U-MATH: A University-Level Benchmark for Evaluating Mathematical Skills in LLMs
作者: Konstantin Chernyshev, Vitaliy Polshkov, Ekaterina Artemova, Alex Myasnikov, Vlad Stepanov, Alexei Miasnikov, Sergei Tilga
分类: cs.CL, cs.AI
发布日期: 2024-12-04 (更新: 2025-01-14)
💡 一句话要点
提出U-MATH:一个用于评估LLM数学能力的大学水平基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM 数学能力评估 大学水平基准 多模态学习 μ-MATH数据集
📋 核心要点
- 现有数学基准测试规模小,难度集中于中小学水平,缺乏主题多样性,且对视觉元素的考察不足。
- 论文提出U-MATH基准,包含大学水平的开放式数学题,覆盖多个学科,并包含多模态题目。
- 实验表明,现有LLM在U-MATH基准上表现不佳,尤其是在视觉题目和解决方案评估方面。
📝 摘要(中文)
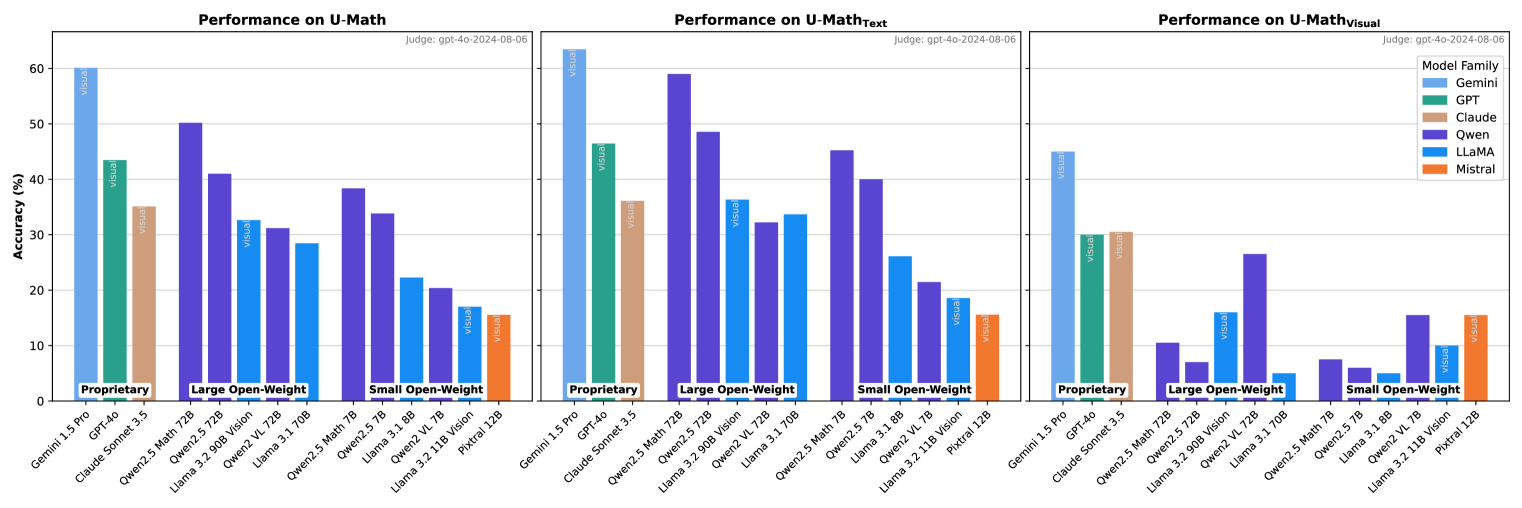
现有的LLM数学能力评估存在局限性,例如数据集规模较小、主要关注中小学问题、主题缺乏多样性,以及对包含视觉元素的任务探索不足。为了解决这些问题,我们提出了U-MATH,一个包含1100个未公开的大学水平开放式问题的基准,这些问题来源于教学材料。U-MATH在六个核心科目上实现了平衡,其中20%的问题是多模态的。由于U-MATH问题的开放性,我们使用LLM来判断生成解决方案的正确性。为此,我们发布了μ-MATH数据集,用于评估LLM在判断解决方案方面的能力。对通用领域、数学专用和多模态LLM的评估突显了U-MATH带来的挑战。我们的研究结果表明,LLM在基于文本的任务上最高准确率仅为63%,在视觉问题上甚至更低,仅为45%。解决方案评估对LLM来说也具有挑战性,最佳LLM裁判在μ-MATH上的F1得分为80%。
🔬 方法详解
问题定义:论文旨在解决现有LLM数学能力评估基准的不足。现有基准主要存在以下痛点:一是难度较低,集中在中小学水平;二是缺乏主题多样性,不能全面评估LLM的数学能力;三是忽略了视觉信息在数学问题中的作用,缺乏对多模态数学问题的评估。
核心思路:论文的核心思路是构建一个更具挑战性和综合性的大学水平数学基准U-MATH,以更全面地评估LLM的数学能力。该基准不仅包含难度更高的数学问题,还覆盖了多个数学学科,并引入了多模态数学问题,从而更真实地反映了LLM在解决实际数学问题时的能力。
技术框架:U-MATH基准包含1100个大学水平的开放式数学问题,这些问题来源于教学材料,涵盖六个核心科目。其中20%的问题是多模态的,包含视觉元素。为了评估LLM生成解决方案的正确性,论文还发布了μ-MATH数据集,用于训练和评估LLM作为裁判的能力。整体流程包括:1) 构建U-MATH基准;2) 使用LLM生成解决方案;3) 使用LLM裁判评估解决方案的正确性;4) 分析LLM在不同类型问题上的表现。
关键创新:论文的关键创新在于构建了一个大学水平的数学基准U-MATH,该基准具有以下特点:一是难度更高,更具挑战性;二是覆盖面更广,包含多个数学学科;三是引入了多模态问题,更贴近实际应用。此外,论文还提出了使用LLM作为裁判来评估解决方案的正确性,这是一种新的评估方法。
