Arabic Stable LM: Adapting Stable LM 2 1.6B to Arabic
作者: Zaid Alyafeai, Michael Pieler, Hannah Teufel, Jonathan Tow, Marco Bellagente, Duy Phung, Nikhil Pinnaparaju, Reshinth Adithyan, Paulo Rocha, Maksym Zhuravinskyi, Carlos Riquelme
分类: cs.CL
发布日期: 2024-12-05
💡 一句话要点
提出Arabic Stable LM 1.6B,一个面向阿拉伯语的小型但强大的语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 阿拉伯语语言模型 小型语言模型 指令调整 合成数据 自然语言处理
📋 核心要点
- 现有阿拉伯语LLM通常参数量巨大,导致硬件需求高、推理延迟大,限制了其应用。
- Arabic Stable LM 1.6B旨在构建一个参数量小但性能强大的阿拉伯语LLM,降低部署成本。
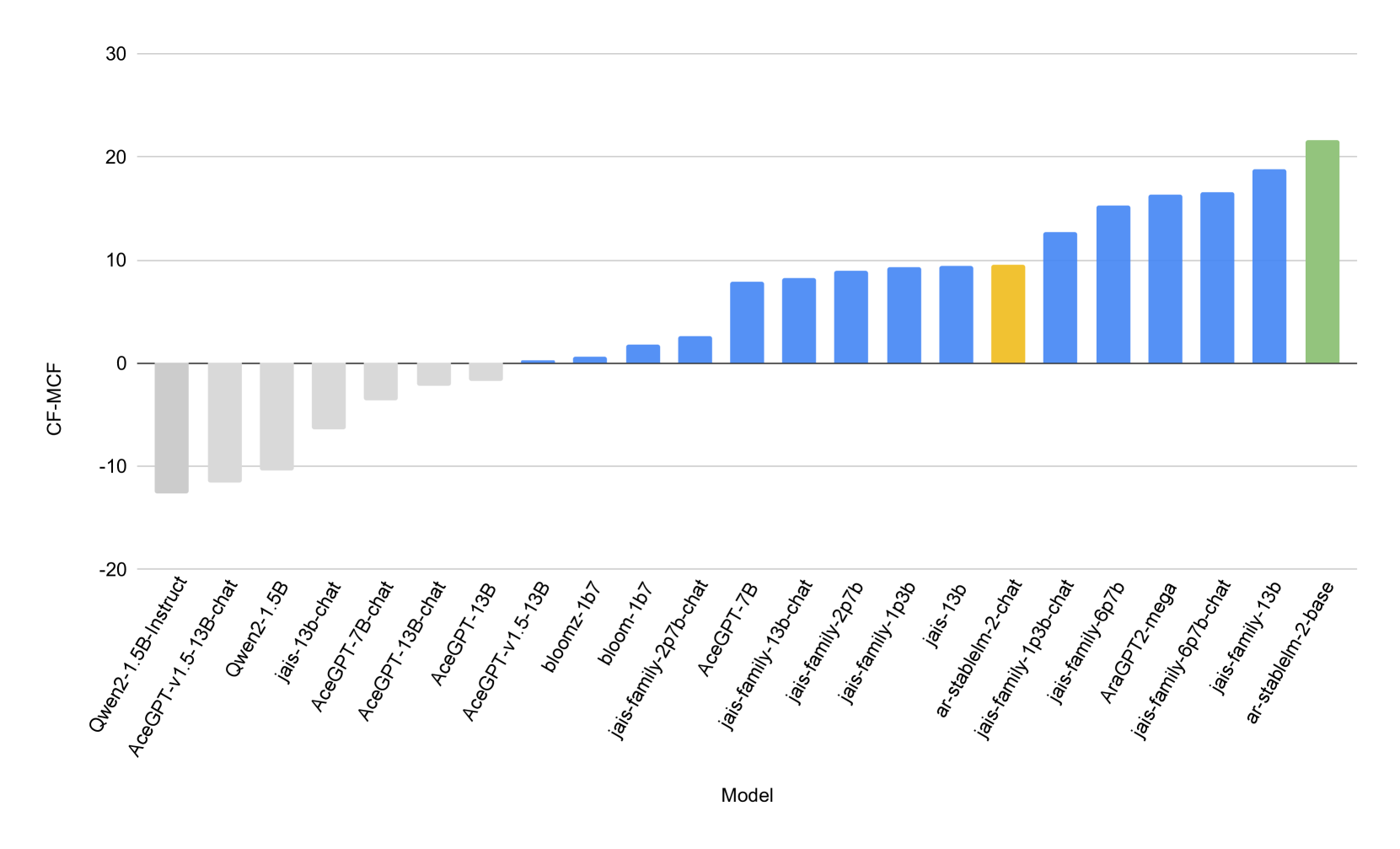
- 该模型在多个基准测试中超越了参数量更大的模型,证明了其有效性,并探索了合成数据的作用。
📝 摘要(中文)
大型语言模型(LLMs)在自然语言处理(NLP)的多个领域展现了令人印象深刻的结果,但主要集中在英语上。最近,更多的LLMs纳入了更大比例的多语种文本来表示低资源语言。在阿拉伯语NLP领域,过去两年中,一些以阿拉伯语为中心的LLMs在多个基准测试中表现出了显著的成果。然而,大多数阿拉伯语LLMs拥有超过70亿个参数,与较小的LLMs相比,这增加了它们的硬件要求和推理延迟。本文介绍了Arabic Stable LM 1.6B的基础版本和聊天版本,作为一个小型但功能强大的以阿拉伯语为中心的LLM。我们的Arabic Stable LM 1.6B聊天模型在多个基准测试中取得了令人印象深刻的成绩,击败了多个参数高达8倍的模型。此外,我们展示了通过使用大型合成对话数据集增强微调数据,混合合成指令调整数据的好处。
