Multimodal Sentiment Analysis Based on BERT and ResNet
作者: JiaLe Ren
分类: cs.CL
发布日期: 2024-12-04
💡 一句话要点
提出基于BERT和ResNet的多模态情感分析框架,提升文本图像融合效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感分析 BERT ResNet 注意力机制 特征融合
📋 核心要点
- 现有情感分析方法难以有效融合文本和图像特征,导致分析准确率受限。
- 提出结合BERT和ResNet的多模态情感分析框架,利用注意力机制实现特征融合。
- 在MAVA-single数据集上,该模型相比单模态模型,准确率提升至74.5%。
📝 摘要(中文)
随着互联网和社交媒体的快速发展,多模态数据(文本和图像)在情感分析任务中变得越来越重要。然而,现有方法难以有效地融合文本和图像特征,限制了分析的准确性。为了解决这个问题,本文提出了一种结合BERT和ResNet的多模态情感分析框架。BERT在自然语言处理中表现出强大的文本表示能力,而ResNet在计算机视觉领域具有出色的图像特征提取性能。首先,使用BERT提取文本特征向量,并使用ResNet提取图像特征表示。然后,探索了多种特征融合策略,最终选择基于注意力机制的融合模型,以充分利用文本和图像之间的互补信息。在公共数据集MAVA-single上的实验结果表明,与仅使用BERT或ResNet的单模态模型相比,所提出的多模态模型提高了准确率和F1分数,达到了74.5%的最佳准确率。这项研究不仅为多模态情感分析提供了新的思路和方法,而且证明了BERT和ResNet在跨领域融合中的应用潜力。未来,将探索更先进的特征融合技术和优化策略,以进一步提高多模态情感分析的准确性和泛化能力。
🔬 方法详解
问题定义:论文旨在解决多模态情感分析中,现有方法难以有效融合文本和图像特征,导致情感分析准确率不高的问题。现有方法通常采用简单的特征拼接或加权平均,无法充分利用文本和图像之间的互补信息,并且忽略了不同模态特征的重要性差异。
核心思路:论文的核心思路是利用BERT强大的文本表示能力和ResNet出色的图像特征提取能力,分别提取文本和图像的深层特征,然后通过注意力机制学习不同模态特征的权重,实现更有效的特征融合。这种设计旨在充分利用不同模态的互补信息,并突出重要特征,从而提高情感分析的准确性。
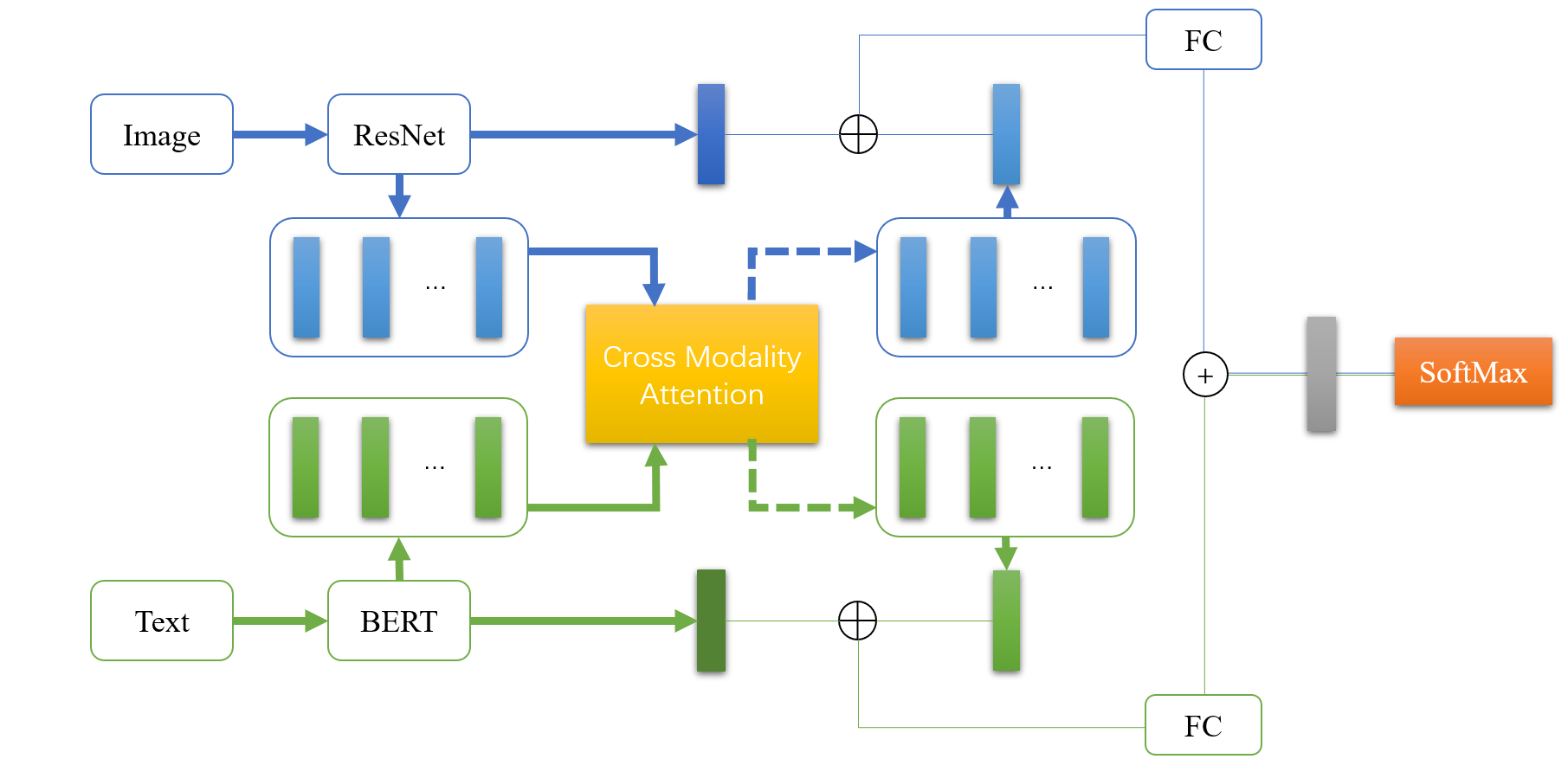
技术框架:整体框架包括三个主要模块:1) 文本特征提取模块:使用预训练的BERT模型提取文本的特征向量。2) 图像特征提取模块:使用预训练的ResNet模型提取图像的特征表示。3) 特征融合模块:采用注意力机制,根据文本和图像特征的关联性,动态调整不同模态特征的权重,并将融合后的特征输入到分类器中进行情感预测。
关键创新:最重要的技术创新点在于使用注意力机制进行多模态特征融合。与传统的特征拼接或加权平均方法相比,注意力机制能够自适应地学习不同模态特征的权重,从而更好地捕捉文本和图像之间的关联性,并突出对情感预测有重要作用的特征。
关键设计:BERT和ResNet均采用预训练模型,并在目标数据集上进行微调。注意力机制采用标准的自注意力机制,通过计算文本和图像特征之间的相似度,得到注意力权重。损失函数采用交叉熵损失函数,优化器采用Adam优化器。具体参数设置(如学习率、batch size等)未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的多模态模型在MAVA-single数据集上取得了74.5%的准确率,显著优于仅使用BERT或ResNet的单模态模型。这表明该模型能够有效地融合文本和图像特征,并充分利用不同模态的互补信息,从而提高情感分析的准确性。具体的提升幅度未知,需要参考原始论文。
