Evaluating and Aligning CodeLLMs on Human Preference
作者: Jian Yang, Jiaxi Yang, Ke Jin, Yibo Miao, Lei Zhang, Liqun Yang, Zeyu Cui, Yichang Zhang, Binyuan Hui, Junyang Lin
分类: cs.CL
发布日期: 2024-12-06
💡 一句话要点
提出CodeArena基准和SynCode-Instruct数据集,提升代码大模型对人类偏好的对齐。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码大语言模型 人类偏好对齐 代码生成 评估基准 合成指令微调 CodeArena SynCode-Instruct
📋 核心要点
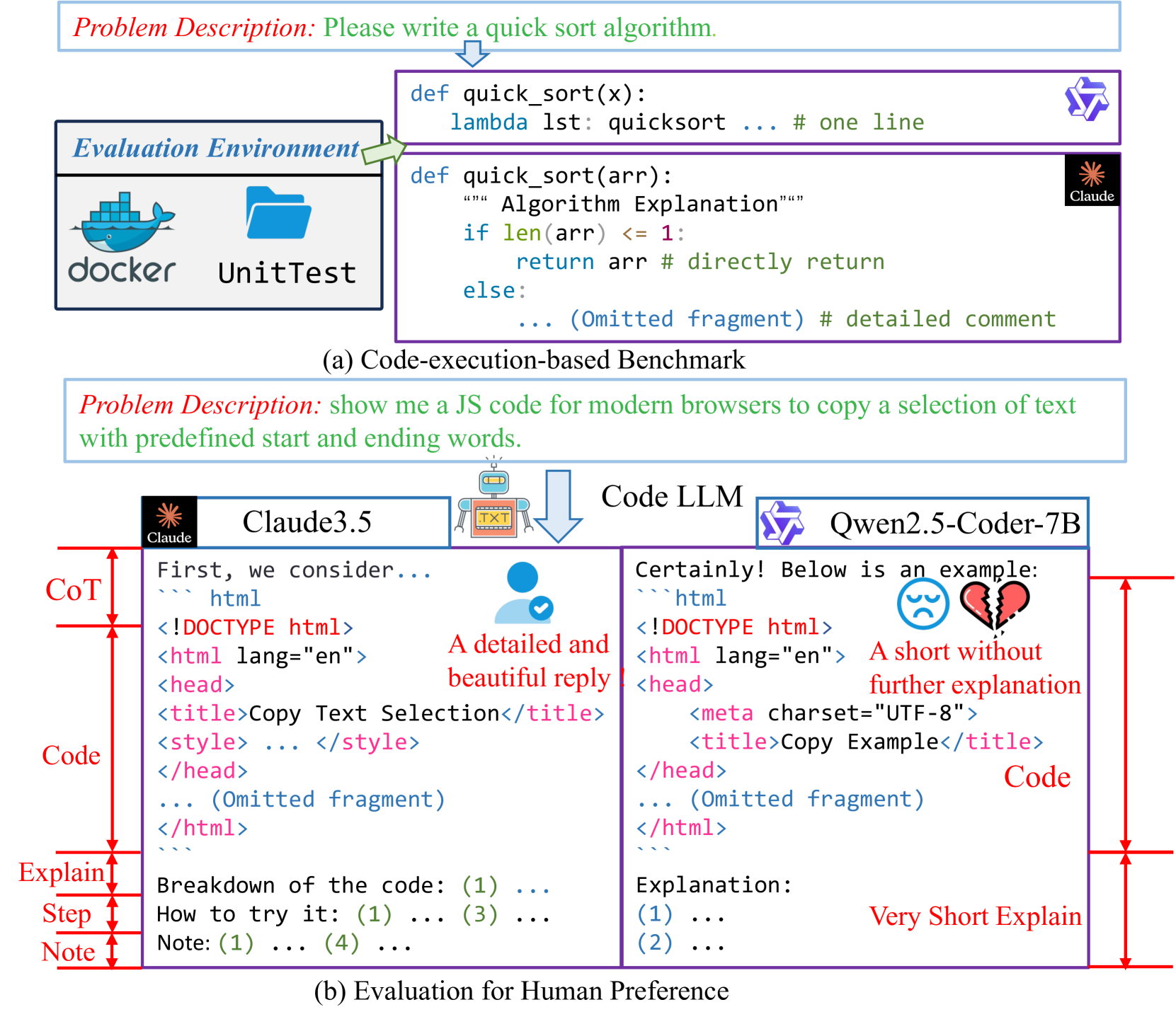
- 现有代码大模型评估侧重于代码正确性,忽略了与实际应用场景和人类偏好的对齐。
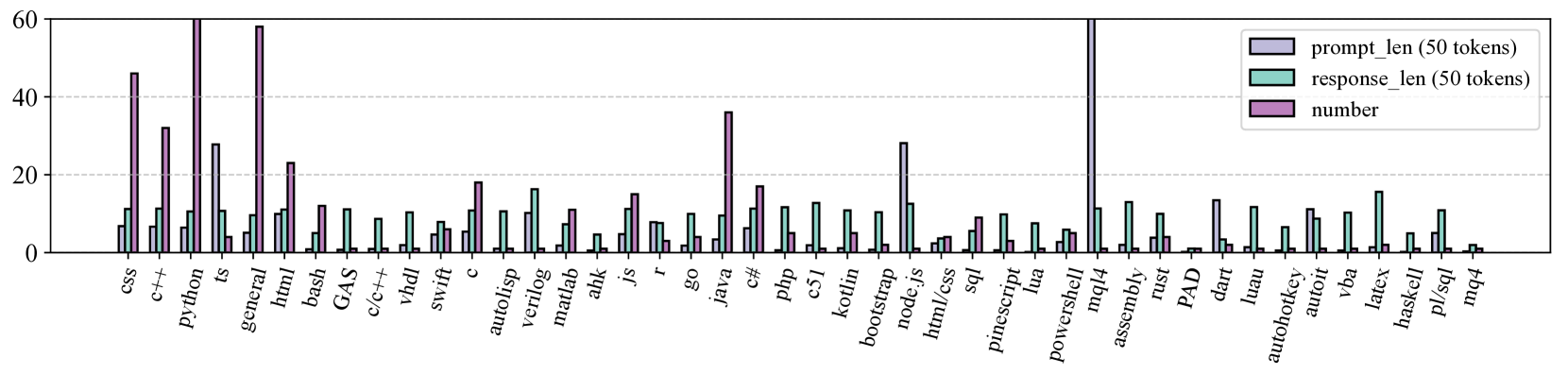
- 提出CodeArena基准,包含来自真实用户查询的高质量代码任务,模拟真实世界编码场景。
- 构建SynCode-Instruct数据集,通过大规模合成指令微调,提升模型性能,Qwen2.5-SynCoder表现优异。
📝 摘要(中文)
代码大语言模型(codeLLMs)在代码生成方面取得了显著进展。以往的代码相关基准主要依赖包含各种编程练习和对应测试用例,以此评估代码LLM的性能和能力。然而,当前的codeLLM专注于合成正确的代码片段,忽略了与人类偏好的对齐,即查询应从实际应用场景中采样,且模型生成的响应应满足人类偏好。为了弥合模型生成响应与人类偏好之间的差距,我们提出了一个严谨的人工管理的基准CodeArena,以模拟真实世界编码任务的复杂性和多样性,其中包含397个高质量样本,跨越40个类别和44种编程语言,这些样本均经过精心策划,源自用户查询。此外,我们提出了一个多样化的合成指令语料库SynCode-Instruct(近200亿tokens),通过扩展网站上的指令来验证大规模合成指令微调的有效性,其中完全在合成指令数据上训练的Qwen2.5-SynCoder可以达到开源代码LLM的顶尖性能。结果表明,基于执行的基准和CodeArena之间存在性能差异。我们对40多个LLM进行的CodeArena系统实验揭示了开源SOTA代码LLM(例如Qwen2.5-Coder)和专有LLM(例如OpenAI o1)之间存在显著的性能差距,突出了人类偏好对齐的重要性。
🔬 方法详解
问题定义:现有代码大语言模型的评估基准主要关注代码的正确性,而忽略了代码在实际应用场景中的可用性和与人类偏好的对齐。这意味着模型可能生成语法正确但难以理解、维护或不符合用户需求的程序。现有方法缺乏对模型在真实世界复杂编码任务中表现的有效评估。
