Acquired TASTE: Multimodal Stance Detection with Textual and Structural Embeddings
作者: Guy Barel, Oren Tsur, Dan Vilenchik
分类: cs.CL
发布日期: 2024-12-04 (更新: 2024-12-11)
备注: COLING 2025
💡 一句话要点
提出TASTE:融合文本和结构化嵌入的多模态立场检测方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 立场检测 多模态融合 Transformer 图嵌入 社交网络 门控残差网络 自然语言处理
📋 核心要点
- 现有立场检测模型主要依赖文本信息,忽略了对话上下文结构的重要性,导致性能受限。
- TASTE模型融合了Transformer文本嵌入和无监督结构嵌入,利用门控残差网络学习二者之间的复杂关系。
- 实验表明,TASTE在多个基准数据集上超越了现有最佳模型,验证了社交上下文信息的重要性。
📝 摘要(中文)
立场检测在诸多下游应用中扮演着关键角色,包括话语解析、追踪虚假新闻传播以及对科学事实的否认。虽然大多数立场分类模型依赖于问题中话语的文本表示,但先前的工作已经证明了对话上下文在立场检测中的重要性。本文介绍了一种用于立场检测的多模态架构TASTE,它和谐地融合了基于Transformer的内容嵌入和无监督的结构化嵌入。通过对预训练Transformer的微调,并通过门控残差网络(GRN)层与社交嵌入融合,我们的模型能够巧妙地捕捉内容和对话结构之间在确定立场时的复杂相互作用。TASTE在通用基准测试中取得了最先进的结果,显著优于一系列强大的基线模型。对比评估强调了社交基础的好处,强调了同时利用内容和结构以增强立场检测的关键性。
🔬 方法详解
问题定义:论文旨在解决立场检测问题,即判断一段文本对于特定目标(例如某个事件、人物或观点)所持有的态度(支持、反对或中立)。现有方法主要依赖文本内容,忽略了对话结构和社会关系,导致无法充分利用上下文信息,影响立场判断的准确性。
核心思路:论文的核心思路是将文本内容信息和社会结构信息进行融合,从而更全面地理解文本的立场。通过结合文本的语义信息和对话的上下文结构,模型可以更好地捕捉文本的真实意图和潜在的立场倾向。
技术框架:TASTE模型主要包含两个模块:文本内容嵌入模块和社会结构嵌入模块。文本内容嵌入模块使用预训练的Transformer模型(如BERT)对文本进行编码,提取文本的语义特征。社会结构嵌入模块则利用图嵌入技术,对对话的结构信息进行编码,提取节点(用户)之间的关系特征。然后,通过一个门控残差网络(GRN)将两个模块的输出进行融合,学习文本内容和社会结构之间的复杂关系。最后,使用融合后的特征进行立场分类。
关键创新:TASTE模型的关键创新在于将文本内容嵌入和社会结构嵌入进行有效融合。通过门控残差网络,模型可以自适应地学习不同模态信息的权重,从而更好地利用上下文信息。此外,使用无监督的图嵌入方法提取社会结构特征,避免了人工标注的成本。
关键设计:模型使用预训练的BERT模型作为文本编码器,并对其进行微调以适应立场检测任务。社会结构嵌入使用Node2Vec算法,将对话图中的节点映射到低维向量空间。门控残差网络包含多个残差块,每个残差块包含一个门控机制,用于控制不同模态信息的融合比例。损失函数使用交叉熵损失函数,优化目标是最小化预测立场和真实立场之间的差异。
