Alignment at Pre-training! Towards Native Alignment for Arabic LLMs
作者: Juhao Liang, Zhenyang Cai, Jianqing Zhu, Huang Huang, Kewei Zong, Bang An, Mosen Alharthi, Juncai He, Lian Zhang, Haizhou Li, Benyou Wang, Jinchao Xu
分类: cs.CL
发布日期: 2024-12-04
备注: Accepted to NeurIPS 2024 main conference. see https://github.com/FreedomIntelligence/AceGPT-v2
💡 一句话要点
面向阿拉伯语LLM的原生对齐:在预训练阶段实现模型对齐
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 阿拉伯语LLM 原生对齐 预训练 模型对齐
📋 核心要点
- 现有LLM对齐方法主要集中在指令微调或强化学习等后处理阶段,忽略了预训练阶段的潜在影响。
- 该论文提出“原生对齐”概念,即在预训练阶段融入对齐数据,从源头上避免模型产生未对齐内容。
- 通过在阿拉伯语LLM上的实验,验证了原生对齐的有效性,并开源了性能优异的阿拉伯语LLM模型。
📝 摘要(中文)
大型语言模型(LLM)的对齐对于开发有效且安全的语言模型至关重要。传统方法侧重于在指令微调或强化学习阶段对齐模型,本文称之为“后对齐”。我们认为,在预训练阶段进行对齐(我们称之为“原生对齐”)值得研究。原生对齐旨在从一开始就防止未对齐的内容,而不是依赖于事后处理。这种方法利用广泛对齐的预训练数据来增强预训练模型的有效性和可用性。我们的研究专门探讨了原生对齐在阿拉伯语LLM中的应用。我们进行了全面的实验和消融研究,以评估原生对齐对模型性能和对齐稳定性的影响。此外,我们发布了开源阿拉伯语LLM,这些模型在各种基准测试中表现出最先进的性能,为阿拉伯语LLM社区提供了显著的益处。
🔬 方法详解
问题定义:现有的大型语言模型对齐方法主要集中在指令微调和强化学习等后处理阶段,这种“后对齐”的方式可能无法从根本上解决模型产生有害或不准确内容的问题。预训练数据中可能包含未对齐的内容,导致模型在后续阶段难以完全纠正。因此,如何从预训练阶段就保证模型的对齐性是一个重要的研究问题。
核心思路:该论文的核心思路是在预训练阶段就融入对齐的数据,从而实现“原生对齐”。通过使用大量对齐的预训练数据,模型可以在早期阶段学习到正确的价值观和行为准则,从而减少后续对齐的难度和成本。这种方法旨在从源头上防止模型产生未对齐的内容,提高模型的安全性和可靠性。
技术框架:该论文的技术框架主要包括以下几个阶段:1) 收集和构建大规模的阿拉伯语对齐预训练数据集;2) 使用该数据集对阿拉伯语LLM进行预训练;3) 对预训练后的模型进行评估,包括模型性能和对齐稳定性;4) 进行消融研究,分析不同对齐数据对模型性能的影响。整体流程是从数据准备到模型训练,再到模型评估和分析。
关键创新:该论文最重要的技术创新点在于提出了“原生对齐”的概念,并将其应用于阿拉伯语LLM的预训练中。与传统的“后对齐”方法相比,“原生对齐”能够更有效地提高模型的安全性和可靠性。此外,该论文还开源了性能优异的阿拉伯语LLM模型,为阿拉伯语LLM社区做出了贡献。
关键设计:论文的关键设计在于如何构建大规模的阿拉伯语对齐预训练数据集。具体的技术细节包括:数据来源的选择、数据清洗和过滤、数据标注和对齐等。此外,论文还可能涉及到一些超参数的调整,例如学习率、batch size、训练轮数等。损失函数方面,可能采用标准的语言模型损失函数,例如交叉熵损失函数。
🖼️ 关键图片


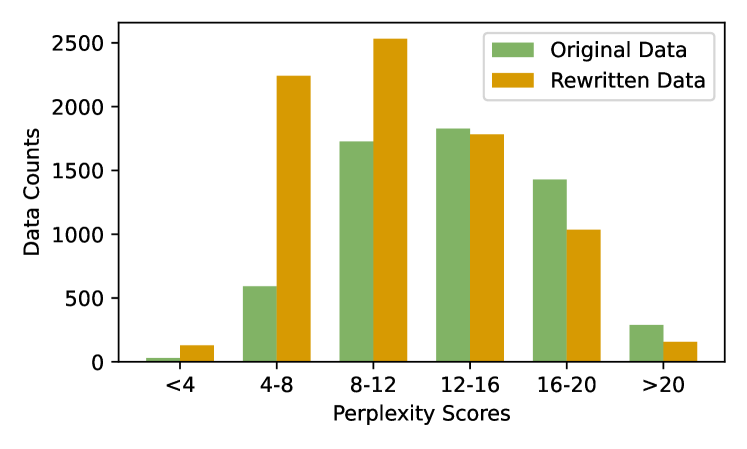
📊 实验亮点
该论文通过实验验证了原生对齐在阿拉伯语LLM上的有效性。实验结果表明,使用原生对齐方法训练的阿拉伯语LLM在各种基准测试中表现出最先进的性能,并且具有更好的对齐稳定性。此外,该论文还开源了性能优异的阿拉伯语LLM模型,为阿拉伯语LLM社区提供了重要的资源。
🎯 应用场景
该研究成果可广泛应用于各种需要阿拉伯语LLM的场景,例如智能客服、机器翻译、内容生成、教育辅助等。通过提高阿拉伯语LLM的安全性和可靠性,可以更好地服务于阿拉伯语用户,并促进阿拉伯语自然语言处理技术的发展。未来,该研究可以扩展到其他语言和领域,为构建更加安全可靠的LLM做出贡献。
📄 摘要(原文)
The alignment of large language models (LLMs) is critical for developing effective and safe language models. Traditional approaches focus on aligning models during the instruction tuning or reinforcement learning stages, referred to in this paper as
post alignment'. We argue that alignment during the pre-training phase, which we termnative alignment', warrants investigation. Native alignment aims to prevent unaligned content from the beginning, rather than relying on post-hoc processing. This approach leverages extensively aligned pre-training data to enhance the effectiveness and usability of pre-trained models. Our study specifically explores the application of native alignment in the context of Arabic LLMs. We conduct comprehensive experiments and ablation studies to evaluate the impact of native alignment on model performance and alignment stability. Additionally, we release open-source Arabic LLMs that demonstrate state-of-the-art performance on various benchmarks, providing significant benefits to the Arabic LLM community.