A polar coordinate system represents syntax in large language models
作者: Pablo Diego-Simón, Stéphane D'Ascoli, Emmanuel Chemla, Yair Lakretz, Jean-Rémi King
分类: cs.CL
发布日期: 2024-12-07
期刊: NeurIPS 2024
💡 一句话要点
提出Polar Probe,利用极坐标系揭示大语言模型中的句法结构表示。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 句法结构 极坐标系 结构探针 神经激活 句法关系 表征学习
📋 核心要点
- 现有结构探针仅能表示句法关系的存在,无法区分类型和方向,限制了对LLM句法理解的深入分析。
- 提出Polar Probe,利用词嵌入的距离和方向信息,以极坐标系的方式编码句法关系,从而捕捉句法关系的类型和方向。
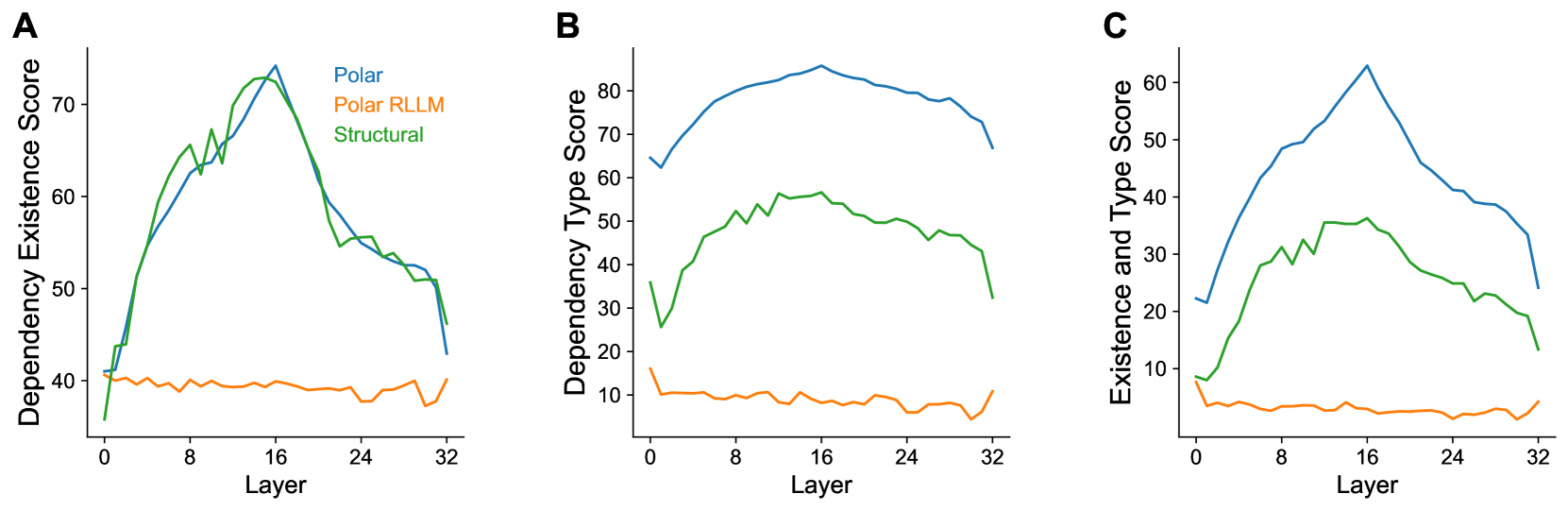
- 实验表明,Polar Probe显著优于结构探针,并在LLM中间层发现了这种极坐标系,且在更先进的模型中精度更高。
📝 摘要(中文)
句法树最初以符号表示形式进行形式化,但大型语言模型(LLM)的激活中也可以有效地表示句法树。事实上,“结构探针”可以找到神经激活的一个子空间,其中句法相关的词彼此相对接近。然而,这种句法编码仍然不完整:结构探针词嵌入之间的距离可以表示句法关系的存在,但不能表示句法关系的类型和方向。本文假设句法关系实际上是由附近嵌入之间的相对方向编码的。为了验证这一假设,我们引入了一个“极坐标探针”,经过训练可以从词嵌入之间的距离和方向读取句法关系。我们的方法揭示了三个主要发现。首先,我们的极坐标探针成功地恢复了句法关系的类型和方向,并且比结构探针的性能提高了近两倍。其次,我们证实这种极坐标系存在于许多LLM中间层的低维子空间中,并且在最新的前沿模型中变得越来越精确。第三,我们通过一个新的基准证明,相似的句法关系在句法树的嵌套层级中以相似的方式编码。总的来说,这项工作表明,LLM自发地学习了一种神经激活的几何结构,该结构明确地表示了语言理论的主要符号结构。
