CALICO: Conversational Agent Localization via Synthetic Data Generation
作者: Andy Rosenbaum, Pegah Kharazmi, Ershad Banijamali, Lu Zeng, Christopher DiPersio, Pan Wei, Gokmen Oz, Clement Chung, Karolina Owczarzak, Fabian Triefenbach, Wael Hamza
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-12-06
备注: Accepted to The 37th International Conference on Neural Information Processing Systems (NeurIPS 2023) December 10-16, 2023 - SyntheticData4ML Workshop, New Orleans, United States https://neurips.cc/virtual/2023/workshop/66540
💡 一句话要点
CALICO:通过合成数据生成实现对话Agent的跨语言本地化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨语言对话Agent 合成数据生成 本地化 大型语言模型 槽位填充
📋 核心要点
- 现有跨语言对话Agent训练数据不足,且直接翻译可能导致不符合目标语言习惯。
- CALICO通过生成合成数据,并进行迭代过滤,提升LLM在跨语言槽位填充任务中的本地化能力。
- 实验表明,CALICO在人工翻译和人工本地化数据集上均优于现有方法,尤其在更具挑战性的人工本地化数据集上。
📝 摘要(中文)
本文提出CALICO,一种用于微调大型语言模型(LLM)的方法,旨在将对话Agent的训练数据从一种语言本地化到另一种语言。对于槽位(命名实体),CALICO支持三种操作:原样复制、字面翻译和本地化,即生成在目标语言中更合适的槽位值,例如位于该语言使用国家的城市和机场名称。此外,我们设计了一种迭代过滤机制来丢弃嘈杂的生成样本,实验表明这可以提高下游对话Agent的性能。为了证明CALICO的有效性,我们构建并发布了一个新的、人工本地化的(HL)MultiATIS++旅行信息测试集,包含8种语言。与原始的人工翻译(HT)版本测试集相比,我们证明了我们新的HL版本更具挑战性。我们还表明,CALICO在HT案例(CALICO生成更准确的槽位翻译)和HL案例(CALICO生成更接近HL测试集的本地化槽位)中,均优于最先进的LINGUIST(依赖于脱离上下文的字面槽位翻译)。
🔬 方法详解
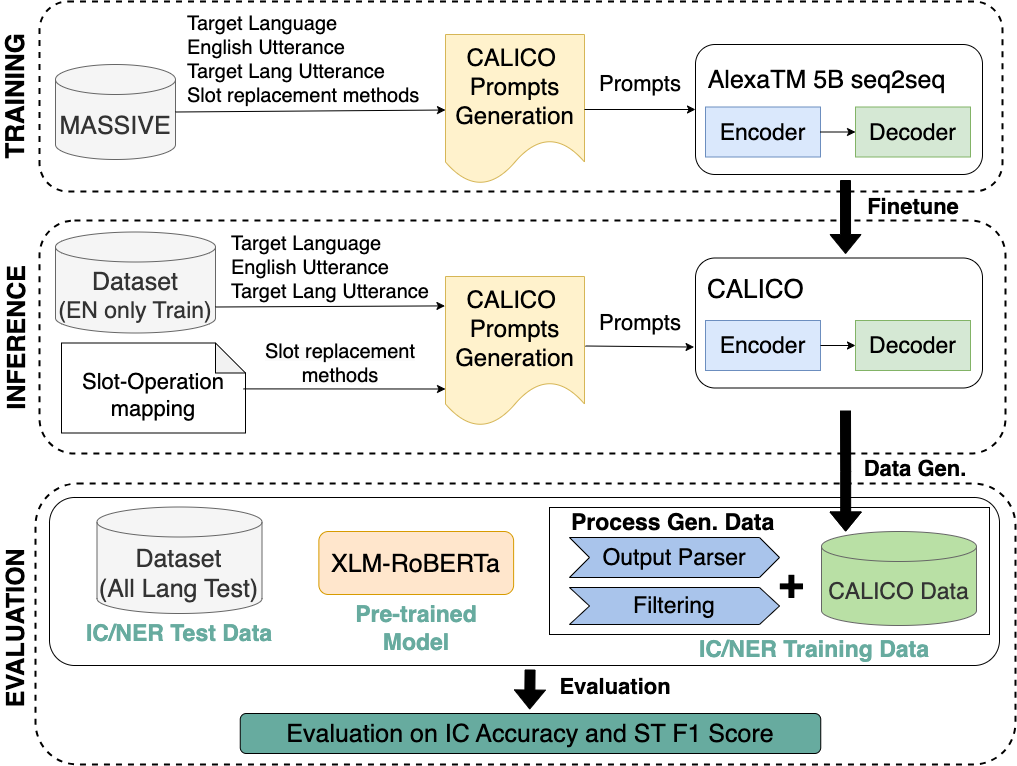
问题定义:现有的跨语言对话Agent训练方法通常依赖于人工翻译或简单的字面翻译,这两种方法都存在局限性。人工翻译成本高昂,难以扩展到多种语言;字面翻译则忽略了不同语言和文化之间的差异,导致槽位值不符合目标语言的习惯,例如,直接翻译地名可能不符合当地的表达方式。因此,需要一种能够自动生成符合目标语言习惯的槽位值的方法,以提高跨语言对话Agent的性能。
核心思路:CALICO的核心思路是利用大型语言模型(LLM)生成合成数据,并对生成的槽位值进行本地化。具体来说,CALICO首先使用LLM将源语言的槽位值翻译成目标语言,然后对翻译后的槽位值进行本地化,使其更符合目标语言的习惯。为了提高生成数据的质量,CALICO还设计了一种迭代过滤机制,用于去除嘈杂的生成样本。
技术框架:CALICO的整体框架包括以下几个主要模块:1) 数据生成模块:使用LLM将源语言的对话数据翻译成目标语言,并生成相应的槽位值。2) 本地化模块:对生成的槽位值进行本地化,使其更符合目标语言的习惯。3) 过滤模块:使用迭代过滤机制去除嘈杂的生成样本。4) 微调模块:使用过滤后的合成数据微调下游对话Agent。