🔬 方法详解
问题定义:论文旨在解决阿拉伯语自然语言处理领域缺乏小型、高效的语言模型的问题。现有的大型阿拉伯语LLM虽然性能优越,但参数量巨大,对硬件要求高,推理速度慢,难以在资源受限的环境中部署和应用。
核心思路:论文的核心思路是利用Stable LM 2 1.6B作为基础模型,通过在阿拉伯语数据集上进行微调,构建一个参数量较小但性能强大的阿拉伯语LLM。此外,论文还探索了使用合成指令调整数据来提升模型的性能。
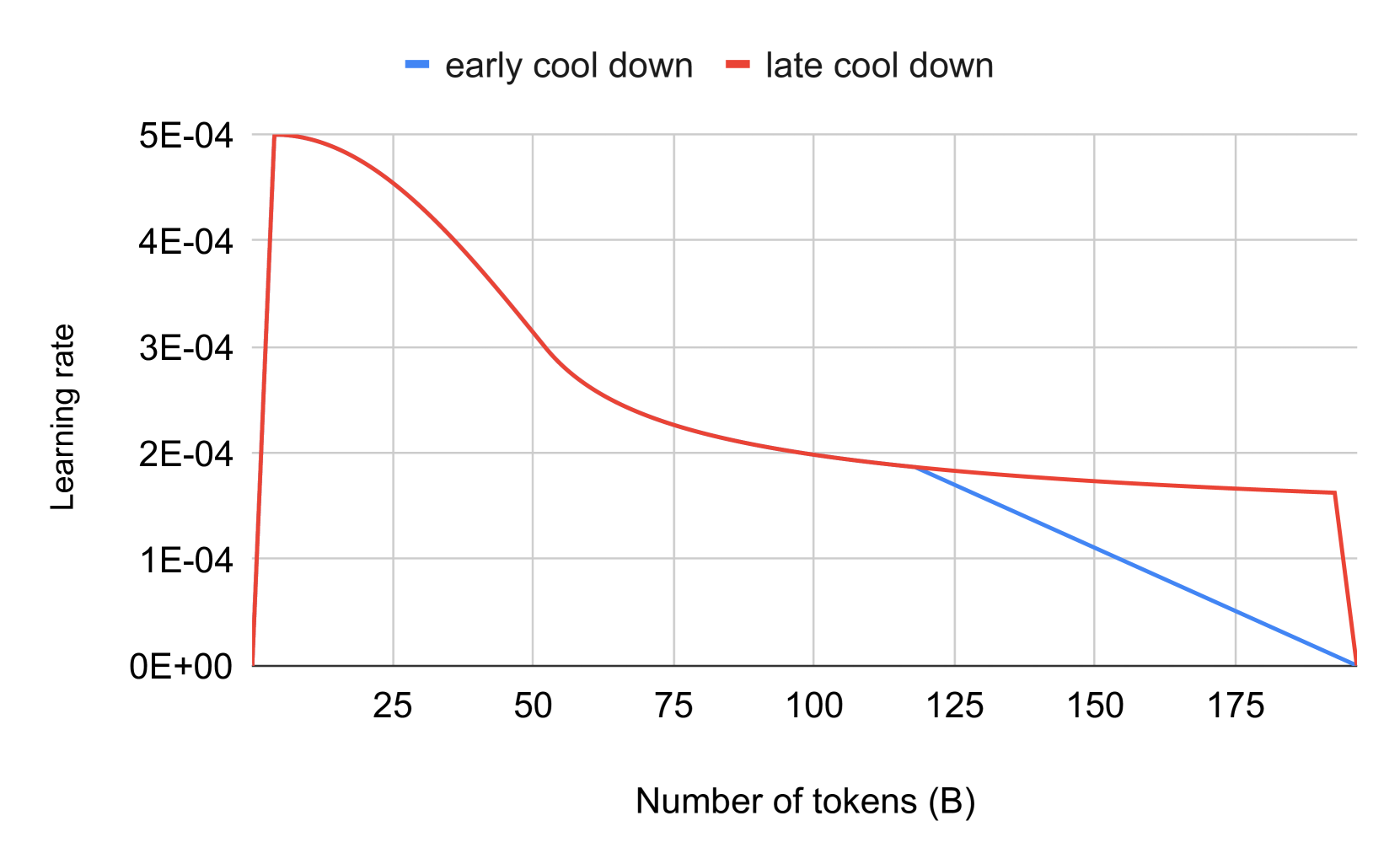
技术框架:Arabic Stable LM 1.6B的构建主要包括以下几个阶段:1) 基于Stable LM 2 1.6B;2) 在阿拉伯语语料库上进行持续预训练;3) 使用指令调整数据集进行微调,构建聊天版本。其中,指令调整数据集包括真实数据和合成数据。
关键创新:该论文的关键创新在于:1) 构建了一个参数量较小的阿拉伯语LLM,降低了部署成本和推理延迟;2) 探索了使用合成指令调整数据来提升模型性能的方法,并验证了其有效性。
关键设计:论文的关键设计包括:1) 选择Stable LM 2 1.6B作为基础模型,利用其在通用语言理解方面的能力;2) 构建高质量的阿拉伯语语料库,用于模型的持续预训练;3) 设计有效的指令调整数据集,包括真实数据和合成数据,用于模型的微调。具体参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
Arabic Stable LM 1.6B聊天模型在多个基准测试中取得了令人印象深刻的成绩,超越了参数量高达8倍的模型。这表明,通过有效的训练策略和数据选择,即使是参数量较小的模型也能达到甚至超过大型模型的性能。混合使用合成指令调整数据也显著提升了模型性能。
🎯 应用场景
Arabic Stable LM 1.6B可应用于阿拉伯语相关的各种NLP任务,如文本生成、机器翻译、问答系统、情感分析等。由于其参数量较小,更易于在移动设备、嵌入式系统等资源受限的环境中部署,具有广泛的应用前景。该模型可以促进阿拉伯语NLP技术的发展,并为阿拉伯语用户提供更好的服务。
📄 摘要(原文)
Large Language Models (LLMs) have shown impressive results in multiple domains of natural language processing (NLP) but are mainly focused on the English language. Recently, more LLMs have incorporated a larger proportion of multilingual text to represent low-resource languages. In Arabic NLP, several Arabic-centric LLMs have shown remarkable results on multiple benchmarks in the past two years. However, most Arabic LLMs have more than 7 billion parameters, which increases their hardware requirements and inference latency, when compared to smaller LLMs. This paper introduces Arabic Stable LM 1.6B in a base and chat version as a small but powerful Arabic-centric LLM. Our Arabic Stable LM 1.6B chat model achieves impressive results on several benchmarks beating multiple models with up to 8x the parameters. In addition, we show the benefit of mixing in synthetic instruction tuning data by augmenting our fine-tuning data with a large synthetic dialogue dataset.