LLM-Align: Utilizing Large Language Models for Entity Alignment in Knowledge Graphs
作者: Xuan Chen, Tong Lu, Zhichun Wang
分类: cs.CL, cs.AI
发布日期: 2024-12-06
💡 一句话要点
提出LLM-Align,利用大语言模型解决知识图谱实体对齐问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 实体对齐 知识图谱 大语言模型 零样本学习 指令跟随
📋 核心要点
- 现有实体对齐方法缺乏对实体属性和关系的深层语义理解,限制了对齐的准确性。
- LLM-Align利用大语言模型的指令跟随和零样本学习能力,直接推断实体间的对齐关系。
- 实验结果表明,LLM-Align在三个实体对齐数据集上取得了优于现有方法的性能。
📝 摘要(中文)
实体对齐(EA)旨在识别和匹配不同知识图谱(KG)中对应的实体,在知识融合和集成中起着至关重要的作用。基于嵌入的实体对齐(EA)最近受到了广泛关注,涌现出许多创新方法。最初,这些方法侧重于基于关系三元组定义的知识图谱(KG)的结构特征来学习实体嵌入。随后的方法集成了实体的名称和属性作为补充信息,以改进用于EA的嵌入。然而,现有方法缺乏对实体属性和关系的深刻语义理解。在本文中,我们提出了一种基于大语言模型(LLM)的实体对齐方法LLM-Align,该方法探索了大语言模型的指令跟随和零样本能力来推断实体的对齐结果。LLM-Align使用启发式方法选择重要的实体属性和关系,然后将选择的实体三元组输入到LLM中以推断对齐结果。为了保证对齐结果的质量,我们设计了一种多轮投票机制,以减轻LLM中出现的幻觉和位置偏差问题。在三个EA数据集上的实验表明,与现有的EA方法相比,我们的方法实现了最先进的性能。
🔬 方法详解
问题定义:实体对齐旨在识别不同知识图谱中指向同一现实世界对象的实体。现有方法,特别是基于嵌入的方法,虽然取得了进展,但通常依赖于浅层的结构信息或简单的属性匹配,缺乏对实体属性和关系深层语义的理解,导致对齐精度受限。
核心思路:LLM-Align的核心思路是利用大语言模型(LLM)强大的语义理解和推理能力,直接从实体的属性和关系描述中推断实体之间的对齐关系。通过将实体信息转化为自然语言描述,并利用LLM的零样本学习能力,避免了传统方法中复杂的嵌入学习过程。
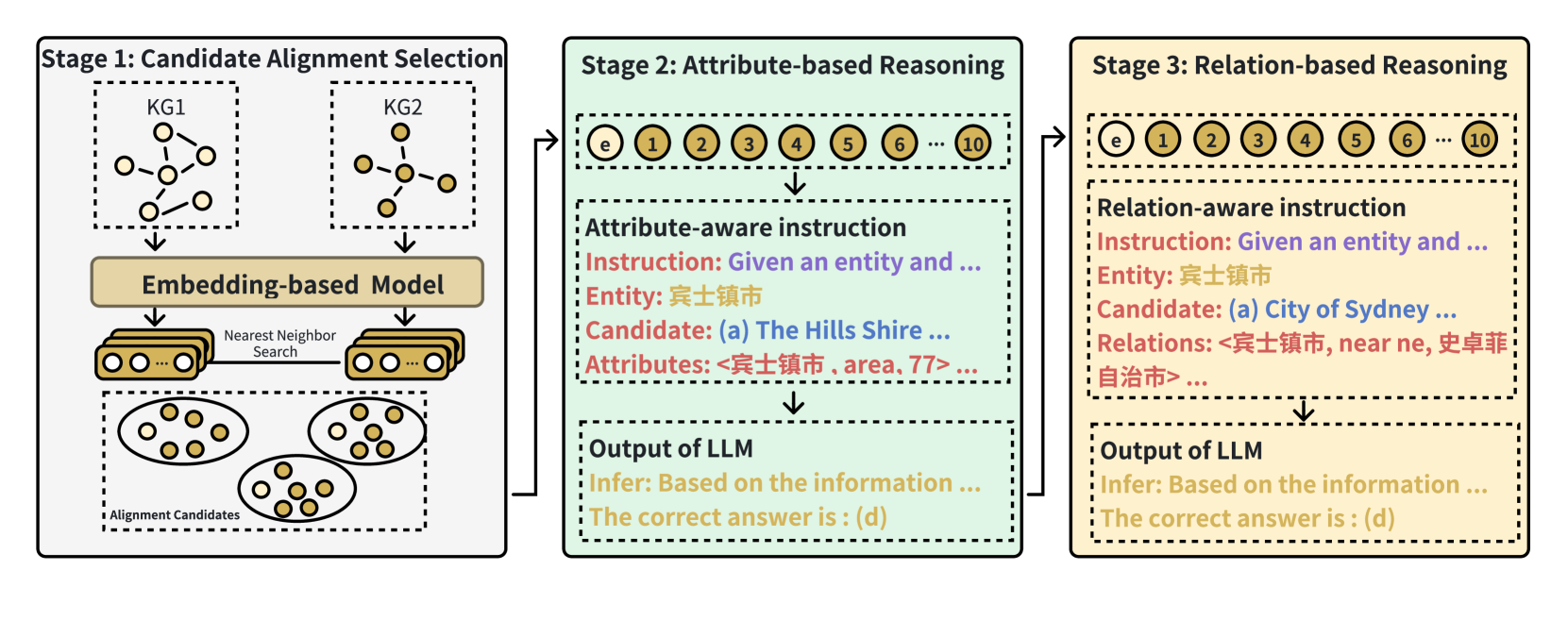
