ASR-EC Benchmark: Evaluating Large Language Models on Chinese ASR Error Correction
作者: Victor Junqiu Wei, Weicheng Wang, Di Jiang, Yuanfeng Song, Lu Wang
分类: cs.CL, cs.SD, eess.AS
发布日期: 2024-12-04
💡 一句话要点
提出 ASR-EC 基准数据集,评估大语言模型在中文语音识别纠错中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音识别 错误纠正 大语言模型 中文ASR 多模态融合
📋 核心要点
- 现有 ASR 系统在噪声和歧义环境下仍存在大量识别错误,中文 ASR 纠错缺乏统一的评测基准。
- 利用大语言模型,探索提示学习、微调和多模态融合三种范式,提升中文 ASR 纠错性能。
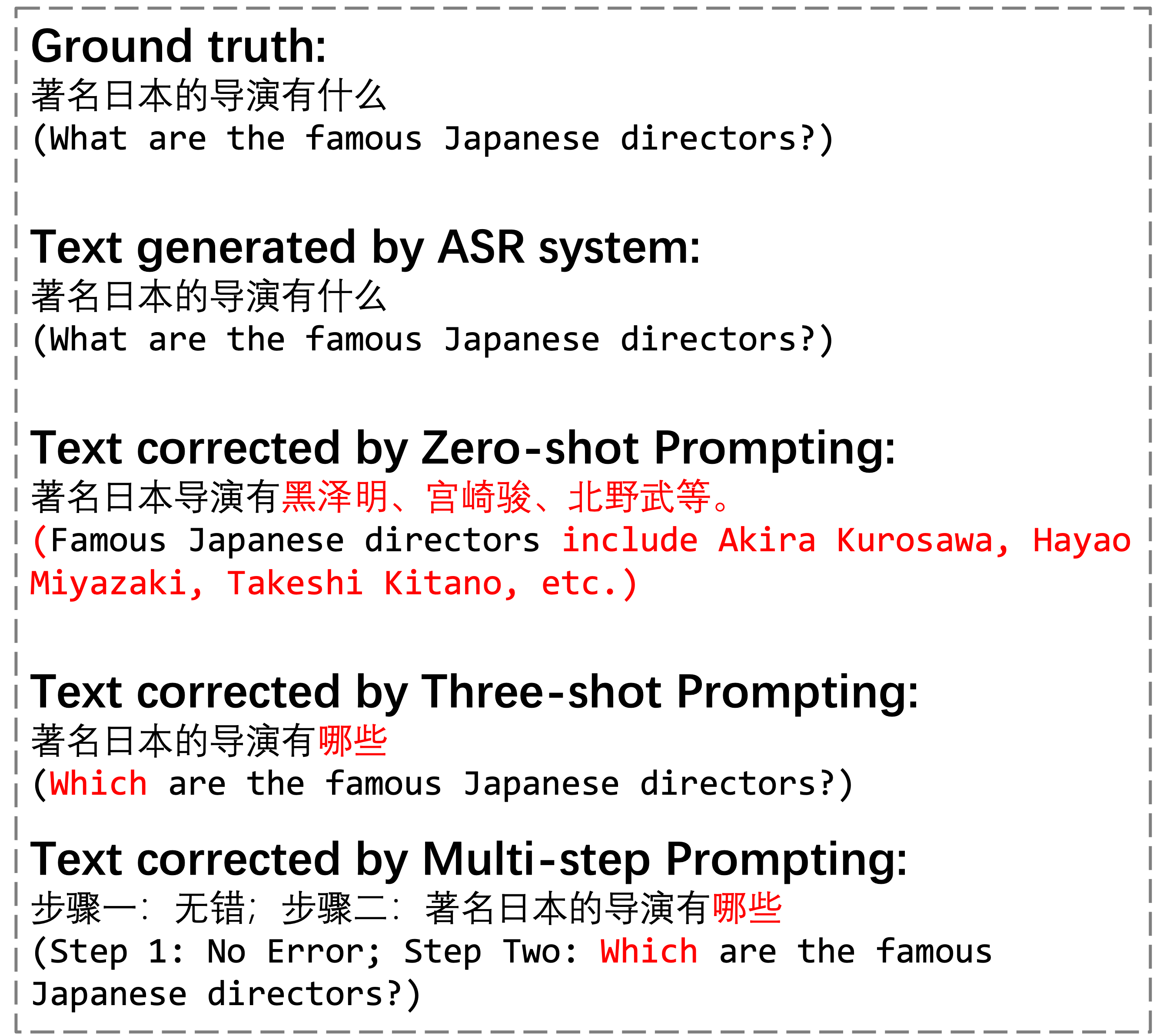
- 实验表明,多模态融合方法效果最佳,优于提示学习和微调,并在 ASR 纠错任务上取得领先性能。
📝 摘要(中文)
本文研究中文语音识别(ASR)的错误纠正问题,鉴于中文是世界上最流行的语言之一,拥有大量用户。我们首先创建了一个名为 ASR-EC 的基准数据集,其中包含由工业级 ASR 系统生成的各种 ASR 错误。据我们所知,这是第一个中文 ASR 错误纠正基准。然后,受到大语言模型(LLM)最新进展的启发,我们研究如何利用 LLM 的能力来纠正 ASR 错误。我们将 LLM 应用于三种范式:提示学习(包括零样本、少样本和多步提示),微调(使用 ASR 错误纠正数据微调 LLM)和多模态增强(同时利用音频和 ASR 文本进行错误纠正)。大量实验表明,提示学习对于 ASR 错误纠正效果不佳,微调仅对部分 LLM 有效,而多模态增强是纠正错误的最有效方法,并实现了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决中文语音识别中存在的错误纠正问题。现有的 ASR 系统,即使是工业级的,仍然会受到环境噪声、口音差异、以及语言本身歧义性的影响,导致识别结果出现错误。缺乏专门针对中文 ASR 错误纠正的基准数据集,使得研究人员难以系统地评估和比较不同的纠错方法。
