Human Variability vs. Machine Consistency: A Linguistic Analysis of Texts Generated by Humans and Large Language Models
作者: Sergio E. Zanotto, Segun Aroyehun
分类: cs.CL
发布日期: 2024-12-04
💡 一句话要点
通过语言特征分析,揭示人类文本与大语言模型生成文本的差异性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言特征分析 大型语言模型 文本生成 人机差异 变异性分析
📋 核心要点
- 现有方法侧重于用LLM区分人类文本和机器生成文本,忽略了深层语言特征的差异性分析。
- 本研究通过分析250种语言特征,揭示人类文本与LLM生成文本在变异性、语义和情感上的差异。
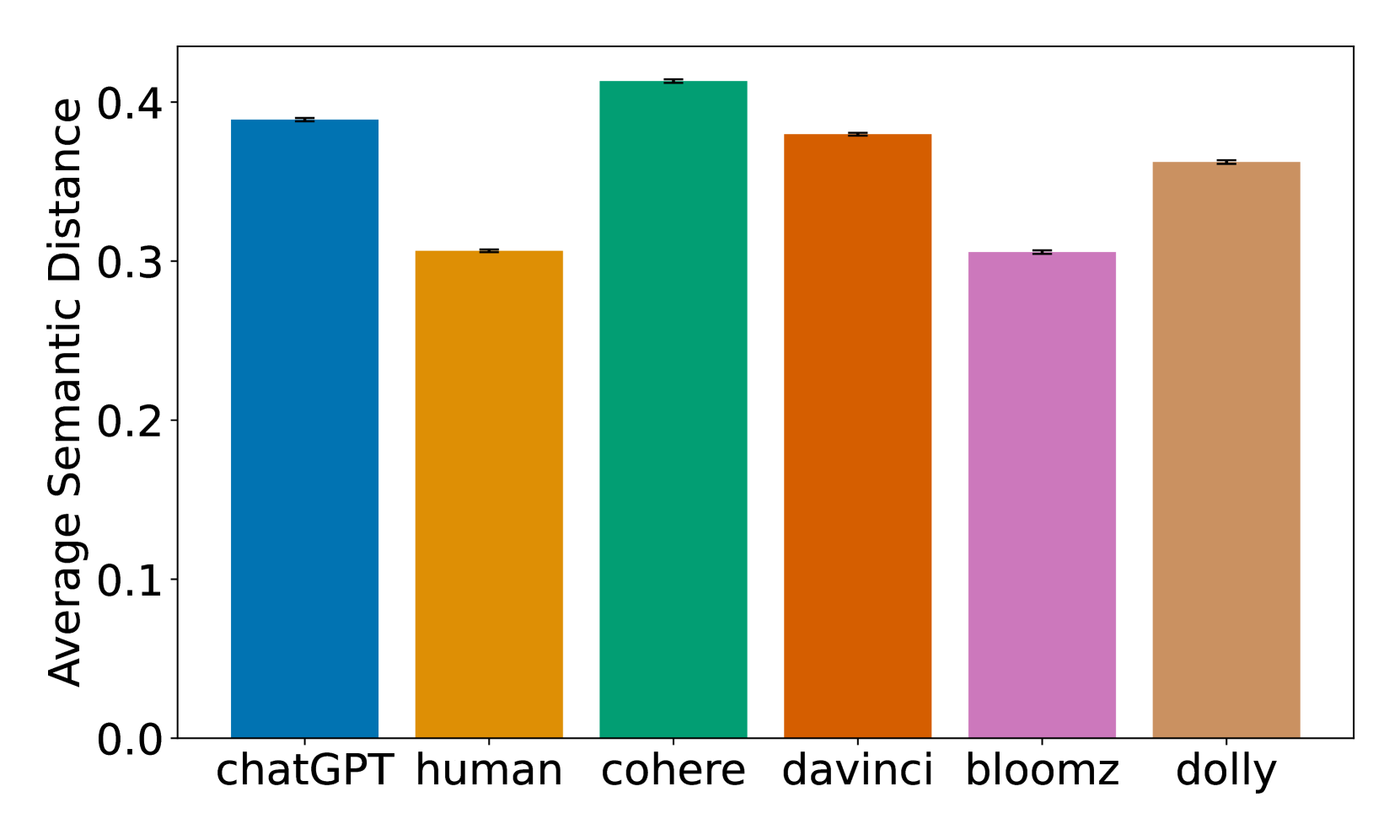
- 实验表明,人类文本在变异性上显著高于LLM生成文本,尤其在风格约束较少的文本中更为明显。
📝 摘要(中文)
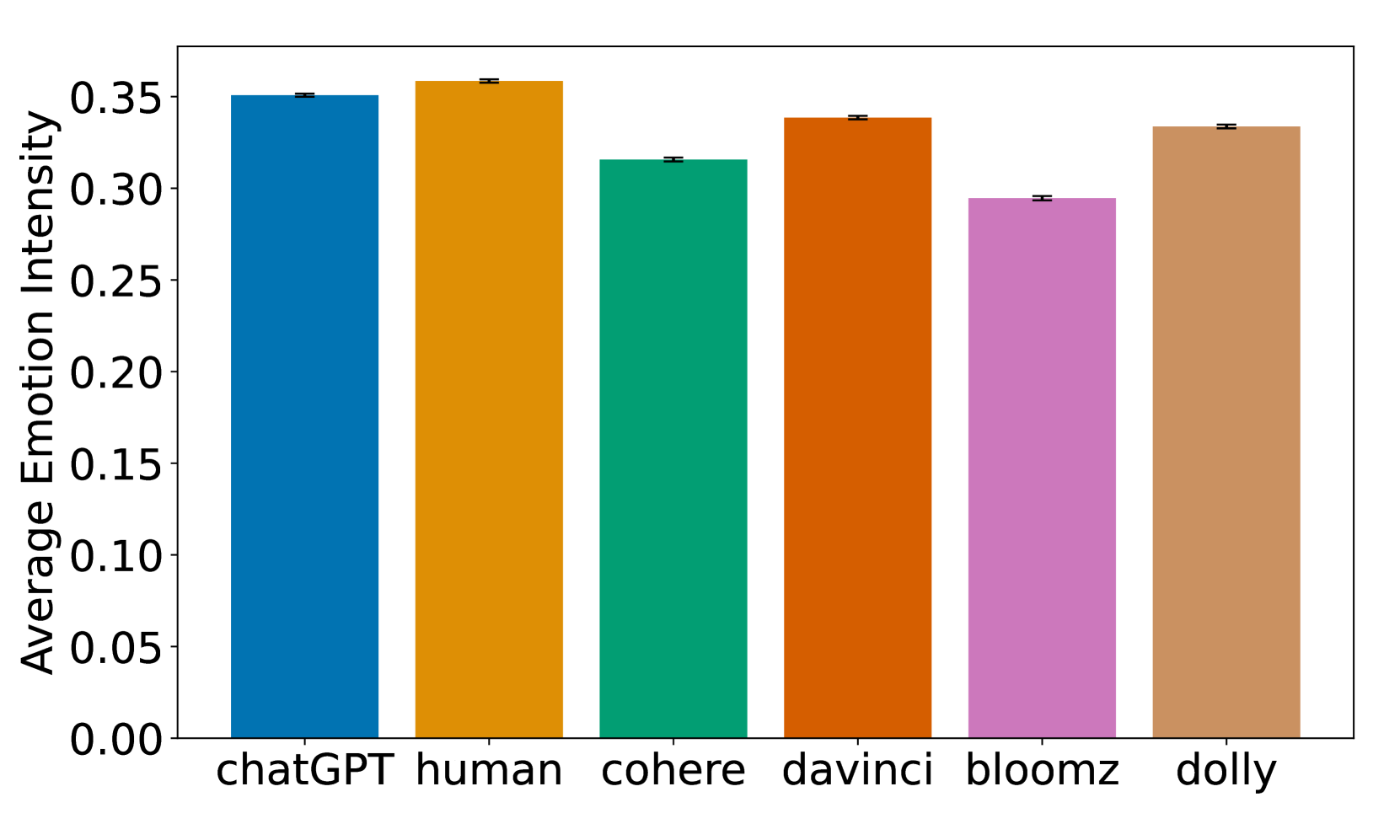
大型语言模型(LLM)的快速发展显著提高了其生成自然语言的能力,使得LLM生成的文本越来越难以与人类撰写的文本区分。目前的研究主要集中在使用LLM将文本分类为人写或机器生成。本研究采用不同的方法,基于250个不同的语言特征对跨越四个领域的文本进行分析。我们选择了SemEval 2024 Task 8的Subtask B中的M4数据集。我们使用LFTK工具自动计算各种语言特征,并测量每个文档的平均句法深度、语义相似度和情感内容。然后,我们对所有计算的特征应用二维PCA降维。我们的分析揭示了人类撰写的文本与LLM生成的文本之间的显著差异,特别是在这些特征的变异性方面,我们发现人类撰写的文本的变异性要高得多。这种差异在语言风格约束较少的文本类型中尤为明显。我们的研究结果表明,与LLM生成的文本相比,人类撰写的文本认知需求更低,语义内容更高,情感内容更丰富。这些见解强调了需要结合有意义的语言特征来增强对LLM文本输出的理解。
🔬 方法详解
问题定义:论文旨在解决如何有效区分人类撰写文本和大型语言模型(LLM)生成文本的问题。现有方法主要集中于使用LLM进行分类,缺乏对文本深层语言特征差异的深入分析,难以充分理解LLM的文本生成特性。现有方法的痛点在于区分能力有限,且缺乏对差异性成因的解释。
