If You Can't Use Them, Recycle Them: Optimizing Merging at Scale Mitigates Performance Tradeoffs
作者: Muhammad Khalifa, Yi-Chern Tan, Arash Ahmadian, Tom Hosking, Honglak Lee, Lu Wang, Ahmet Üstün, Tom Sherborne, Matthias Gallé
分类: cs.CL, cs.AI
发布日期: 2024-12-05 (更新: 2025-02-03)
备注: 13 pages, 9 figures
💡 一句话要点
通过优化大规模模型融合,缓解性能权衡问题,有效利用次优模型检查点。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型融合 大规模模型 持续学习 模型优化 帕累托最优 检查点回收 线性组合
📋 核心要点
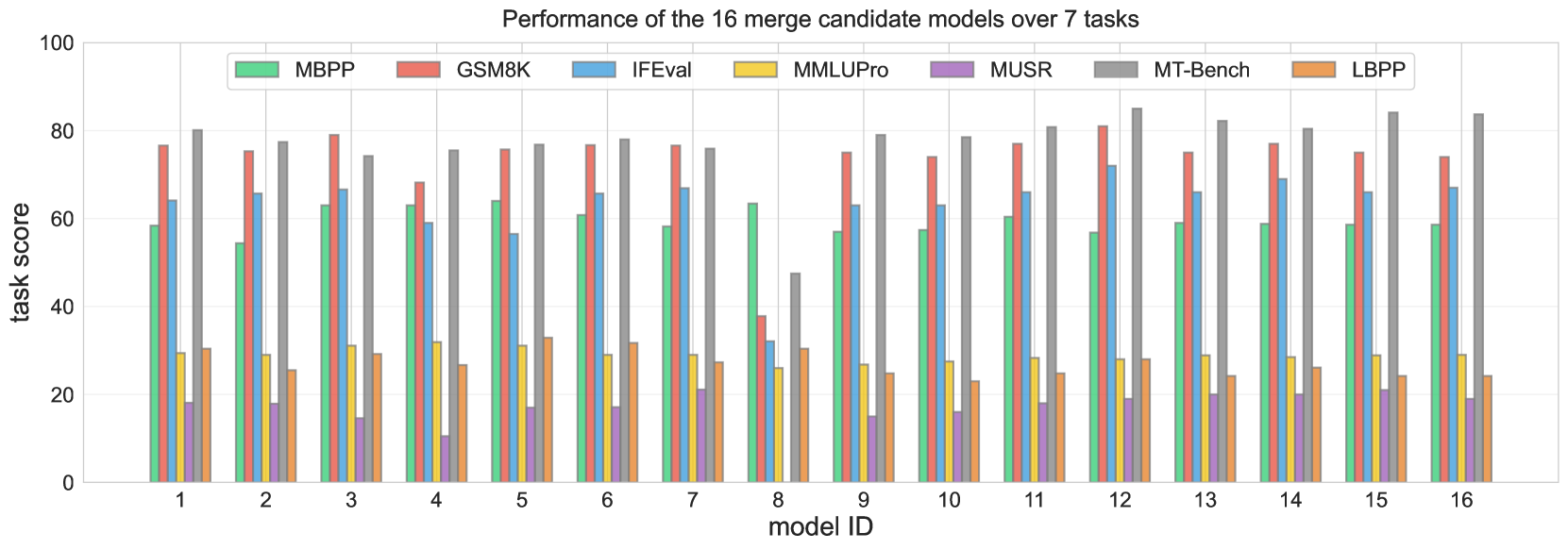
- 大型模型训练过程中会产生大量在不同任务上表现权衡的次优检查点,通常被丢弃。
- 提出一种优化算法,通过调整线性组合中各检查点的权重,将这些次优模型融合为帕累托最优模型。
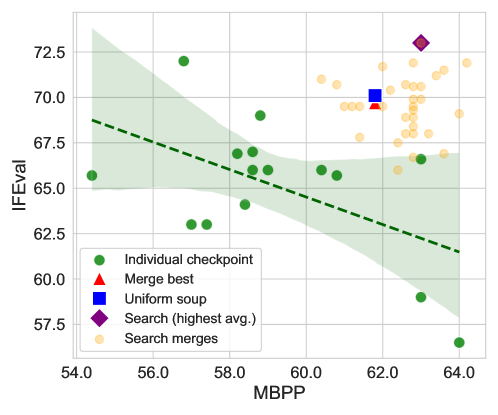
- 实验表明,该方法优于单个模型和传统融合方法,且良好融合倾向于包含几乎所有检查点。
📝 摘要(中文)
模型融合在结合专家模型方面展现了巨大的潜力,但当融合在多个任务上训练的“通用”模型时,融合的益处尚不明确。我们探索了在大约100B参数规模的模型中进行融合,通过回收在不同任务间表现出权衡的检查点。这些检查点通常在开发前沿模型的过程中产生,而次优的检查点通常会被丢弃。给定一组来自不同训练运行的模型检查点(例如,不同的阶段、目标、超参数和数据混合),它们自然地表现出不同语言能力之间的权衡(例如,指令遵循与代码生成),我们研究了融合是否可以将这些次优模型回收成一个帕累托最优的模型。我们的优化算法调整线性组合中每个检查点的权重,从而产生一个优于单个模型和基于融合的基线的最佳模型。进一步的分析表明,良好的融合往往包含几乎所有具有非零权重的检查点,这表明即使是看似糟糕的初始检查点也可以为良好的最终融合做出贡献。
🔬 方法详解
问题定义:论文旨在解决大规模模型训练过程中产生的次优模型检查点被浪费的问题。这些检查点在不同任务上表现出性能权衡,直接丢弃会损失潜在的有用信息。现有模型融合方法可能无法有效利用这些次优检查点,导致融合后的模型性能提升有限。
核心思路:论文的核心思路是将这些次优检查点视为构建更优模型的资源,通过优化融合权重,将它们组合成一个在多个任务上达到帕累托最优的模型。关键在于找到合适的权重分配方案,使得融合后的模型在各个任务上都能达到较好的性能,从而超越单个模型和传统融合方法。
技术框架:整体框架包含以下几个主要步骤:1) 获取一组来自不同训练运行的模型检查点,这些检查点在不同任务上表现出性能权衡;2) 定义一个线性组合模型,其中每个检查点的权重是可调参数;3) 使用优化算法(具体算法未知)调整每个检查点的权重,目标是最大化融合后模型在多个任务上的性能;4) 评估融合后模型的性能,并与单个模型和基于融合的基线进行比较。
关键创新:论文的关键创新在于提出了一种优化算法,能够有效地利用大规模模型训练过程中产生的次优检查点,将它们融合为一个帕累托最优的模型。与传统的模型融合方法不同,该方法能够自动学习每个检查点的最佳权重,从而充分利用每个检查点的优势,弥补其不足。