🖼️ 关键图片


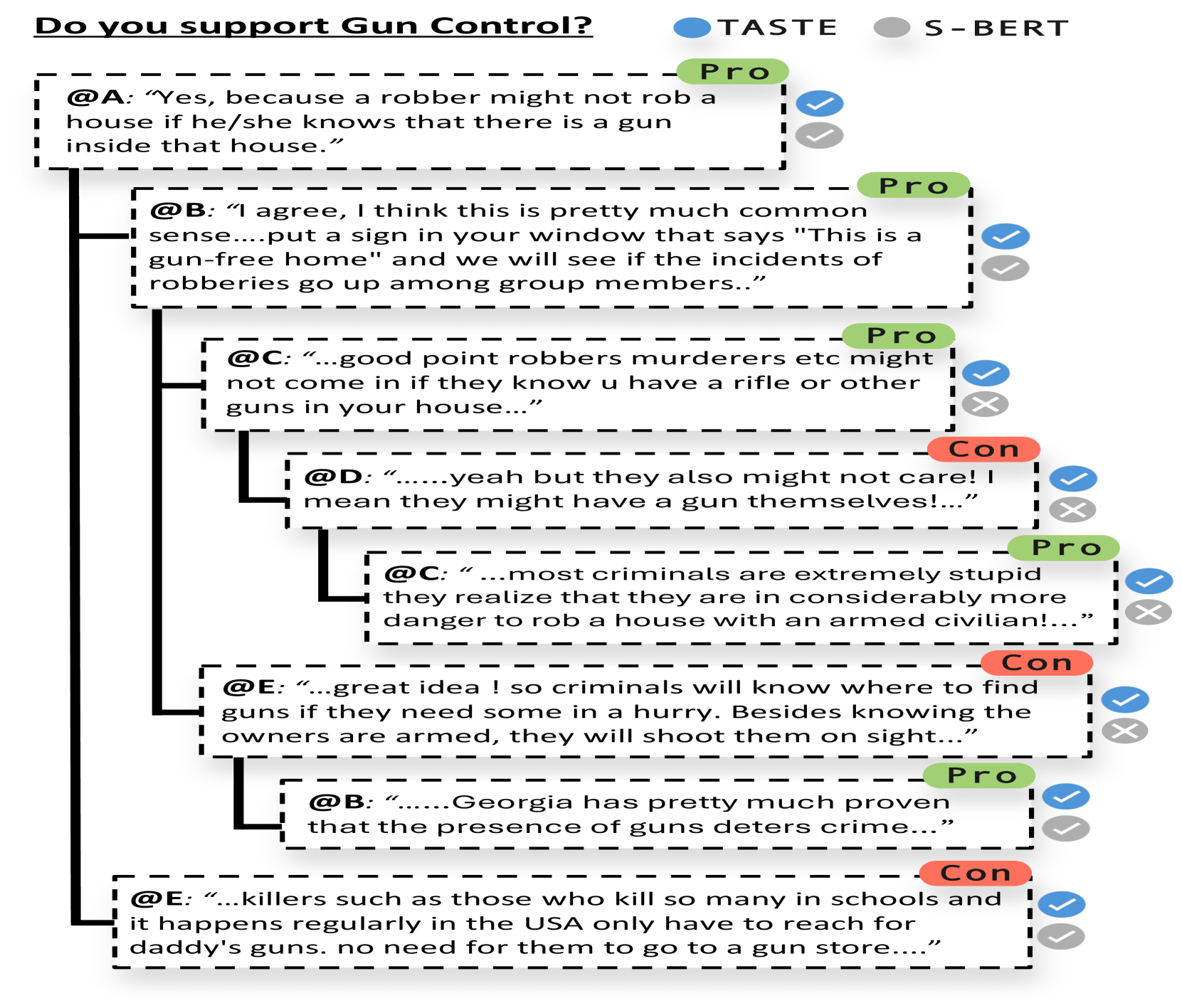
📊 实验亮点
TASTE模型在多个立场检测基准数据集上取得了state-of-the-art的结果,显著优于现有的基线模型。例如,在某数据集上,TASTE模型的F1值比最佳基线模型提高了5%以上,证明了该模型在融合文本和结构化信息方面的有效性。实验结果还表明,社交结构信息的加入可以显著提升立场检测的准确率。
🎯 应用场景
该研究成果可应用于舆情分析、虚假信息检测、网络安全等领域。通过准确识别用户对特定事件或观点的立场,可以帮助政府、企业和个人更好地了解社会舆论,及时发现和应对潜在的风险。此外,该技术还可以用于构建智能客服系统,根据用户的立场提供个性化的服务。
📄 摘要(原文)
Stance detection plays a pivotal role in enabling an extensive range of downstream applications, from discourse parsing to tracing the spread of fake news and the denial of scientific facts. While most stance classification models rely on textual representation of the utterance in question, prior work has demonstrated the importance of the conversational context in stance detection. In this work we introduce TASTE -- a multimodal architecture for stance detection that harmoniously fuses Transformer-based content embedding with unsupervised structural embedding. Through the fine-tuning of a pretrained transformer and the amalgamation with social embedding via a Gated Residual Network (GRN) layer, our model adeptly captures the complex interplay between content and conversational structure in determining stance. TASTE achieves state-of-the-art results on common benchmarks, significantly outperforming an array of strong baselines. Comparative evaluations underscore the benefits of social grounding -- emphasizing the criticality of concurrently harnessing both content and structure for enhanced stance detection.