🔬 方法详解
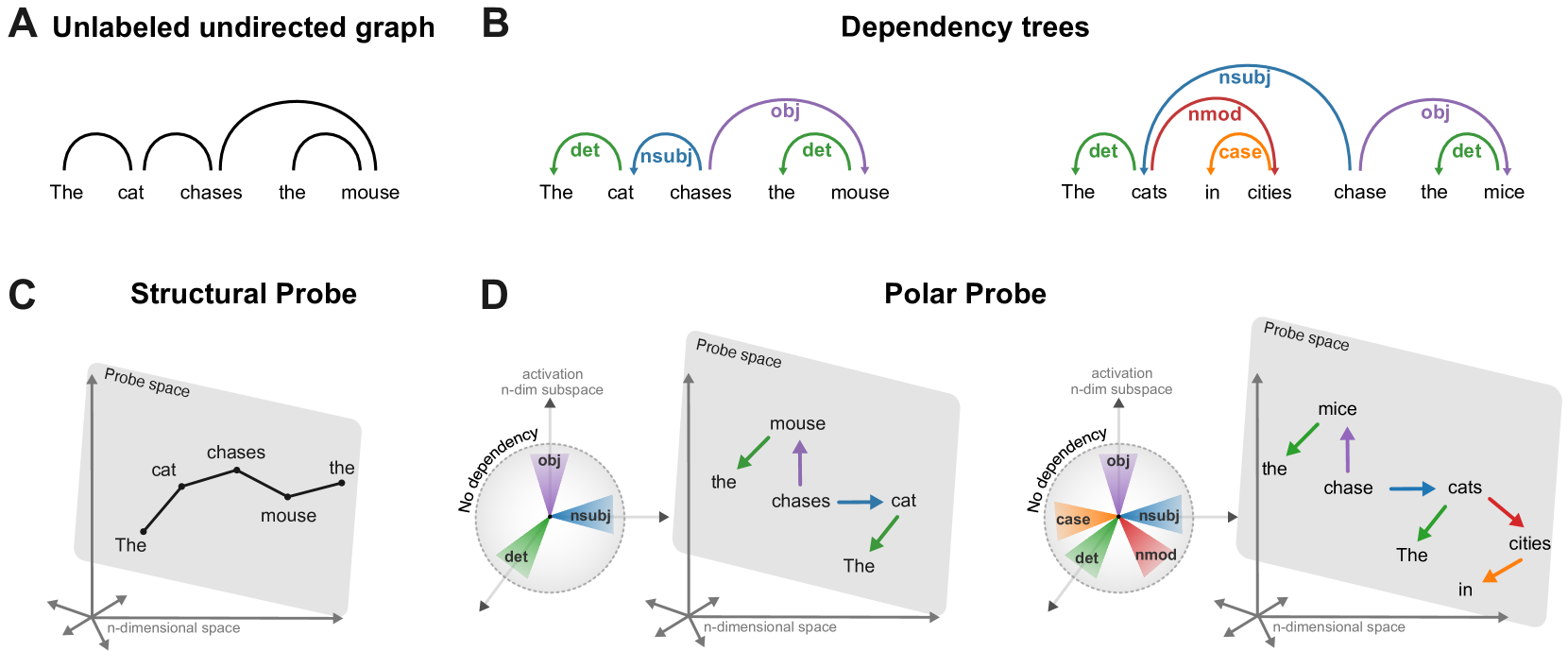
问题定义:现有方法,特别是基于“结构探针”的方法,虽然能够在大语言模型(LLM)的激活空间中找到与句法结构相关的子空间,但它们主要依赖于词嵌入之间的距离来表示句法关系。这种方法的局限性在于,它只能表示句法关系的存在,而无法区分不同类型的句法关系(例如,主谓关系与动宾关系)以及这些关系的方向(例如,修饰语在前还是在后)。因此,如何更完整、更准确地从LLM的激活中提取句法信息,成为了一个重要的研究问题。
核心思路:本文的核心思路是,LLM不仅通过词嵌入之间的距离,还通过它们之间的相对方向来编码句法关系。具体来说,作者假设LLM的激活空间中存在一种“极坐标系”,其中距离表示句法关系的强度,而方向表示句法关系的类型和方向。通过同时考虑距离和方向,可以更全面地理解LLM如何表示句法结构。这种设计借鉴了极坐标系的特性,能够同时表达大小和方向,更适合描述句法关系。
技术框架:Polar Probe的整体框架包括以下几个主要步骤:1) 从LLM的中间层提取词嵌入;2) 计算词嵌入之间的距离和方向;3) 使用这些距离和方向信息训练一个探针(Polar Probe),以预测词之间的句法关系类型和方向。Polar Probe本质上是一个分类器,输入是词嵌入的距离和方向,输出是句法关系的类型和方向。训练完成后,通过评估Polar Probe在预测句法关系方面的准确性,来验证LLM是否以极坐标系的方式编码了句法信息。
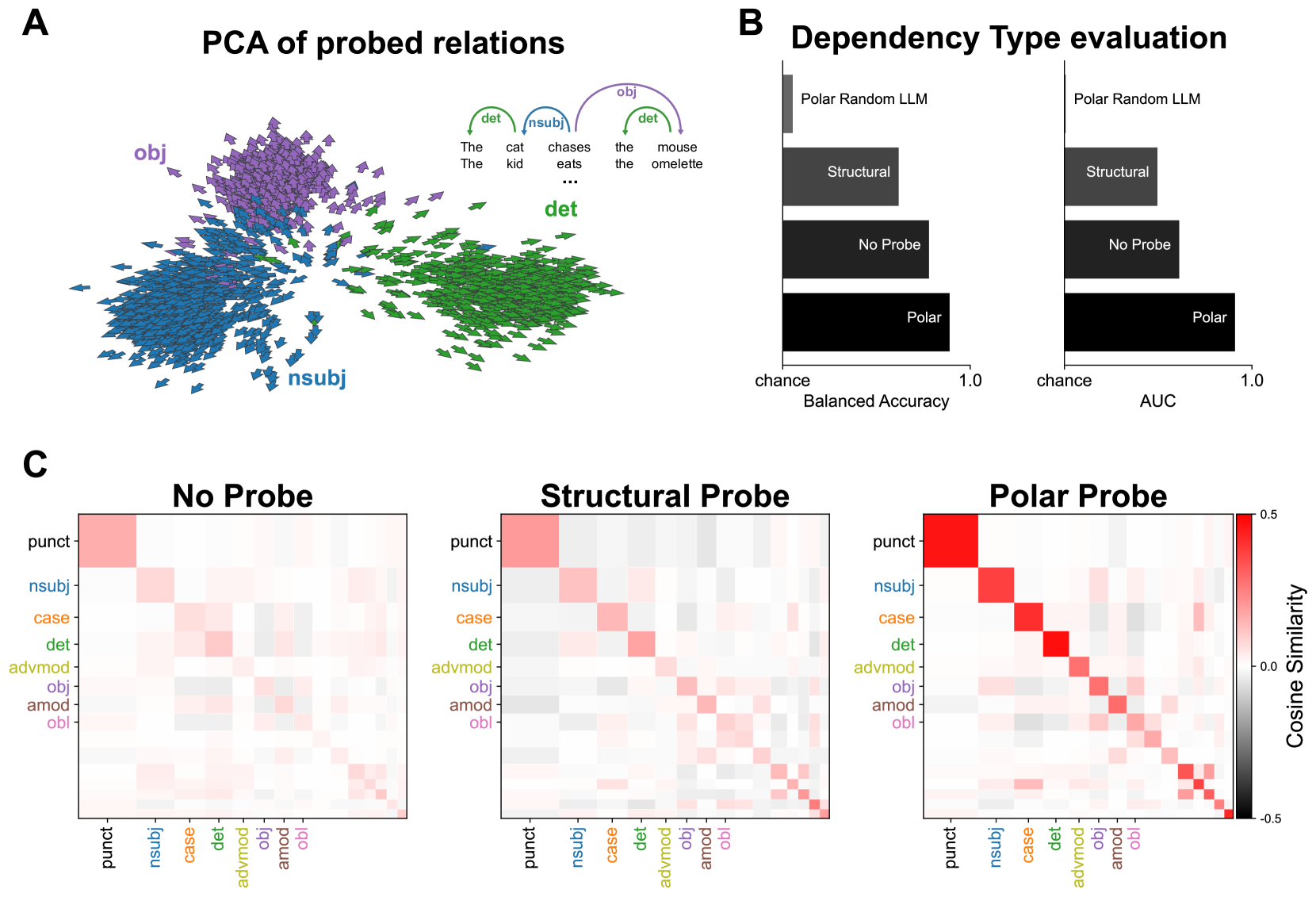
关键创新:该论文最重要的技术创新点在于提出了使用极坐标系来理解LLM中的句法表示。与以往只关注距离的结构探针不同,Polar Probe同时考虑了距离和方向,从而能够更完整地捕捉句法关系的各个方面。这种方法不仅提高了句法关系预测的准确性,还为理解LLM的内部工作机制提供了新的视角。