关键设计:论文的关键设计包括:1) 使用线性组合作为融合模型,简化了优化过程;2) 设计合适的优化目标函数,以平衡不同任务之间的性能权衡;3) 采用有效的优化算法(具体算法未知)来搜索最佳的权重分配方案。具体的参数设置、损失函数和网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够有效地将次优模型检查点融合为一个帕累托最优的模型,优于单个模型和基于融合的基线。进一步的分析表明,良好的融合往往包含几乎所有具有非零权重的检查点,这表明即使是看似糟糕的初始检查点也可以为良好的最终融合做出贡献。具体的性能提升数据未知。
🎯 应用场景
该研究成果可应用于大规模语言模型的持续学习和模型优化。通过回收和融合训练过程中的次优模型检查点,可以有效利用计算资源,提升模型性能,并降低模型训练成本。该方法还可用于构建在多个任务上表现均衡的通用模型,提高模型的泛化能力。
📄 摘要(原文)
Model merging has shown great promise at combining expert models, but the benefit of merging is unclear when merging "generalist" models trained on many tasks. We explore merging in the context of large (~100B) models, by recycling checkpoints that exhibit tradeoffs among different tasks. Such checkpoints are often created in the process of developing a frontier model, and the suboptimal ones are usually discarded. Given a pool of model checkpoints obtained from different training runs (e.g., different stages, objectives, hyperparameters, and data mixtures), which naturally show tradeoffs across different language capabilities (e.g., instruction following vs. code generation), we investigate whether merging can recycle such suboptimal models into a Pareto-optimal one. Our optimization algorithm tunes the weight of each checkpoint in a linear combination, resulting in such an optimal model that outperforms both individual models and merge-based baselines. Further analysis shows that good merges tend to include almost all checkpoints with non-zero weights, indicating that even seemingly bad initial checkpoints can contribute to good final merges.