LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods
作者: Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, Yiqun Liu
分类: cs.CL, cs.IR
发布日期: 2024-12-07 (更新: 2024-12-10)
备注: 60 pages, comprehensive and continuously updated
🔗 代码/项目: GITHUB
💡 一句话要点
全面综述:基于大型语言模型(LLM)的评估方法研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM评估 自然语言处理 自动化评估 LLMs-as-judges
📋 核心要点
- 现有评估方法在有效性、泛化性和可解释性方面存在不足,难以满足快速发展的LLM应用需求。
- 论文核心思想是利用LLM作为评估者,基于自然语言响应进行评估,充分发挥LLM的语言理解和生成能力。
- 论文对LLMs-as-judges范式进行了全面综述,分析了其功能、方法、应用、评估和局限性,为研究和实践提供指导。
📝 摘要(中文)
大型语言模型(LLM)的快速发展推动了其在各个领域的广泛应用。其中一个最有前景的应用是基于自然语言响应作为评估者,即“LLMs-as-judges”。这种框架因其卓越的有效性、跨任务泛化能力以及自然语言形式的可解释性而受到学术界和工业界的日益关注。本文从五个关键角度对LLMs-as-judges范式进行了全面综述:功能、方法、应用、元评估和局限性。首先,我们系统地定义了LLMs-as-Judges,并介绍了它们的功能(为什么要使用LLM judges?)。然后,我们讨论了使用LLM构建评估系统的方法(如何使用LLM judges?)。此外,我们还研究了它们的应用领域(在哪里使用LLM judges?),并讨论了在各种上下文中评估它们的方法(如何评估LLM judges?)。最后,我们详细分析了LLM judges的局限性,并讨论了潜在的未来方向。通过结构化和全面的分析,我们旨在为LLMs-as-judges在研究和实践中的开发和应用提供见解。我们将继续在https://github.com/CSHaitao/Awesome-LLMs-as-Judges维护相关资源列表。
🔬 方法详解
问题定义:现有的人工评估成本高昂且主观性强,传统的自动化评估方法在处理复杂的自然语言任务时效果不佳,难以捕捉到LLM生成文本的细微差别和语义信息。因此,需要一种更有效、更客观、更具泛化能力的评估方法来评估LLM的性能。
