信息。具体数值提升未知,但结论具有统计显著性。
🎯 应用场景
该研究成果可应用于理解和优化大型语言模型的训练和使用。通过了解不同学习范式对模型表征的影响,可以更好地选择合适的训练方法,提高模型在特定任务上的性能。此外,该研究也有助于开发更高效的上下文学习策略,减少对大量演示数据的依赖。
📄 摘要(原文)
The performance of Large Language Models (LLMs) on natural language tasks can be improved through both supervised fine-tuning (SFT) and in-context learning (ICL), which operate via distinct mechanisms. Supervised fine-tuning updates the model's weights by minimizing loss on training data, whereas in-context learning leverages task demonstrations embedded in the prompt, without changing the model's parameters. This study investigates the effects of these learning paradigms on the hidden representations of LLMs using Intrinsic Dimension (ID). We use ID to estimate the number of degrees of freedom between representations extracted from LLMs as they perform specific natural language tasks. We first explore how the ID of LLM representations evolves during SFT and how it varies due to the number of demonstrations in ICL. We then compare the IDs induced by SFT and ICL and find that ICL consistently induces a higher ID compared to SFT, suggesting that representations generated during ICL reside in higher dimensional manifolds in the embedding space.