Beyond the Binary: Capturing Diverse Preferences With Reward Regularization
作者: Vishakh Padmakumar, Chuanyang Jin, Hannah Rose Kirk, He He
分类: cs.CL, cs.AI
发布日期: 2024-12-05
💡 一句话要点
提出基于奖励正则化的方法,以捕捉大语言模型中多样化的用户偏好
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 偏好学习 奖励模型 用户偏好 奖励正则化
📋 核心要点
- 现有大语言模型偏好调整依赖二元判断,无法捕捉用户多样化偏好。
- 提出奖励正则化方法,通过合成偏好判断估计用户分歧,更好对齐用户偏好。
- 实验表明,该方法能有效提升模型预测与用户聚合偏好的一致性。
📝 摘要(中文)
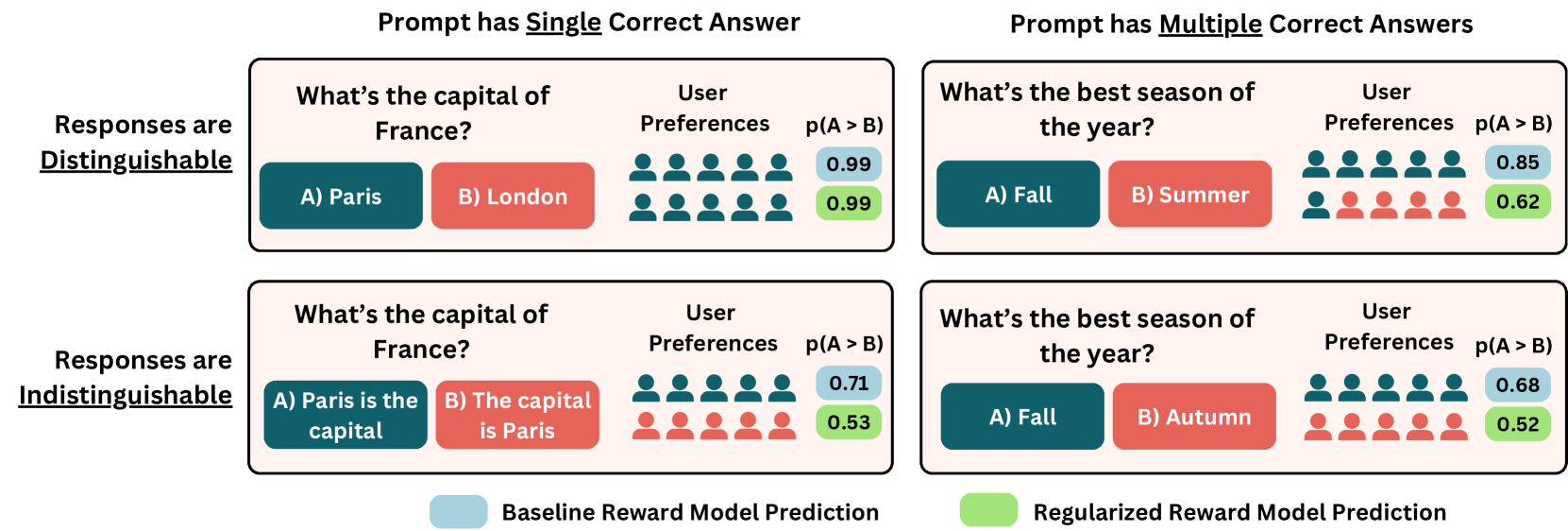
大型语言模型(LLMs)越来越多地通过面向公众的界面部署,与数百万具有不同偏好的用户进行交互。然而,LLMs的偏好调整主要依赖于使用二元判断训练的奖励模型,即标注者从模型输出的配对中选择更优选项。本文认为,这种对二元选择的依赖无法捕捉真实世界任务中目标用户的更广泛、聚合的偏好。我们提出了一个分类法,识别了用户在首选输出上存在分歧的两个主观维度——提示的多样性响应(Prompts allow for multiple correct answers)和响应的不可区分性(Candidate outputs are paraphrases of each other)。我们表明,奖励模型在这些情况下与用户偏好的相关性较弱。作为解决此问题的第一步,我们引入了一种简单而有效的方法,该方法通过合成偏好判断来扩充现有的二元偏好数据集,以估计潜在的用户分歧。在模型训练期间,通过边际项将这些作为一种正则化形式纳入,可以产生与聚合用户偏好更好地对齐的预测。
🔬 方法详解
问题定义:现有的大语言模型偏好学习方法主要依赖于二元偏好数据,即标注者从两个模型输出中选择一个更优的。这种方法忽略了用户偏好的多样性,尤其是在存在多个正确答案或者候选答案非常相似的情况下,无法准确反映用户的真实偏好。因此,如何在大语言模型偏好学习中更好地捕捉和利用用户多样化的偏好是一个关键问题。
核心思路:论文的核心思路是通过引入奖励正则化来解决二元偏好数据无法捕捉用户多样性偏好的问题。具体来说,该方法通过合成偏好判断来估计潜在的用户分歧,并将这些分歧信息作为正则化项加入到奖励模型的训练过程中。这样,模型在学习用户偏好的同时,也会考虑到用户之间的分歧,从而更好地对齐用户的聚合偏好。
技术框架:该方法主要包含以下几个步骤:1. 使用现有的二元偏好数据集。2. 通过合成偏好判断来扩充数据集,以估计潜在的用户分歧。3. 将用户分歧信息作为正则化项加入到奖励模型的训练过程中。4. 使用正则化后的奖励模型进行偏好学习。
关键创新:该方法最重要的创新点在于提出了使用合成偏好判断来估计用户分歧,并将其作为正则化项加入到奖励模型的训练过程中。这种方法能够有效地解决二元偏好数据无法捕捉用户多样性偏好的问题,从而更好地对齐用户的聚合偏好。
关键设计:关键的设计在于如何合成偏好判断以及如何将用户分歧信息作为正则化项加入到奖励模型中。具体来说,论文使用了一种基于边际项的正则化方法,该方法通过调整奖励模型的输出,使得模型在预测用户偏好的同时,也会考虑到用户之间的分歧。具体的损失函数设计未知。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了所提出的奖励正则化方法能够有效地提升模型预测与用户聚合偏好的一致性。具体的性能数据和对比基线未知,但结果表明该方法能够更好地捕捉用户多样化的偏好,从而提高模型的实际应用效果。
🎯 应用场景
该研究成果可应用于各种需要与用户交互的大语言模型应用场景,例如智能客服、内容生成、个性化推荐等。通过更好地理解和捕捉用户多样化的偏好,可以提升用户满意度,改善用户体验,并最终提高模型的实际应用价值。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed via public-facing interfaces to interact with millions of users, each with diverse preferences. Despite this, preference tuning of LLMs predominantly relies on reward models trained using binary judgments where annotators select the preferred choice out of pairs of model outputs. In this work, we argue that this reliance on binary choices does not capture the broader, aggregate preferences of the target user in real-world tasks. We propose a taxonomy that identifies two dimensions of subjectivity where different users disagree on the preferred output-namely, the Plurality of Responses to Prompts, where prompts allow for multiple correct answers, and the Indistinguishability of Responses, where candidate outputs are paraphrases of each other. We show that reward models correlate weakly with user preferences in these cases. As a first step to address this issue, we introduce a simple yet effective method that augments existing binary preference datasets with synthetic preference judgments to estimate potential user disagreement. Incorporating these via a margin term as a form of regularization during model training yields predictions that better align with the aggregate user preferences.