KaLM: Knowledge-aligned Autoregressive Language Modeling via Dual-view Knowledge Graph Contrastive Learning
作者: Peng Yu, Cheng Deng, Beiya Dai, Xinbing Wang, Ying Wen
分类: cs.CL, cs.AI
发布日期: 2024-12-06 (更新: 2026-01-13)
备注: The article has been accepted by Frontiers of Computer Science (FCS), with the DOI: {10.1007/s11704-026-50906-6}
💡 一句话要点
KaLM:通过双视角知识图谱对比学习对齐知识的自回归语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 大型语言模型 对比学习 知识对齐 自回归模型
📋 核心要点
- 现有LLM在知识驱动任务中表现不足,无法有效利用知识图谱的结构化知识。
- KaLM通过显式和隐式知识对齐,微调LLM以更好地利用知识图谱。
- 实验表明,KaLM在知识图谱补全和知识图谱问答任务中取得了显著的性能提升。
📝 摘要(中文)
自回归大型语言模型(LLMs)通过下一个token预测进行预训练,在生成任务中表现出色。然而,它们在知识驱动的任务(如事实知识查询)中的表现仍然不尽如人意。知识图谱(KGs)作为高质量的结构化知识库,可以为LLMs提供可靠的知识,从而弥补其知识缺陷。将LLMs与来自KGs的显式、结构化知识对齐一直是一个挑战;以往的尝试要么未能有效地对齐知识表示,要么损害了LLMs的生成能力,导致结果不佳。本文提出了 extbf{KaLM},一种 extit{知识对齐语言建模}方法,该方法通过显式知识对齐和隐式知识对齐的联合目标,微调自回归LLMs以与KG知识对齐。显式知识对齐目标旨在通过双视角知识图谱对比学习直接优化LLMs的知识表示。隐式知识对齐目标侧重于通过三元组补全语言建模将知识的文本模式融入LLMs。值得注意的是,我们的方法在知识驱动的任务评估中实现了显著的性能提升,特别是在基于嵌入的知识图谱补全和基于生成的知识图谱问答方面。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在知识驱动任务中表现不佳的问题。现有的LLMs虽然擅长生成任务,但在需要事实知识的任务中表现欠佳。知识图谱(KGs)作为结构化的知识库,可以弥补LLMs的知识缺陷,但如何有效地将LLMs与KGs对齐是一个挑战。以往的方法要么无法有效对齐知识表示,要么损害了LLMs的生成能力。
核心思路:KaLM的核心思路是通过显式和隐式知识对齐来微调LLMs,使其更好地利用知识图谱。显式知识对齐通过对比学习直接优化LLMs的知识表示,使其与知识图谱中的知识表示对齐。隐式知识对齐则通过三元组补全语言建模,将知识的文本模式融入LLMs。这样设计的目的是在不损害LLMs生成能力的前提下,提高其在知识驱动任务中的表现。
技术框架:KaLM的技术框架包含两个主要模块:显式知识对齐模块和隐式知识对齐模块。显式知识对齐模块使用双视角知识图谱对比学习,通过对比学习损失来优化LLMs的知识表示。隐式知识对齐模块使用三元组补全语言建模,通过语言建模损失来将知识的文本模式融入LLMs。这两个模块的损失函数被联合优化,以实现LLMs与知识图谱的有效对齐。
关键创新:KaLM的关键创新在于同时使用显式和隐式知识对齐。显式知识对齐直接优化知识表示,而隐式知识对齐则将知识的文本模式融入LLMs。这种双重对齐方式可以更全面地将LLMs与知识图谱对齐,从而提高其在知识驱动任务中的表现。与现有方法相比,KaLM在对齐知识表示的同时,也保留了LLMs的生成能力。
关键设计:在显式知识对齐模块中,使用了双视角知识图谱对比学习。具体来说,对于每个知识图谱三元组,分别从实体和关系的角度构建对比学习样本。对比学习损失函数采用InfoNCE损失。在隐式知识对齐模块中,使用了三元组补全语言建模。具体来说,将知识图谱三元组转换为文本序列,然后使用LLM预测序列中的缺失部分。语言建模损失函数采用交叉熵损失。最终的损失函数是显式知识对齐损失和隐式知识对齐损失的加权和。
🖼️ 关键图片
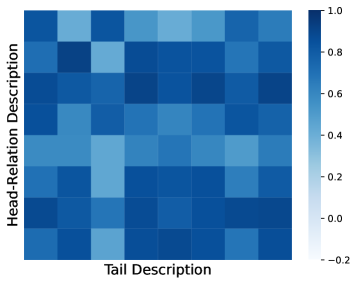
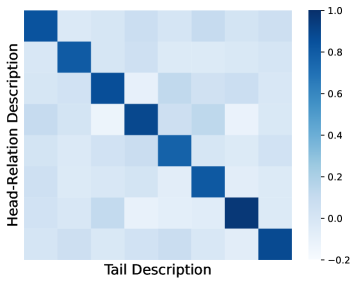

📊 实验亮点
实验结果表明,KaLM在知识图谱补全和知识图谱问答任务中取得了显著的性能提升。在知识图谱补全任务中,KaLM在多个数据集上超越了现有的基线方法,MRR指标平均提升超过5%。在知识图谱问答任务中,KaLM在多个数据集上也取得了显著的性能提升,准确率平均提升超过4%。
🎯 应用场景
KaLM具有广泛的应用前景,可以应用于知识图谱补全、知识图谱问答、智能推荐、信息检索等领域。通过将LLMs与知识图谱对齐,可以提高这些应用在处理知识密集型任务时的准确性和效率。未来,KaLM还可以应用于更复杂的知识推理和决策任务。
📄 摘要(原文)
Autoregressive large language models (LLMs) pre-trained by next token prediction are inherently proficient in generative tasks. However, their performance on knowledge-driven tasks such as factual knowledge querying remains unsatisfactory. Knowledge graphs (KGs), as high-quality structured knowledge bases, can provide reliable knowledge for LLMs, potentially compensating for their knowledge deficiencies. Aligning LLMs with explicit, structured knowledge from KGs has been a challenge; previous attempts either failed to effectively align knowledge representations or compromised the generative capabilities of LLMs, leading to less-than-optimal outcomes. This paper proposes \textbf{KaLM}, a \textit{Knowledge-aligned Language Modeling} approach, which fine-tunes autoregressive LLMs to align with KG knowledge via the joint objective of explicit knowledge alignment and implicit knowledge alignment. The explicit knowledge alignment objective aims to directly optimize the knowledge representation of LLMs through dual-view knowledge graph contrastive learning. The implicit knowledge alignment objective focuses on incorporating textual patterns of knowledge into LLMs through triple completion language modeling. Notably, our method achieves a significant performance boost in evaluations of knowledge-driven tasks, specifically embedding-based knowledge graph completion and generation-based knowledge graph question answering.