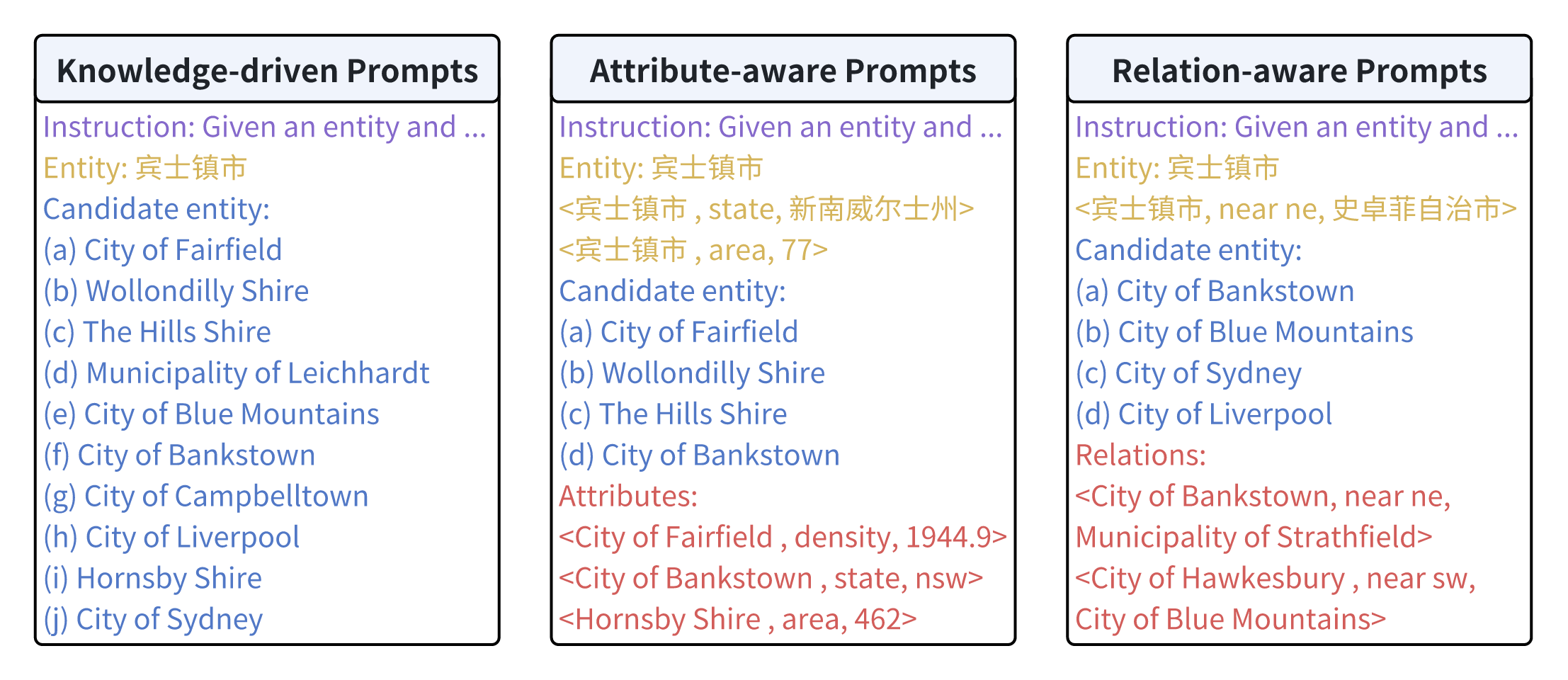
技术框架:LLM-Align的整体框架包括以下几个主要步骤:1) 属性和关系选择:使用启发式方法从知识图谱中选择对实体对齐至关重要的属性和关系。2) 输入构建:将选择的属性和关系转化为自然语言描述,构建LLM的输入提示。3) LLM推理:将构建的提示输入到LLM中,利用其指令跟随和零样本能力推断实体是否对齐。4) 多轮投票:为了减轻LLM的幻觉和位置偏差,采用多轮投票机制,综合多次推理结果,得到最终的对齐结果。
关键创新:LLM-Align的关键创新在于直接利用LLM进行实体对齐,避免了复杂的嵌入学习过程,并充分利用了LLM的语义理解和推理能力。此外,多轮投票机制有效缓解了LLM的固有问题,提高了对齐的可靠性。
关键设计:在属性和关系选择方面,论文采用启发式方法,例如选择具有较高区分度的属性。在LLM推理方面,使用了特定的提示工程技术,以引导LLM进行准确的对齐判断。多轮投票机制中,采用了多数投票策略,并可能根据LLM的置信度进行加权。
🖼️ 关键图片
📊 实验亮点
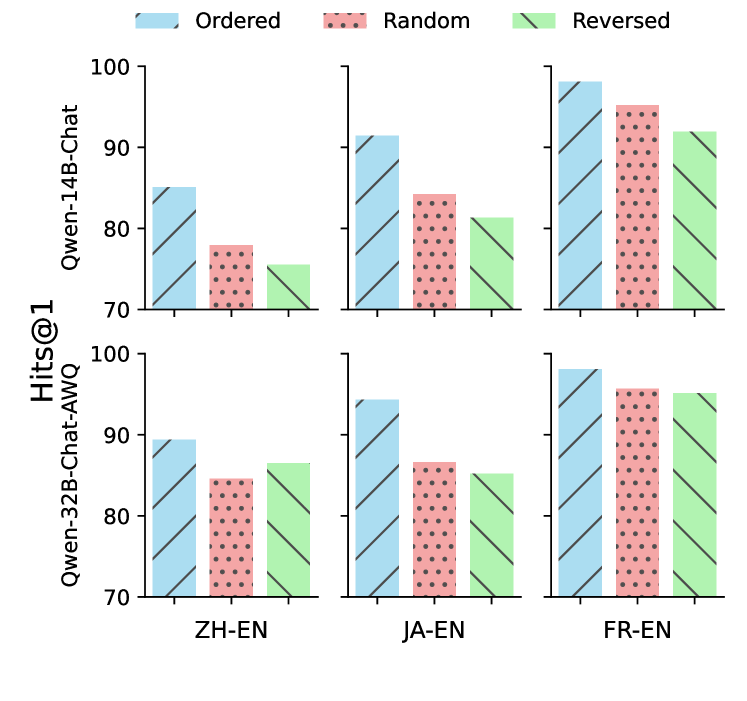
LLM-Align在三个实体对齐数据集上取得了显著的性能提升,超越了现有的基于嵌入的方法。具体而言,实验结果表明,LLM-Align在Hits@1指标上取得了明显的提升,证明了其在实体对齐任务上的有效性。实验结果验证了利用LLM进行实体对齐的可行性和优越性。
🎯 应用场景
LLM-Align在知识图谱融合、数据集成、语义搜索等领域具有广泛的应用前景。通过自动对齐不同来源的知识图谱,可以构建更全面、更准确的知识库,提升知识驱动型应用的效果。例如,在智能问答系统中,可以利用对齐后的知识图谱提供更准确的答案。
📄 摘要(原文)
Entity Alignment (EA) seeks to identify and match corresponding entities across different Knowledge Graphs (KGs), playing a crucial role in knowledge fusion and integration. Embedding-based entity alignment (EA) has recently gained considerable attention, resulting in the emergence of many innovative approaches. Initially, these approaches concentrated on learning entity embeddings based on the structural features of knowledge graphs (KGs) as defined by relation triples. Subsequent methods have integrated entities' names and attributes as supplementary information to improve the embeddings used for EA. However, existing methods lack a deep semantic understanding of entity attributes and relations. In this paper, we propose a Large Language Model (LLM) based Entity Alignment method, LLM-Align, which explores the instruction-following and zero-shot capabilities of Large Language Models to infer alignments of entities. LLM-Align uses heuristic methods to select important attributes and relations of entities, and then feeds the selected triples of entities to an LLM to infer the alignment results. To guarantee the quality of alignment results, we design a multi-round voting mechanism to mitigate the hallucination and positional bias issues that occur with LLMs. Experiments on three EA datasets, demonstrating that our approach achieves state-of-the-art performance compared to existing EA methods.