AL-QASIDA: Analyzing LLM Quality and Accuracy Systematically in Dialectal Arabic
作者: Nathaniel R. Robinson, Shahd Abdelmoneim, Kelly Marchisio, Sebastian Ruder
分类: cs.CL
发布日期: 2024-12-05 (更新: 2025-01-03)
备注: Pre-print
💡 一句话要点
AL-QASIDA框架系统评估LLM在方言阿拉伯语中的质量和准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 阿拉伯语方言 大型语言模型 性能评估 AL-QASIDA框架 低资源语言
📋 核心要点
- 现有LLM对阿拉伯语方言支持不足,可能加剧社会不平等并限制应用。
- 提出AL-QASIDA框架,从保真度、理解、质量和双语现象四个维度评估LLM的DA建模能力。
- 实验结果表明LLM理解DA优于生成DA,后训练可能导致对DA的偏见,少量样本可缓解。
📝 摘要(中文)
方言阿拉伯语(DA)在语言技术,特别是大型语言模型(LLM)方面,服务严重不足。这种趋势可能会加剧现有的社会不平等,并限制LLM的应用。因此,我们提出了一个框架,全面评估LLM在DA建模方面的能力,包括四个维度:保真度、理解、质量和双语现象。我们评估了九个LLM在八种DA变体中的表现,并提供了实践建议。我们的评估表明,LLM理解DA的能力比生成DA的能力更强,这不是因为它们的DA流利度差,而是因为它们不愿生成DA。进一步的分析表明,当前的后训练可能会导致对DA的偏见,少量样本可以克服这一缺陷,并且输入文本中没有其他可测量的特征与LLM的DA性能有很好的相关性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理阿拉伯语方言(DA)时表现不佳的问题。现有方法缺乏对LLM在DA上的性能进行系统性评估的框架,导致无法准确衡量和改进LLM在DA上的应用效果。这不仅限制了LLM在DA地区的实际应用,还可能加剧社会不平等。
核心思路:论文的核心思路是构建一个全面的评估框架AL-QASIDA,该框架从四个关键维度(保真度、理解、质量和双语现象)来系统地分析LLM在DA上的表现。通过多维度的评估,可以更深入地了解LLM在DA处理上的优势和不足,从而为改进LLM在DA上的性能提供指导。
技术框架:AL-QASIDA框架包含以下主要模块:1) 数据收集与准备:收集多种DA变体的数据,并进行预处理。2) 评估指标设计:针对保真度、理解、质量和双语现象四个维度,设计相应的评估指标。3) 模型评估:使用收集的数据和设计的指标,对多个LLM在DA上的性能进行评估。4) 结果分析与建议:分析评估结果,找出LLM在DA上的不足,并提出改进建议。
关键创新:该论文的关键创新在于提出了一个专门针对LLM在DA上性能评估的综合框架AL-QASIDA。该框架不仅考虑了LLM的生成能力,还关注了其理解能力和对双语现象的处理能力。此外,该框架还提供了实用的建议,帮助研究人员和开发者改进LLM在DA上的性能。