🎯 应用场景
该研究成果可应用于社交媒体情感监控、舆情分析、智能客服等领域。通过融合文本和图像信息,可以更准确地识别用户的情感倾向,从而为企业提供更精准的营销策略、风险预警和客户服务。未来,该技术还可扩展到其他多模态数据分析任务,如视频情感分析、语音情感分析等。
📄 摘要(原文)
With the rapid development of the Internet and social media, multi-modal data (text and image) is increasingly important in sentiment analysis tasks. However, the existing methods are difficult to effectively fuse text and image features, which limits the accuracy of analysis. To solve this problem, a multimodal sentiment analysis framework combining BERT and ResNet was proposed. BERT has shown strong text representation ability in natural language processing, and ResNet has excellent image feature extraction performance in the field of computer vision. Firstly, BERT is used to extract the text feature vector, and ResNet is used to extract the image feature representation. Then, a variety of feature fusion strategies are explored, and finally the fusion model based on attention mechanism is selected to make full use of the complementary information between text and image. Experimental results on the public dataset MAVA-single show that compared with the single-modal models that only use BERT or ResNet, the proposed multi-modal model improves the accuracy and F1 score, reaching the best accuracy of 74.5%. This study not only provides new ideas and methods for multimodal sentiment analysis, but also demonstrates the application potential of BERT and ResNet in cross-domain fusion. In the future, more advanced feature fusion techniques and optimization strategies will be explored to further improve the accuracy and generalization ability of multimodal sentiment analysis.