Linq-Embed-Mistral Technical Report
作者: Chanyeol Choi, Junseong Kim, Seolhwa Lee, Jihoon Kwon, Sangmo Gu, Yejin Kim, Minkyung Cho, Jy-yong Sohn
分类: cs.CL
发布日期: 2024-12-04
备注: 15 pages
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
Linq-Embed-Mistral通过数据精炼显著提升文本检索性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本检索 数据精炼 负样本挖掘 大型语言模型 MTEB基准
📋 核心要点
- 现有文本检索模型在处理复杂和多样化数据时面临挑战,尤其是在数据质量和泛化能力方面。
- Linq-Embed-Mistral通过精细的数据制作、过滤和负样本挖掘,以及同构任务排序和混合任务微调来提升模型性能。
- 实验结果表明,Linq-Embed-Mistral在MTEB基准测试中取得了显著的性能提升,尤其是在检索任务中排名第一。
📝 摘要(中文)
本报告探讨了使用高级数据精炼技术来增强文本检索性能。我们基于E5-mistral和Mistral-7B-v0.1模型,开发了Linq-Embed-Mistral,专注于复杂的数据制作、数据过滤和负样本挖掘方法,这些方法高度针对每个任务,应用于现有的基准数据集和通过大型语言模型(LLM)生成的高度定制的合成数据集。截至2024年5月29日,Linq-Embed-Mistral在MTEB基准测试中表现出色,在56个数据集上的平均得分为68.2,并在MTEB排行榜上所有检索任务模型中排名第一,性能得分为60.2。这一性能突显了其在提高搜索精度和可靠性方面的卓越能力。我们的贡献包括:先进的数据精炼方法,显著提高了模型在基准和合成数据集上的性能;用于同构任务排序和混合任务微调的技术,以增强模型的泛化性和稳定性;以及使用4位精度和轻量级检索评估集的精简评估流程,可在不牺牲准确性的前提下加速验证。
🔬 方法详解
问题定义:现有文本检索模型在处理大规模、高质量数据集时面临挑战。尤其是在负样本的选择、数据噪声的过滤以及模型泛化能力方面存在瓶颈。现有方法通常依赖于通用数据集或简单的负采样策略,难以充分挖掘数据的内在结构和任务相关性。