关键设计:在评估指标设计方面,论文针对每个维度都设计了具体的指标。例如,对于保真度,可能使用BLEU或ROUGE等指标来衡量生成文本与参考文本的相似度;对于理解,可能使用问答或文本分类等任务来评估LLM对DA文本的理解能力;对于质量,可能使用人工评估或自动评估指标来衡量生成文本的流畅性和可读性;对于双语现象,可能评估LLM在DA和MSA(现代标准阿拉伯语)之间的转换能力。论文还分析了不同后训练方法对DA性能的影响,并探讨了少量样本学习在提升DA性能方面的潜力。
🖼️ 关键图片


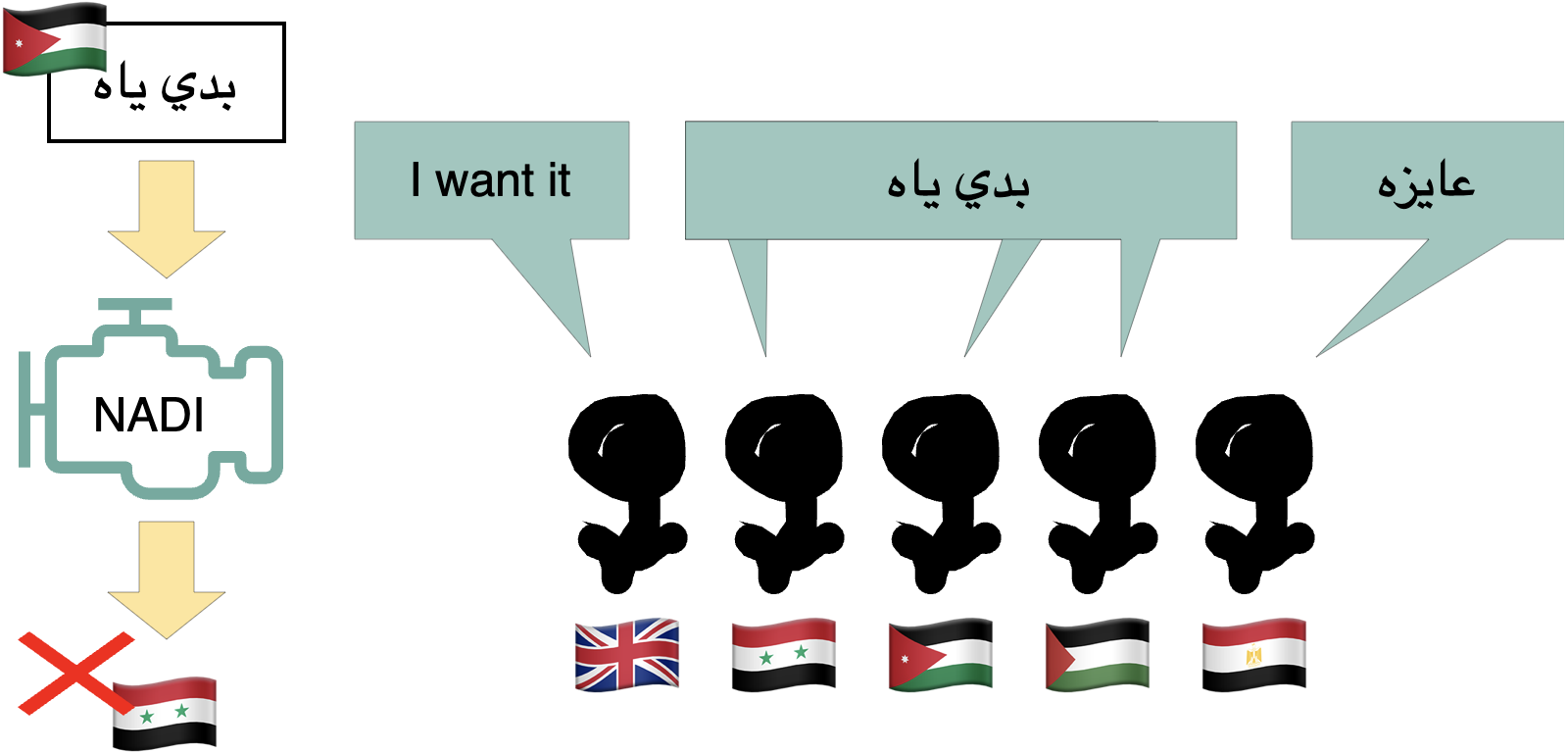
📊 实验亮点
实验结果表明,LLM在理解DA方面表现优于生成DA,这表明LLM的DA流利度并非瓶颈,而是生成意愿不足。进一步分析发现,当前的后训练方法可能导致对DA的偏见,而少量样本学习可以有效克服这一缺陷。此外,研究还发现输入文本的特征与LLM的DA性能之间没有显著的相关性。
🎯 应用场景
该研究成果可应用于开发更有效的阿拉伯语方言处理系统,例如智能客服、机器翻译、语音识别等。通过提升LLM在DA上的性能,可以促进DA地区的信息获取和交流,缩小数字鸿沟,并为DA地区的文化传承和发展做出贡献。此外,该框架也可推广到其他低资源语言的LLM评估中。
📄 摘要(原文)
Dialectal Arabic (DA) varieties are under-served by language technologies, particularly large language models (LLMs). This trend threatens to exacerbate existing social inequalities and limits LLM applications, yet the research community lacks operationalized performance measurements in DA. We present a framework that comprehensively assesses LLMs' DA modeling capabilities across four dimensions: fidelity, understanding, quality, and diglossia. We evaluate nine LLMs in eight DA varieties and provide practical recommendations. Our evaluation suggests that LLMs do not produce DA as well as they understand it, not because their DA fluency is poor, but because they are reluctant to generate DA. Further analysis suggests that current post-training can contribute to bias against DA, that few-shot examples can overcome this deficiency, and that otherwise no measurable features of input text correlate well with LLM DA performance.