核心思路:论文的核心思路是通过提取和分析大量语言特征,量化人类文本和LLM生成文本之间的差异。重点关注文本的变异性、句法深度、语义相似度和情感内容等维度,从而揭示LLM在模拟人类写作风格方面的局限性。通过分析这些差异,可以更好地理解LLM的文本生成机制,并为改进LLM的文本生成能力提供指导。
技术框架:整体流程包括:1) 数据集选择(SemEval 2024 Task 8的M4数据集);2) 语言特征提取(使用LFTK工具自动计算250种语言特征,并计算句法深度、语义相似度和情感内容);3) 特征降维(使用二维PCA降维);4) 差异性分析(比较人类文本和LLM生成文本在降维后的特征空间中的分布)。
关键创新:论文的关键创新在于:1) 采用了一种基于语言特征分析的差异性分析方法,而非传统的分类方法;2) 关注文本的变异性,发现人类文本在变异性方面显著高于LLM生成文本;3) 综合考虑了句法、语义和情感等多个维度的语言特征。与现有方法的本质区别在于,本研究侧重于理解差异的成因,而非仅仅进行分类。
关键设计:论文使用了LFTK工具进行语言特征提取,并计算了平均句法深度、语义相似度和情感内容。使用PCA进行降维,以便于可视化和分析。具体参数设置和损失函数未提及,网络结构也未涉及,因为本研究主要关注特征分析而非模型训练。
🖼️ 关键图片

📊 实验亮点
实验结果表明,人类撰写的文本在语言特征的变异性方面显著高于LLM生成的文本,尤其是在语言风格约束较少的文本类型中。此外,研究还发现,与LLM生成的文本相比,人类撰写的文本认知需求更低,语义内容更高,情感内容更丰富。具体的性能数据和提升幅度未在摘要中明确给出。
🎯 应用场景
该研究成果可应用于检测LLM生成的虚假信息、评估LLM的文本生成质量、改进LLM的文本生成算法,以及提升人机交互的自然性。通过理解人类文本与机器生成文本的差异,可以更好地利用LLM辅助写作,并防范其潜在风险。
📄 摘要(原文)
The rapid advancements in large language models (LLMs) have significantly improved their ability to generate natural language, making texts generated by LLMs increasingly indistinguishable from human-written texts. Recent research has predominantly focused on using LLMs to classify text as either human-written or machine-generated. In our study, we adopt a different approach by profiling texts spanning four domains based on 250 distinct linguistic features. We select the M4 dataset from the Subtask B of SemEval 2024 Task 8. We automatically calculate various linguistic features with the LFTK tool and additionally measure the average syntactic depth, semantic similarity, and emotional content for each document. We then apply a two-dimensional PCA reduction to all the calculated features. Our analyses reveal significant differences between human-written texts and those generated by LLMs, particularly in the variability of these features, which we find to be considerably higher in human-written texts. This discrepancy is especially evident in text genres with less rigid linguistic style constraints. Our findings indicate that humans write texts that are less cognitively demanding, with higher semantic content, and richer emotional content compared to texts generated by LLMs. These insights underscore the need for incorporating meaningful linguistic features to enhance the understanding of textual outputs of LLMs.