核心思路:论文的核心思路是利用近年来在大语言模型(LLM)领域取得的进展,探索 LLM 在中文 ASR 错误纠正任务中的潜力。通过不同的范式,包括提示学习、微调和多模态增强,来评估 LLM 在纠正 ASR 错误方面的能力。这样设计的目的是为了充分利用 LLM 的语言理解和生成能力,从而提高 ASR 系统的鲁棒性和准确性。
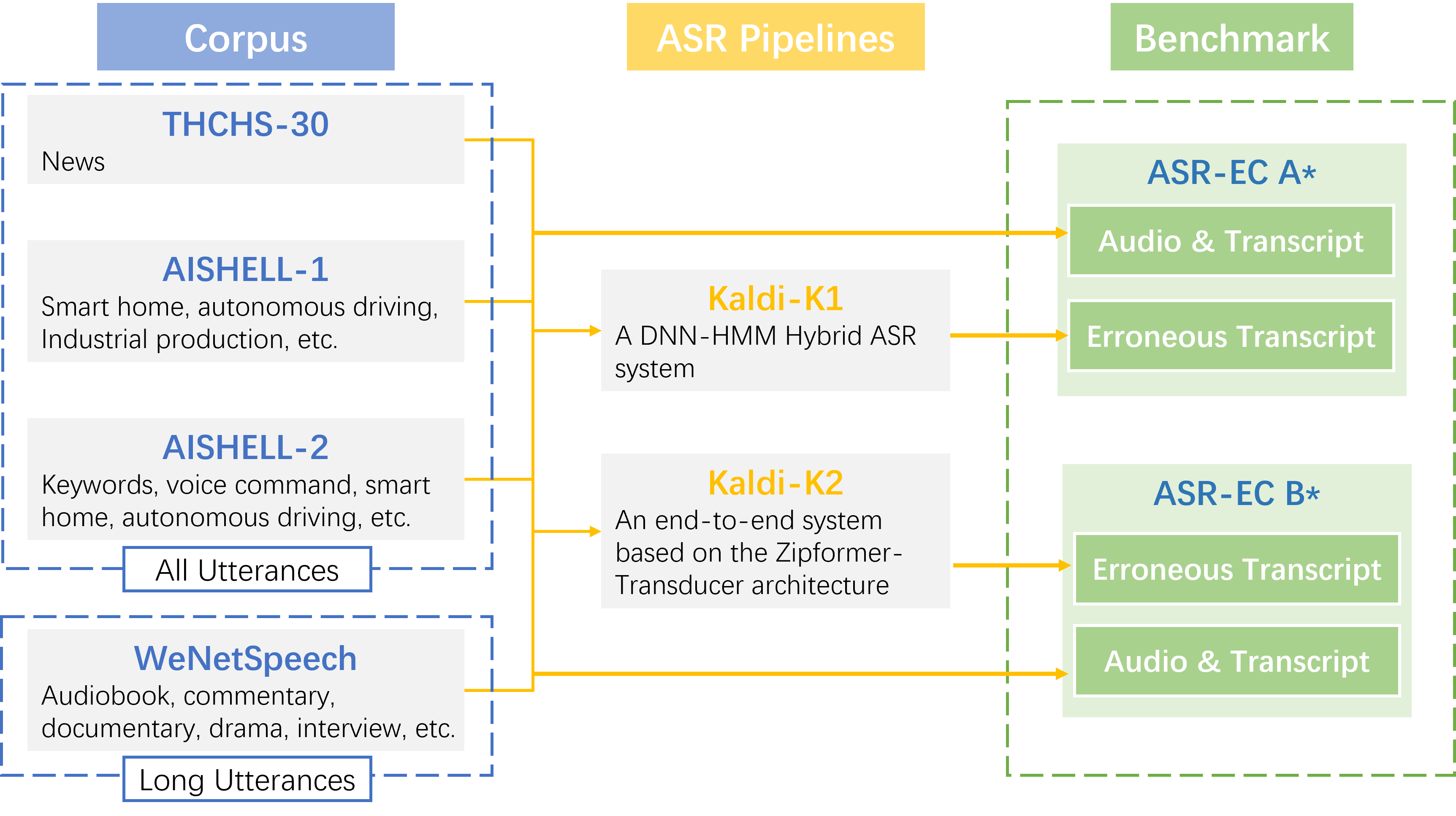
技术框架:论文的技术框架主要包括三个部分:1) ASR-EC 基准数据集的构建;2) 基于 LLM 的 ASR 错误纠正方法,包括提示学习、微调和多模态增强;3) 实验评估和结果分析。其中,提示学习包括零样本、少样本和多步提示;微调使用 ASR 错误纠正数据对 LLM 进行训练;多模态增强则同时利用音频和 ASR 文本信息。
关键创新:论文的关键创新在于:1) 构建了首个中文 ASR 错误纠正基准数据集 ASR-EC,为该领域的研究提供了标准化的评估平台;2) 系统地研究了 LLM 在中文 ASR 错误纠正中的应用,并探索了不同的范式,包括提示学习、微调和多模态增强;3) 提出了多模态增强方法,该方法结合了音频和文本信息,取得了 state-of-the-art 的性能。
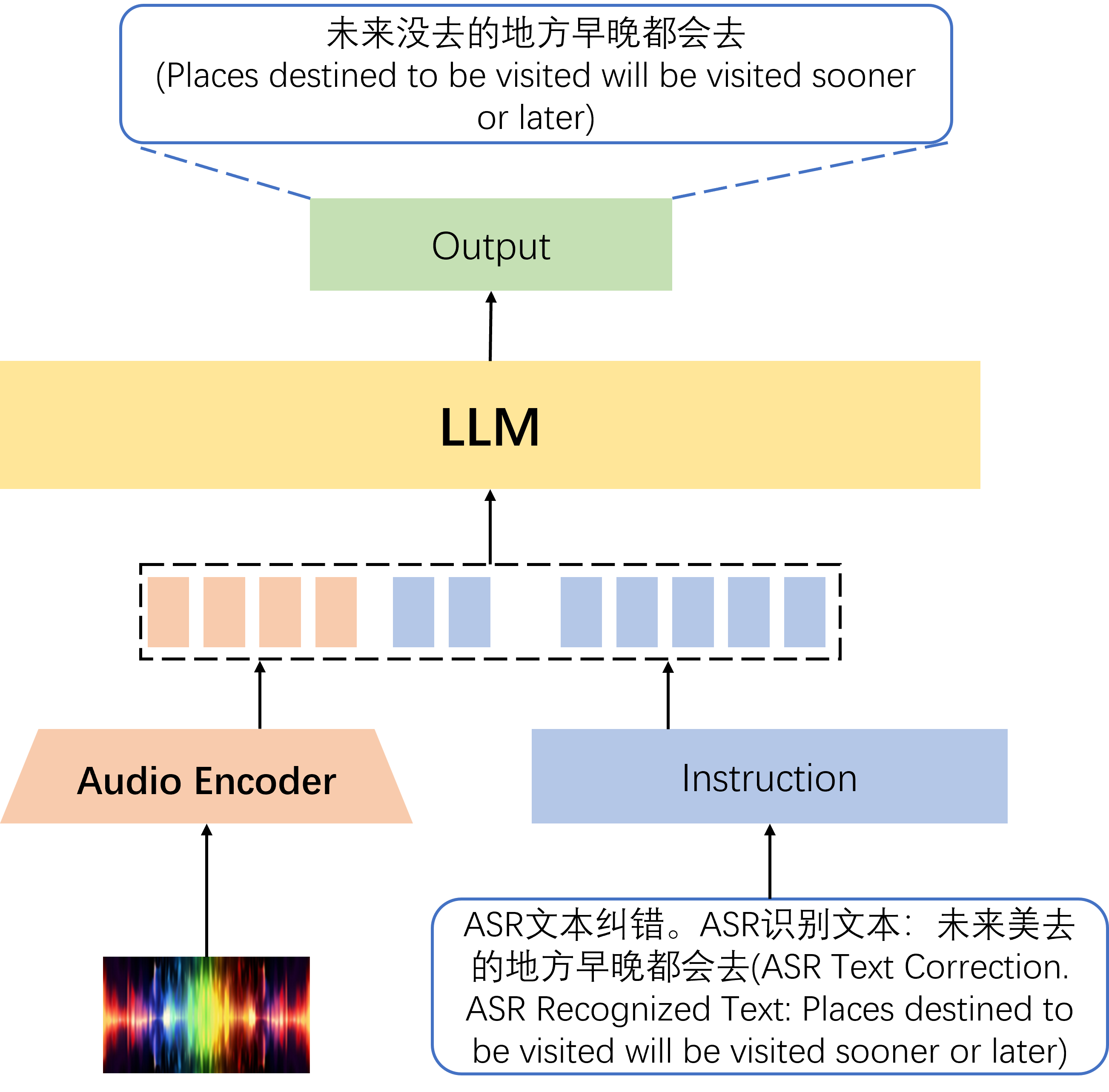
关键设计:在多模态增强方法中,一个关键的设计是有效地融合音频和文本信息。具体的技术细节未知,但可以推测可能使用了注意力机制或其他融合策略,以便 LLM 能够同时利用音频特征和 ASR 文本信息进行错误纠正。此外,在微调过程中,损失函数的选择和超参数的调整也是关键的设计因素,需要根据具体的 LLM 和数据集进行优化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,多模态增强方法在 ASR 错误纠正任务上取得了最佳性能,显著优于提示学习和微调方法。具体的性能提升幅度未知,但论文强调该方法实现了 state-of-the-art 的结果,表明其在中文 ASR 错误纠正方面具有显著优势。