核心思路:论文的核心思路是构建一个更贴近真实世界编码场景的评估基准,并利用大规模合成数据进行指令微调,从而提升代码大模型与人类偏好的对齐能力。通过CodeArena基准,可以更全面地评估模型在实际应用中的表现;通过SynCode-Instruct数据集,可以有效地提升模型的代码生成质量和对用户意图的理解。
技术框架:该研究的技术框架主要包含两个部分:一是CodeArena基准的构建,二是SynCode-Instruct数据集的生成和应用。CodeArena基准通过人工筛选真实用户查询,构建高质量的代码任务集合。SynCode-Instruct数据集通过扩展网站上的指令,生成大规模的合成指令数据,用于微调代码大模型。最终,通过在CodeArena基准上评估微调后的模型,验证其性能提升。
关键创新:该研究的关键创新在于提出了CodeArena基准,该基准更真实地反映了实际编码场景的需求,并考虑了人类偏好。此外,通过大规模合成指令微调,有效地提升了代码大模型与人类偏好的对齐能力。与现有方法相比,该研究更注重模型的实用性和用户体验。
关键设计:CodeArena基准包含397个高质量样本,跨越40个类别和44种编程语言,这些样本均经过精心策划,源自用户查询。SynCode-Instruct数据集包含近200亿tokens,通过扩展网站上的指令生成。Qwen2.5-SynCoder模型完全在SynCode-Instruct数据集上训练,并在CodeArena基准上进行评估。
🖼️ 关键图片

📊 实验亮点
实验结果表明,开源SOTA代码LLM(例如Qwen2.5-Coder)和专有LLM(例如OpenAI o1)在CodeArena基准上存在显著的性能差距,突出了人类偏好对齐的重要性。Qwen2.5-SynCoder模型完全在SynCode-Instruct数据集上训练,可以达到开源代码LLM的顶尖性能,验证了大规模合成指令微调的有效性。
🎯 应用场景
该研究成果可应用于代码大模型的评估和优化,提升代码生成工具的实用性和用户体验。通过CodeArena基准,可以更准确地评估模型在真实场景中的表现,指导模型训练和改进。SynCode-Instruct数据集可用于微调各种代码大模型,提升其代码生成质量和对用户意图的理解。未来,该研究可促进代码大模型在软件开发、自动化编程等领域的广泛应用。
📄 摘要(原文)
Code large language models (codeLLMs) have made significant strides in code generation. Most previous code-related benchmarks, which consist of various programming exercises along with the corresponding test cases, are used as a common measure to evaluate the performance and capabilities of code LLMs. However, the current code LLMs focus on synthesizing the correct code snippet, ignoring the alignment with human preferences, where the query should be sampled from the practical application scenarios and the model-generated responses should satisfy the human preference. To bridge the gap between the model-generated response and human preference, we present a rigorous human-curated benchmark CodeArena to emulate the complexity and diversity of real-world coding tasks, where 397 high-quality samples spanning 40 categories and 44 programming languages, carefully curated from user queries. Further, we propose a diverse synthetic instruction corpus SynCode-Instruct (nearly 20B tokens) by scaling instructions from the website to verify the effectiveness of the large-scale synthetic instruction fine-tuning, where Qwen2.5-SynCoder totally trained on synthetic instruction data can achieve top-tier performance of open-source code LLMs. The results find performance differences between execution-based benchmarks and CodeArena. Our systematic experiments of CodeArena on 40+ LLMs reveal a notable performance gap between open SOTA code LLMs (e.g. Qwen2.5-Coder) and proprietary LLMs (e.g., OpenAI o1), underscoring the importance of the human preference alignment.\footnote{\url{https://codearenaeval.github.io/ }}