核心思路:Linq-Embed-Mistral的核心思路是通过精细的数据精炼过程,包括数据制作、数据过滤和负样本挖掘,来提升模型的文本检索能力。通过针对特定任务定制数据集,并采用同构任务排序和混合任务微调策略,增强模型的泛化性和稳定性。
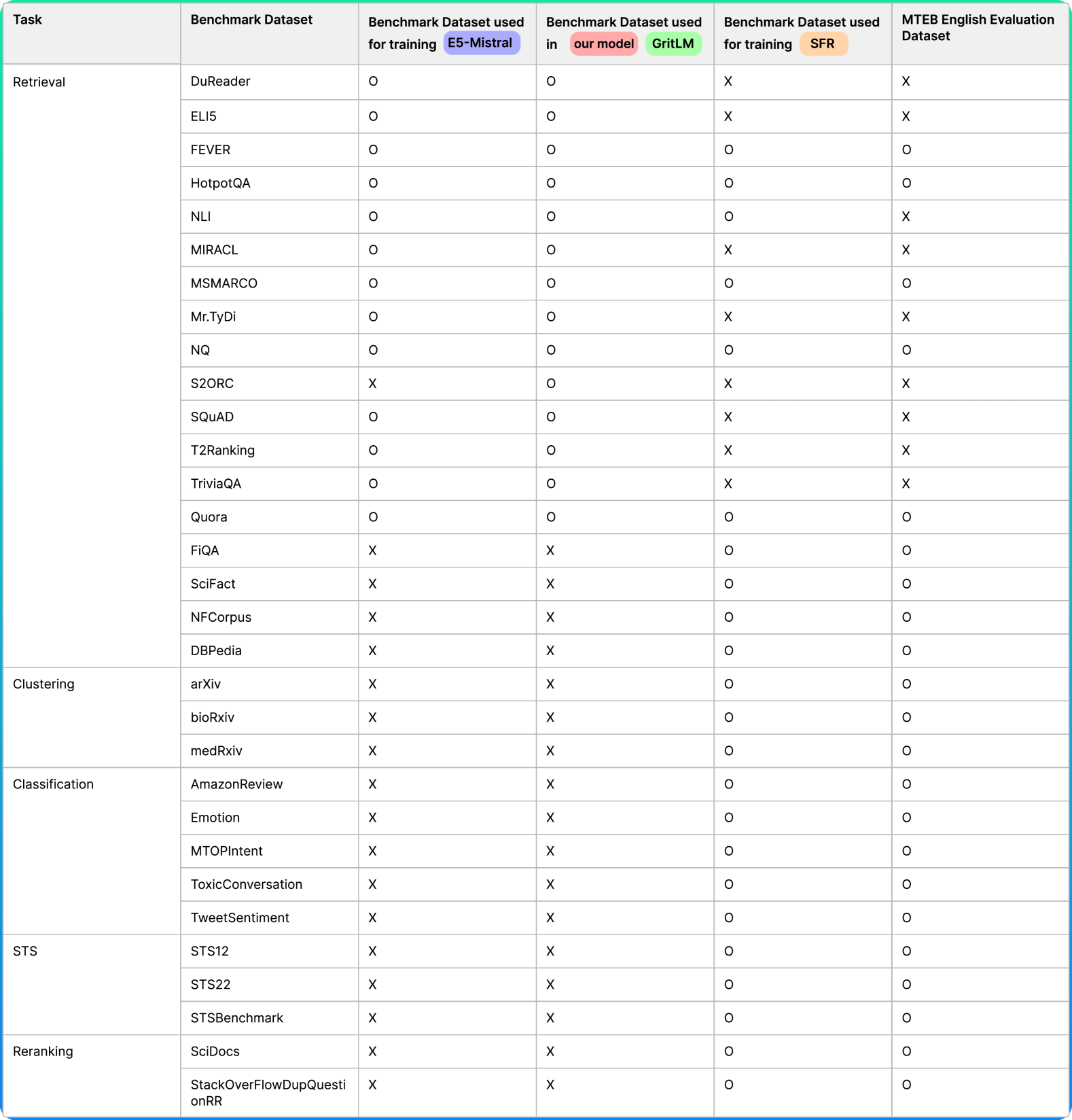
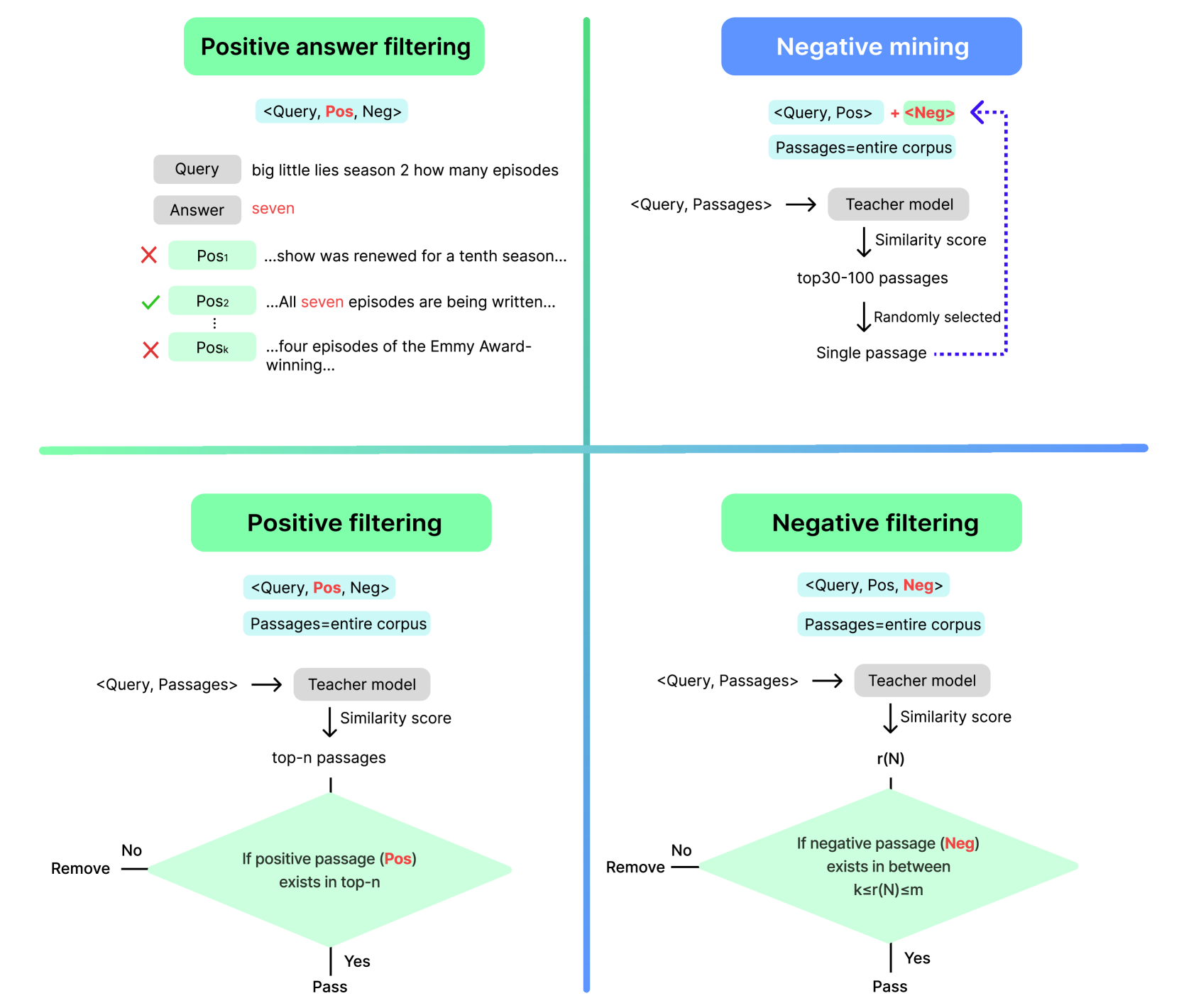
技术框架:Linq-Embed-Mistral的整体框架包括以下几个主要阶段:1) 数据制作:利用大型语言模型(LLM)生成高度定制的合成数据集,以补充现有基准数据集。2) 数据过滤:采用多种策略过滤噪声数据,提高数据质量。3) 负样本挖掘:设计有效的负样本挖掘方法,增强模型的区分能力。4) 模型训练:使用同构任务排序和混合任务微调策略,优化模型参数。5) 模型评估:采用4位精度和轻量级检索评估集,加速模型验证。
关键创新:Linq-Embed-Mistral的关键创新在于其先进的数据精炼方法,包括针对特定任务的数据制作、数据过滤和负样本挖掘。此外,同构任务排序和混合任务微调策略也是提升模型泛化能力的重要创新。
关键设计:在数据制作方面,使用LLM生成与特定任务相关的合成数据,并进行人工校对。在数据过滤方面,采用基于规则和基于模型的过滤策略。在负样本挖掘方面,设计了多种负采样策略,包括hard negative sampling和random negative sampling。在模型训练方面,采用了AdamW优化器,并设置了合适的学习率和权重衰减系数。损失函数使用了InfoNCE loss。
🖼️ 关键图片

📊 实验亮点
Linq-Embed-Mistral在MTEB基准测试中取得了显著的性能提升,在56个数据集上的平均得分为68.2,并在MTEB排行榜上所有检索任务模型中排名第一,性能得分为60.2。相较于其他模型,Linq-Embed-Mistral在检索精度和可靠性方面表现出明显的优势。
🎯 应用场景
Linq-Embed-Mistral可广泛应用于信息检索、问答系统、语义搜索等领域。其卓越的检索性能使其能够显著提升搜索精度和用户体验。该研究成果对于构建更智能、更高效的文本检索系统具有重要意义,并有望推动相关技术在实际应用中的发展。
📄 摘要(原文)
This report explores the enhancement of text retrieval performance using advanced data refinement techniques. We develop Linq-Embed-Mistral\footnote{\url{https://huggingface.co/Linq-AI-Research/Linq-Embed-Mistral}} by building on the E5-mistral and Mistral-7B-v0.1 models, focusing on sophisticated data crafting, data filtering, and negative mining methods, which are highly tailored to each task, applied to both existing benchmark dataset and highly tailored synthetic dataset generated via large language models (LLMs). Linq-Embed-Mistral excels in the MTEB benchmarks (as of May 29, 2024), achieving an average score of 68.2 across 56 datasets, and ranks 1st among all models for retrieval tasks on the MTEB leaderboard with a performance score of 60.2. This performance underscores its superior capability in enhancing search precision and reliability. Our contributions include advanced data refinement methods that significantly improve model performance on benchmark and synthetic datasets, techniques for homogeneous task ordering and mixed task fine-tuning to enhance model generalization and stability, and a streamlined evaluation process using 4-bit precision and a light retrieval evaluation set, which accelerates validation without sacrificing accuracy.