🎯 应用场景
该研究成果可应用于语音助手、语音翻译、智能客服等多个领域,提升用户体验。通过提高语音识别的准确率,可以减少人工干预,降低运营成本。未来,该技术有望在智能家居、车载系统等场景中得到广泛应用,实现更自然、便捷的人机交互。
📄 摘要(原文)
Automatic speech Recognition (ASR) is a fundamental and important task in the field of speech and natural language processing. It is an inherent building block in many applications such as voice assistant, speech translation, etc. Despite the advancement of ASR technologies in recent years, it is still inevitable for modern ASR systems to have a substantial number of erroneous recognition due to environmental noise, ambiguity, etc. Therefore, the error correction in ASR is crucial. Motivated by this, this paper studies ASR error correction in the Chinese language, which is one of the most popular languages and enjoys a large number of users in the world. We first create a benchmark dataset named \emph{ASR-EC} that contains a wide spectrum of ASR errors generated by industry-grade ASR systems. To the best of our knowledge, it is the first Chinese ASR error correction benchmark. Then, inspired by the recent advances in \emph{large language models (LLMs)}, we investigate how to harness the power of LLMs to correct ASR errors. We apply LLMs to ASR error correction in three paradigms. The first paradigm is prompting, which is further categorized as zero-shot, few-shot, and multi-step. The second paradigm is finetuning, which finetunes LLMs with ASR error correction data. The third paradigm is multi-modal augmentation, which collectively utilizes the audio and ASR transcripts for error correction. Extensive experiments reveal that prompting is not effective for ASR error correction. Finetuning is effective only for a portion of LLMs. Multi-modal augmentation is the most effective method for error correction and achieves state-of-the-art performance.