关键设计:U-MATH基准在问题选择上,力求覆盖大学数学的核心科目,并保证难度适中。多模态问题的设计,旨在考察LLM对视觉信息的理解和推理能力。μ-MATH数据集的构建,旨在训练一个可靠的LLM裁判,用于评估LLM生成解决方案的质量。具体参数设置和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有LLM在U-MATH基准上的表现远低于人类水平,在文本任务上的最高准确率仅为63%,在视觉任务上更低至45%。即使是最好的LLM裁判,在μ-MATH数据集上的F1得分也仅为80%。这些结果表明,LLM在解决大学水平的数学问题方面仍面临巨大挑战,需要进一步的研究和改进。
🎯 应用场景
该研究成果可应用于LLM的数学能力评测、数学教育辅助工具开发、以及提升LLM在科学计算领域的应用能力。U-MATH基准的发布,将促进LLM在数学领域的进一步研究和发展,并推动LLM在实际数学问题解决中的应用。
📄 摘要(原文)
The current evaluation of mathematical skills in LLMs is limited, as existing benchmarks are either relatively small, primarily focus on elementary and high-school problems, or lack diversity in topics. Additionally, the inclusion of visual elements in tasks remains largely under-explored. To address these gaps, we introduce U-MATH, a novel benchmark of 1,100 unpublished open-ended university-level problems sourced from teaching materials. It is balanced across six core subjects, with 20% of multimodal problems. Given the open-ended nature of U-MATH problems, we employ an LLM to judge the correctness of generated solutions. To this end, we release $μ$-MATH, a dataset to evaluate the LLMs' capabilities in judging solutions. The evaluation of general domain, math-specific, and multimodal LLMs highlights the challenges presented by U-MATH. Our findings reveal that LLMs achieve a maximum accuracy of only 63% on text-based tasks, with even lower 45% on visual problems. The solution assessment proves challenging for LLMs, with the best LLM judge having an F1-score of 80% on $μ$-MATH.