关键设计:Polar Probe的关键设计包括:1) 使用余弦相似度来衡量词嵌入之间的方向;2) 使用多层感知机(MLP)作为探针的模型结构,输入是距离和方向信息,输出是句法关系的类型和方向;3) 使用交叉熵损失函数来训练探针,目标是最小化预测的句法关系与实际句法关系之间的差异。此外,作者还设计了一个新的基准测试,用于评估Polar Probe在不同句法层级上的性能。
🖼️ 关键图片
📊 实验亮点
Polar Probe在句法关系类型和方向的恢复上,性能比结构探针提高了近两倍。实验还表明,这种极坐标系存在于许多LLM的中间层,并且在最新的前沿模型中变得越来越精确。此外,新的基准测试表明,相似的句法关系在句法树的嵌套层级中以相似的方式编码。
🎯 应用场景
该研究成果可应用于提升自然语言处理任务的性能,例如句法分析、机器翻译和文本理解。通过更深入地理解LLM如何编码句法信息,可以开发更有效的模型和算法,从而提高这些任务的准确性和效率。此外,该研究还有助于我们更好地理解LLM的内部工作机制,为开发更可解释、更可控的AI系统奠定基础。
📄 摘要(原文)
Originally formalized with symbolic representations, syntactic trees may also be effectively represented in the activations of large language models (LLMs). Indeed, a 'Structural Probe' can find a subspace of neural activations, where syntactically related words are relatively close to one-another. However, this syntactic code remains incomplete: the distance between the Structural Probe word embeddings can represent the existence but not the type and direction of syntactic relations. Here, we hypothesize that syntactic relations are, in fact, coded by the relative direction between nearby embeddings. To test this hypothesis, we introduce a 'Polar Probe' trained to read syntactic relations from both the distance and the direction between word embeddings. Our approach reveals three main findings. First, our Polar Probe successfully recovers the type and direction of syntactic relations, and substantially outperforms the Structural Probe by nearly two folds. Second, we confirm that this polar coordinate system exists in a low-dimensional subspace of the intermediate layers of many LLMs and becomes increasingly precise in the latest frontier models. Third, we demonstrate with a new benchmark that similar syntactic relations are coded similarly across the nested levels of syntactic trees. Overall, this work shows that LLMs spontaneously learn a geometry of neural activations that explicitly represents the main symbolic structures of linguistic theory.