关键创新:CALICO的关键创新在于以下几个方面:1) 提出了一个基于LLM的合成数据生成方法,用于跨语言对话Agent的训练。2) 设计了一种迭代过滤机制,用于去除嘈杂的生成样本,提高数据质量。3) 支持三种槽位操作:原样复制、字面翻译和本地化,可以灵活地处理不同类型的槽位。与现有方法相比,CALICO能够生成更符合目标语言习惯的槽位值,从而提高跨语言对话Agent的性能。
关键设计:CALICO的关键设计包括:1) 使用预训练的LLM作为数据生成器,利用其强大的生成能力。2) 设计了特定的prompt,引导LLM生成高质量的槽位值。3) 迭代过滤机制基于置信度评分,去除低质量的生成样本。4) 使用交叉熵损失函数微调下游对话Agent。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CALICO在MultiATIS++数据集上优于现有方法LINGUIST。在人工翻译(HT)数据集上,CALICO生成了更准确的槽位翻译;在更具挑战性的人工本地化(HL)数据集上,CALICO生成的本地化槽位更接近HL测试集。这证明了CALICO在跨语言槽位填充任务中的有效性。
🎯 应用场景
CALICO可应用于多语言对话系统、跨境电商客服、国际旅行助手等领域。通过自动生成本地化的训练数据,降低了跨语言对话Agent的开发成本,提升了用户体验。未来,该技术有望扩展到更多语言和领域,促进全球范围内的信息交流和文化融合。
📄 摘要(原文)
We present CALICO, a method to fine-tune Large Language Models (LLMs) to localize conversational agent training data from one language to another. For slots (named entities), CALICO supports three operations: verbatim copy, literal translation, and localization, i.e. generating slot values more appropriate in the target language, such as city and airport names located in countries where the language is spoken. Furthermore, we design an iterative filtering mechanism to discard noisy generated samples, which we show boosts the performance of the downstream conversational agent. To prove the effectiveness of CALICO, we build and release a new human-localized (HL) version of the MultiATIS++ travel information test set in 8 languages. Compared to the original human-translated (HT) version of the test set, we show that our new HL version is more challenging. We also show that CALICO out-performs state-of-the-art LINGUIST (which relies on literal slot translation out of context) both on the HT case, where CALICO generates more accurate slot translations, and on the HL case, where CALICO generates localized slots which are closer to the HL test set.