核心思路:论文的核心思路是利用LLM自身强大的语言理解和生成能力,将其作为评估者(LLM-as-Judge),直接对LLM生成的自然语言响应进行评估。这种方法可以充分利用LLM的知识和推理能力,从而更准确地评估LLM的性能。
技术框架:论文对LLMs-as-judges范式进行了系统性的梳理和分析,主要从以下五个方面展开: 1. 功能(Functionality):探讨了使用LLM作为评估者的动机和优势。 2. 方法(Methodology):介绍了如何构建基于LLM的评估系统,包括prompt设计、评估流程等。 3. 应用(Applications):调研了LLMs-as-judges在不同领域的应用,例如机器翻译、文本摘要等。 4. 元评估(Meta-evaluation):讨论了如何评估LLM评估者的性能,例如与人工评估结果的对比。 5. 局限性(Limitations):分析了LLM评估者的局限性,例如偏见、幻觉等。
关键创新:该综述的关键创新在于其全面性和系统性,它不仅总结了现有的LLMs-as-judges方法,还深入分析了其优势、劣势和未来发展方向。与以往的综述相比,该论文更加关注LLM评估者的内在机制和评估方法,为研究人员提供了更深入的理解。
关键设计:论文本身是一篇综述,因此没有具体的参数设置、损失函数或网络结构等技术细节。但是,论文中讨论了prompt设计对LLM评估结果的影响,并提出了多种prompt设计策略,例如使用清晰明确的指令、提供参考答案等。此外,论文还讨论了如何利用LLM的置信度信息来提高评估的准确性。
🖼️ 关键图片

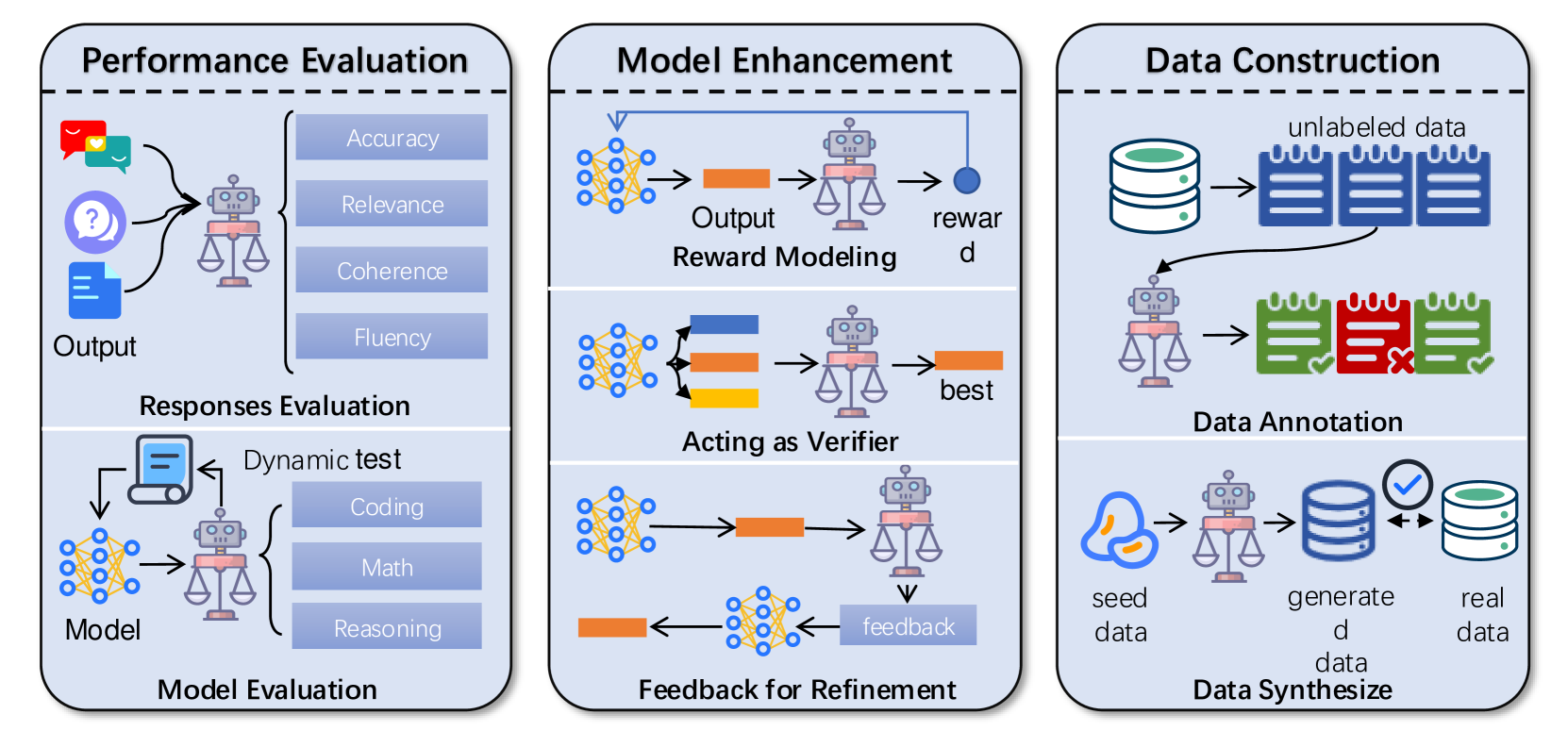
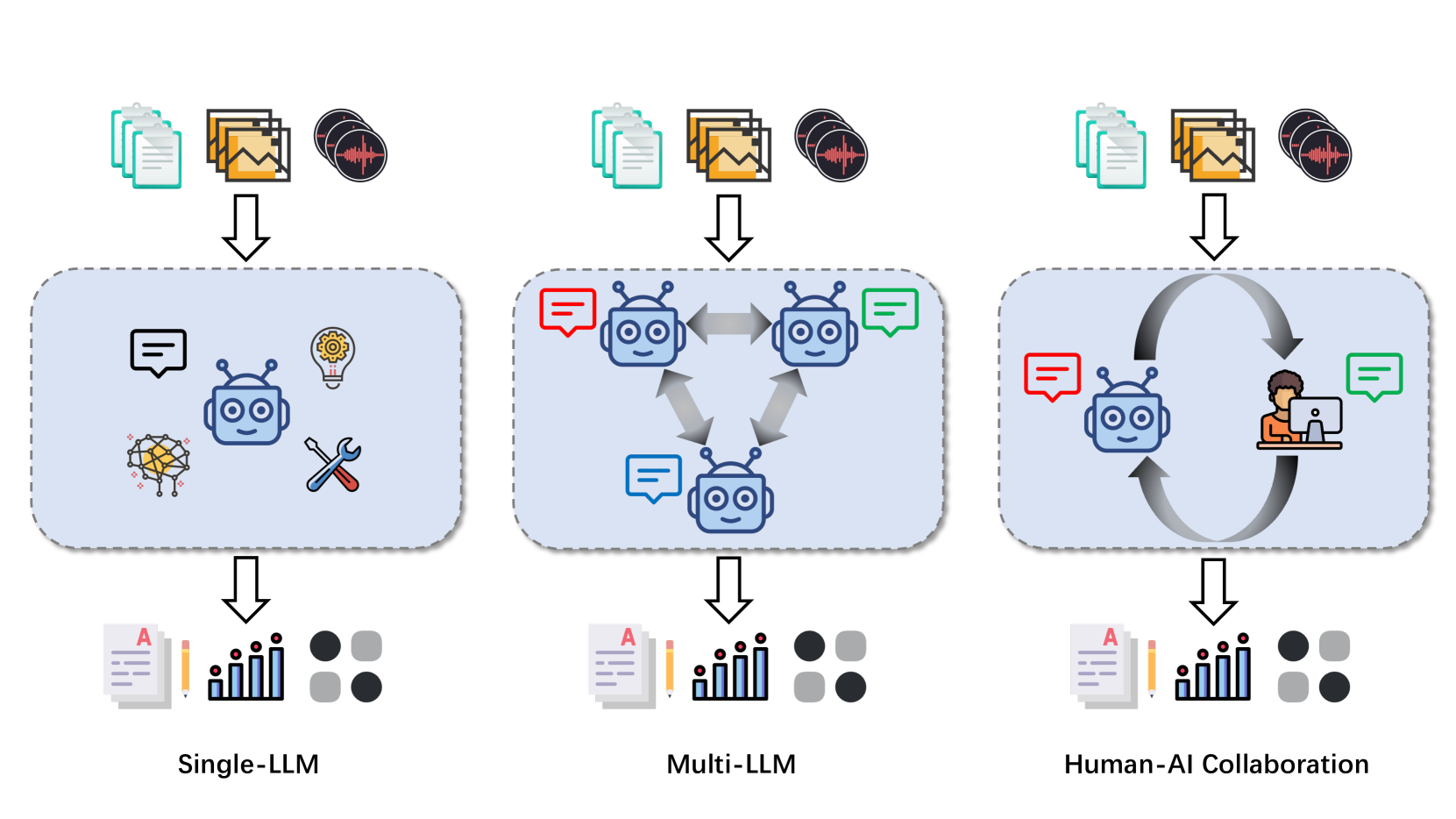
📊 实验亮点
该论文是一篇全面的综述,系统地总结了LLMs-as-judges的研究进展,并深入分析了其优势、劣势和未来发展方向。该综述为研究人员提供了一个清晰的LLMs-as-judges全景图,并为未来的研究提供了有价值的指导。
🎯 应用场景
LLMs-as-judges具有广泛的应用前景,可用于自动化评估机器翻译、文本摘要、对话生成等自然语言生成任务。它还可以用于评估LLM在各种下游任务中的表现,例如问答、文本分类等。该研究有助于推动LLM的开发和应用,提高LLM的性能和可靠性。
📄 摘要(原文)
The rapid advancement of Large Language Models (LLMs) has driven their expanding application across various fields. One of the most promising applications is their role as evaluators based on natural language responses, referred to as ''LLMs-as-judges''. This framework has attracted growing attention from both academia and industry due to their excellent effectiveness, ability to generalize across tasks, and interpretability in the form of natural language. This paper presents a comprehensive survey of the LLMs-as-judges paradigm from five key perspectives: Functionality, Methodology, Applications, Meta-evaluation, and Limitations. We begin by providing a systematic definition of LLMs-as-Judges and introduce their functionality (Why use LLM judges?). Then we address methodology to construct an evaluation system with LLMs (How to use LLM judges?). Additionally, we investigate the potential domains for their application (Where to use LLM judges?) and discuss methods for evaluating them in various contexts (How to evaluate LLM judges?). Finally, we provide a detailed analysis of the limitations of LLM judges and discuss potential future directions. Through a structured and comprehensive analysis, we aim aims to provide insights on the development and application of LLMs-as-judges in both research and practice. We will continue to maintain the relevant resource list at https://github.com/CSHaitao/Awesome-LLMs-as-Judges.